 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
Dec 29, 2025Transparent objects remain notoriously hard for perception systems: refraction, reflection and transmission break the assumptions behind stereo, ToF and purely discriminative monocular depth, causing holes and temporally unstable estimates. Our key observation is that modern video diffusion models already synthesize convincing transparent phenomena, suggesting they have internalized the optical rules. We build TransPhy3D, a synthetic video corpus of transparent/reflective scenes: 11k sequences rendered with Blender/Cycles. Scenes are assembled from a curated bank of category-rich static assets and shape-rich procedural assets paired with glass/plastic/metal materials. We render RGB + depth + normals with physically based ray tracing and OptiX denoising. Starting from a large video diffusion model, we learn a video-to-video translator for depth (and normals) via lightweight LoRA adapters. During training we concatenate RGB and (noisy) depth latents in the DiT backbone and co-train on TransPhy3D and existing frame-wise synthetic datasets, yielding temporally consistent predictions for arbitrary-length input videos. The resulting model, DKT, achieves zero-shot SOTA on real and synthetic video benchmarks involving transparency: ClearPose, DREDS (CatKnown/CatNovel), and TransPhy3D-Test. It improves accuracy and temporal consistency over strong image/video baselines, and a normal variant sets the best video normal estimation results on ClearPose. A compact 1.3B version runs at ~0.17 s/frame. Integrated into a grasping stack, DKT's depth boosts success rates across translucent, reflective and diffuse surfaces, outperforming prior estimators. Together, these results support a broader claim: "Diffusion knows transparency." Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation.
Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
Dec 03, 2024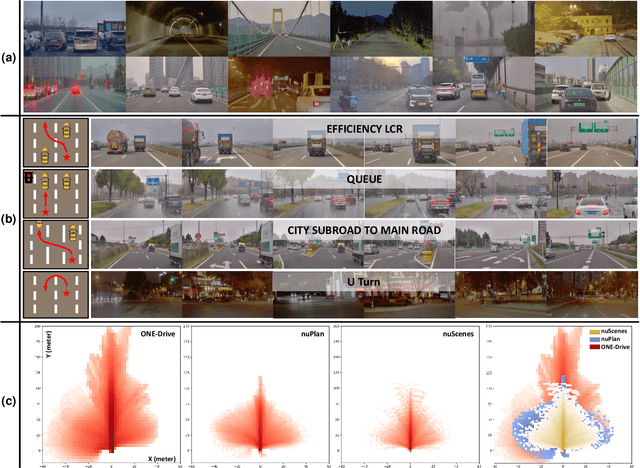
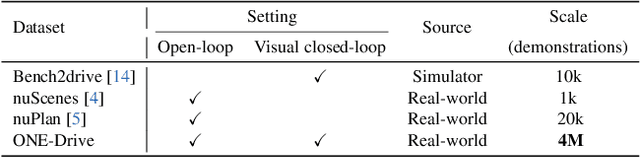

The end-to-end autonomous driving paradigm has recently attracted lots of attention due to its scalability. However, existing methods are constrained by the limited scale of real-world data, which hinders a comprehensive exploration of the scaling laws associated with end-to-end autonomous driving. To address this issue, we collected substantial data from various driving scenarios and behaviors and conducted an extensive study on the scaling laws of existing imitation learning-based end-to-end autonomous driving paradigms. Specifically, approximately 4 million demonstrations from 23 different scenario types were gathered, amounting to over 30,000 hours of driving demonstrations. We performed open-loop evaluations and closed-loop simulation evaluations in 1,400 diverse driving demonstrations (1,300 for open-loop and 100 for closed-loop) under stringent assessment conditions. Through experimental analysis, we discovered that (1) the performance of the driving model exhibits a power-law relationship with the amount of training data; (2) a small increase in the quantity of long-tailed data can significantly improve the performance for the corresponding scenarios; (3) appropriate scaling of data enables the model to achieve combinatorial generalization in novel scenes and actions. Our results highlight the critical role of data scaling in improving the generalizability of models across diverse autonomous driving scenarios, assuring safe deployment in the real world. Project repository: https://github.com/ucaszyp/Driving-Scaling-Law
PlanAgent: A Multi-modal Large Language Agent for Closed-loop Vehicle Motion Planning
Jun 04, 2024



Vehicle motion planning is an essential component of autonomous driving technology. Current rule-based vehicle motion planning methods perform satisfactorily in common scenarios but struggle to generalize to long-tailed situations. Meanwhile, learning-based methods have yet to achieve superior performance over rule-based approaches in large-scale closed-loop scenarios. To address these issues, we propose PlanAgent, the first mid-to-mid planning system based on a Multi-modal Large Language Model (MLLM). MLLM is used as a cognitive agent to introduce human-like knowledge, interpretability, and common-sense reasoning into the closed-loop planning. Specifically, PlanAgent leverages the power of MLLM through three core modules. First, an Environment Transformation module constructs a Bird's Eye View (BEV) map and a lane-graph-based textual description from the environment as inputs. Second, a Reasoning Engine module introduces a hierarchical chain-of-thought from scene understanding to lateral and longitudinal motion instructions, culminating in planner code generation. Last, a Reflection module is integrated to simulate and evaluate the generated planner for reducing MLLM's uncertainty. PlanAgent is endowed with the common-sense reasoning and generalization capability of MLLM, which empowers it to effectively tackle both common and complex long-tailed scenarios. Our proposed PlanAgent is evaluated on the large-scale and challenging nuPlan benchmarks. A comprehensive set of experiments convincingly demonstrates that PlanAgent outperforms the existing state-of-the-art in the closed-loop motion planning task. Codes will be soon released.
TOD3Cap: Towards 3D Dense Captioning in Outdoor Scenes
Mar 28, 2024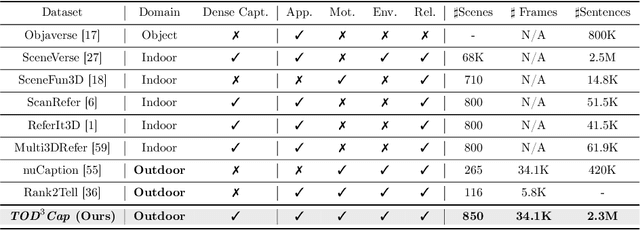
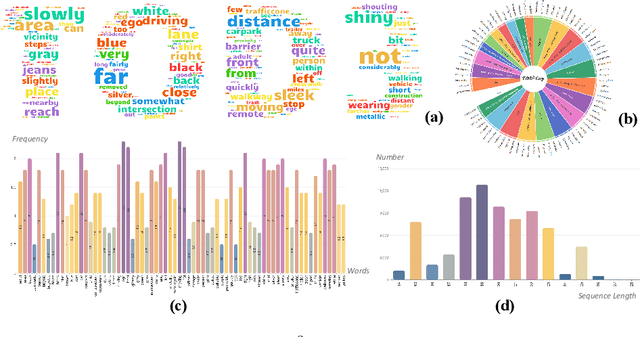

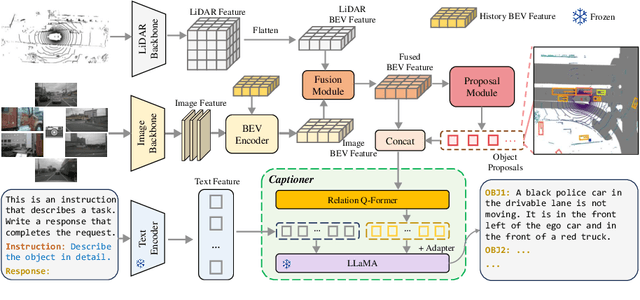
3D dense captioning stands as a cornerstone in achieving a comprehensive understanding of 3D scenes through natural language. It has recently witnessed remarkable achievements, particularly in indoor settings. However, the exploration of 3D dense captioning in outdoor scenes is hindered by two major challenges: 1) the \textbf{domain gap} between indoor and outdoor scenes, such as dynamics and sparse visual inputs, makes it difficult to directly adapt existing indoor methods; 2) the \textbf{lack of data} with comprehensive box-caption pair annotations specifically tailored for outdoor scenes. To this end, we introduce the new task of outdoor 3D dense captioning. As input, we assume a LiDAR point cloud and a set of RGB images captured by the panoramic camera rig. The expected output is a set of object boxes with captions. To tackle this task, we propose the TOD3Cap network, which leverages the BEV representation to generate object box proposals and integrates Relation Q-Former with LLaMA-Adapter to generate rich captions for these objects. We also introduce the TOD3Cap dataset, the largest one to our knowledge for 3D dense captioning in outdoor scenes, which contains 2.3M descriptions of 64.3K outdoor objects from 850 scenes. Notably, our TOD3Cap network can effectively localize and caption 3D objects in outdoor scenes, which outperforms baseline methods by a significant margin (+9.6 CiDEr@0.5IoU). Code, data, and models are publicly available at https://github.com/jxbbb/TOD3Cap.
GaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024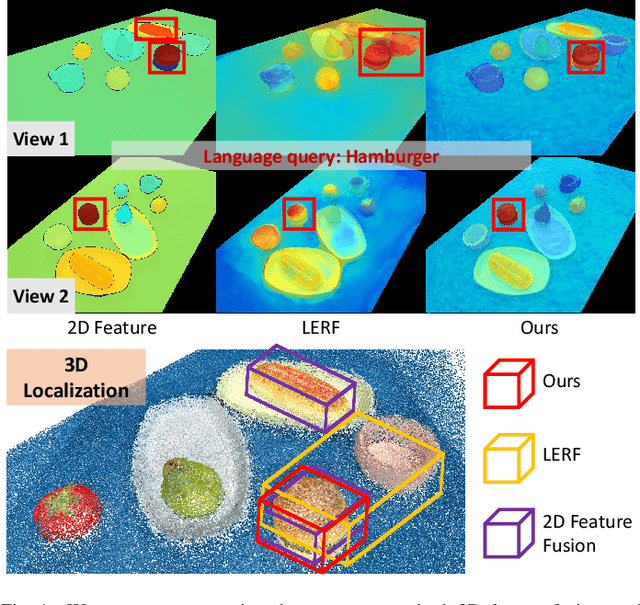
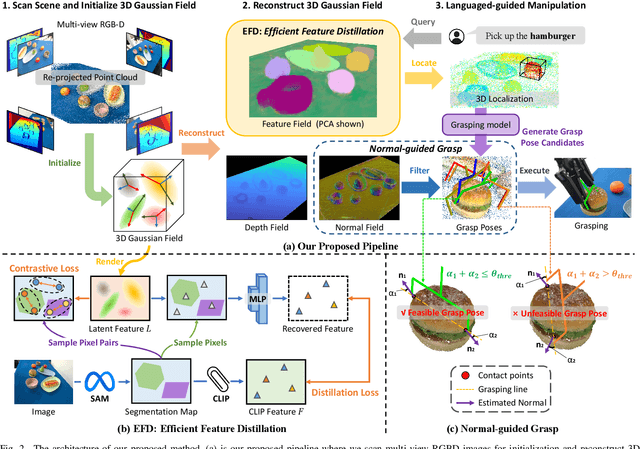

Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.
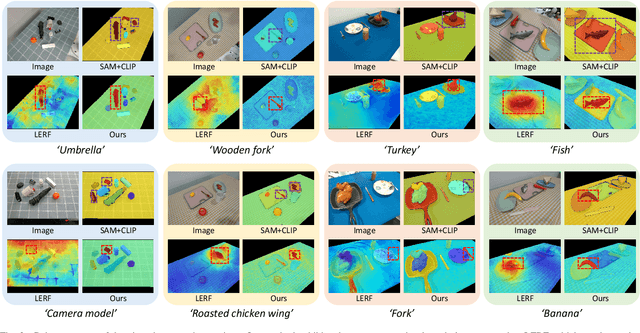
MonoOcc: Digging into Monocular Semantic Occupancy Prediction
Mar 13, 2024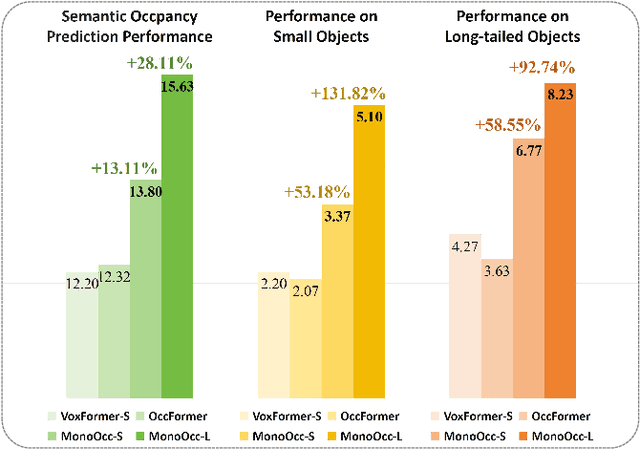
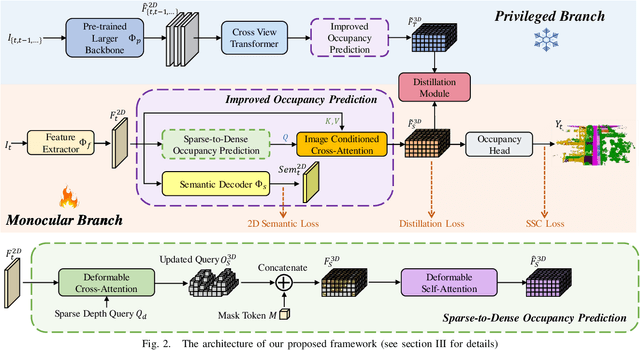
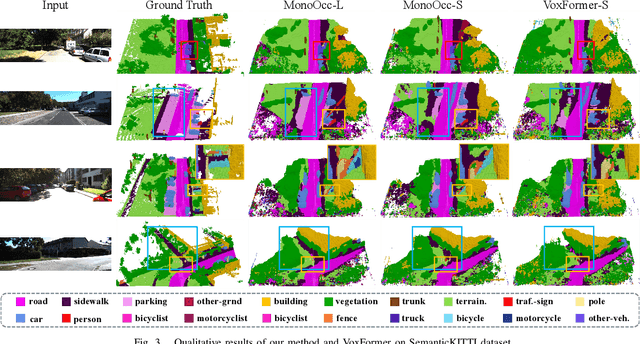
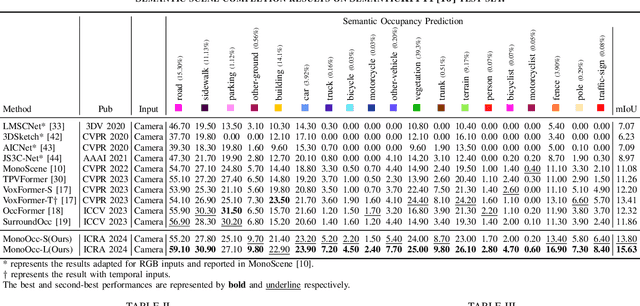
Monocular Semantic Occupancy Prediction aims to infer the complete 3D geometry and semantic information of scenes from only 2D images. It has garnered significant attention, particularly due to its potential to enhance the 3D perception of autonomous vehicles. However, existing methods rely on a complex cascaded framework with relatively limited information to restore 3D scenes, including a dependency on supervision solely on the whole network's output, single-frame input, and the utilization of a small backbone. These challenges, in turn, hinder the optimization of the framework and yield inferior prediction results, particularly concerning smaller and long-tailed objects. To address these issues, we propose MonoOcc. In particular, we (i) improve the monocular occupancy prediction framework by proposing an auxiliary semantic loss as supervision to the shallow layers of the framework and an image-conditioned cross-attention module to refine voxel features with visual clues, and (ii) employ a distillation module that transfers temporal information and richer knowledge from a larger image backbone to the monocular semantic occupancy prediction framework with low cost of hardware. With these advantages, our method yields state-of-the-art performance on the camera-based SemanticKITTI Scene Completion benchmark. Codes and models can be accessed at https://github.com/ucaszyp/MonoOcc
Adaptive Surface Normal Constraint for Geometric Estimation from Monocular Images
Feb 08, 2024



We introduce a novel approach to learn geometries such as depth and surface normal from images while incorporating geometric context. The difficulty of reliably capturing geometric context in existing methods impedes their ability to accurately enforce the consistency between the different geometric properties, thereby leading to a bottleneck of geometric estimation quality. We therefore propose the Adaptive Surface Normal (ASN) constraint, a simple yet efficient method. Our approach extracts geometric context that encodes the geometric variations present in the input image and correlates depth estimation with geometric constraints. By dynamically determining reliable local geometry from randomly sampled candidates, we establish a surface normal constraint, where the validity of these candidates is evaluated using the geometric context. Furthermore, our normal estimation leverages the geometric context to prioritize regions that exhibit significant geometric variations, which makes the predicted normals accurately capture intricate and detailed geometric information. Through the integration of geometric context, our method unifies depth and surface normal estimations within a cohesive framework, which enables the generation of high-quality 3D geometry from images. We validate the superiority of our approach over state-of-the-art methods through extensive evaluations and comparisons on diverse indoor and outdoor datasets, showcasing its efficiency and robustness.
Improving Data Augmentation for Robust Visual Question Answering with Effective Curriculum Learning
Jan 28, 2024Being widely used in learning unbiased visual question answering (VQA) models, Data Augmentation (DA) helps mitigate language biases by generating extra training samples beyond the original samples. While today's DA methods can generate robust samples, the augmented training set, significantly larger than the original dataset, often exhibits redundancy in terms of difficulty or content repetition, leading to inefficient model training and even compromising the model performance. To this end, we design an Effective Curriculum Learning strategy ECL to enhance DA-based VQA methods. Intuitively, ECL trains VQA models on relatively ``easy'' samples first, and then gradually changes to ``harder'' samples, and less-valuable samples are dynamically removed. Compared to training on the entire augmented dataset, our ECL strategy can further enhance VQA models' performance with fewer training samples. Extensive ablations have demonstrated the effectiveness of ECL on various methods.
3D Implicit Transporter for Temporally Consistent Keypoint Discovery
Sep 10, 2023



Keypoint-based representation has proven advantageous in various visual and robotic tasks. However, the existing 2D and 3D methods for detecting keypoints mainly rely on geometric consistency to achieve spatial alignment, neglecting temporal consistency. To address this issue, the Transporter method was introduced for 2D data, which reconstructs the target frame from the source frame to incorporate both spatial and temporal information. However, the direct application of the Transporter to 3D point clouds is infeasible due to their structural differences from 2D images. Thus, we propose the first 3D version of the Transporter, which leverages hybrid 3D representation, cross attention, and implicit reconstruction. We apply this new learning system on 3D articulated objects and nonrigid animals (humans and rodents) and show that learned keypoints are spatio-temporally consistent. Additionally, we propose a closed-loop control strategy that utilizes the learned keypoints for 3D object manipulation and demonstrate its superior performance. Codes are available at https://github.com/zhongcl-thu/3D-Implicit-Transporter.