 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
Dec 29, 2025Transparent objects remain notoriously hard for perception systems: refraction, reflection and transmission break the assumptions behind stereo, ToF and purely discriminative monocular depth, causing holes and temporally unstable estimates. Our key observation is that modern video diffusion models already synthesize convincing transparent phenomena, suggesting they have internalized the optical rules. We build TransPhy3D, a synthetic video corpus of transparent/reflective scenes: 11k sequences rendered with Blender/Cycles. Scenes are assembled from a curated bank of category-rich static assets and shape-rich procedural assets paired with glass/plastic/metal materials. We render RGB + depth + normals with physically based ray tracing and OptiX denoising. Starting from a large video diffusion model, we learn a video-to-video translator for depth (and normals) via lightweight LoRA adapters. During training we concatenate RGB and (noisy) depth latents in the DiT backbone and co-train on TransPhy3D and existing frame-wise synthetic datasets, yielding temporally consistent predictions for arbitrary-length input videos. The resulting model, DKT, achieves zero-shot SOTA on real and synthetic video benchmarks involving transparency: ClearPose, DREDS (CatKnown/CatNovel), and TransPhy3D-Test. It improves accuracy and temporal consistency over strong image/video baselines, and a normal variant sets the best video normal estimation results on ClearPose. A compact 1.3B version runs at ~0.17 s/frame. Integrated into a grasping stack, DKT's depth boosts success rates across translucent, reflective and diffuse surfaces, outperforming prior estimators. Together, these results support a broader claim: "Diffusion knows transparency." Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation.
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
May 06, 2025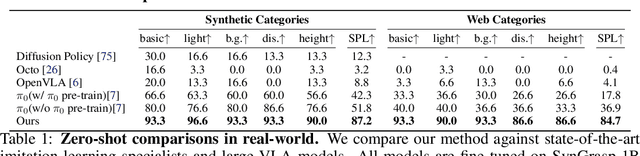



Embodied foundation models are gaining increasing attention for their zero-shot generalization, scalability, and adaptability to new tasks through few-shot post-training. However, existing models rely heavily on real-world data, which is costly and labor-intensive to collect. Synthetic data offers a cost-effective alternative, yet its potential remains largely underexplored. To bridge this gap, we explore the feasibility of training Vision-Language-Action models entirely with large-scale synthetic action data. We curate SynGrasp-1B, a billion-frame robotic grasping dataset generated in simulation with photorealistic rendering and extensive domain randomization. Building on this, we present GraspVLA, a VLA model pretrained on large-scale synthetic action data as a foundational model for grasping tasks. GraspVLA integrates autoregressive perception tasks and flow-matching-based action generation into a unified Chain-of-Thought process, enabling joint training on synthetic action data and Internet semantics data. This design helps mitigate sim-to-real gaps and facilitates the transfer of learned actions to a broader range of Internet-covered objects, achieving open-vocabulary generalization in grasping. Extensive evaluations across real-world and simulation benchmarks demonstrate GraspVLA's advanced zero-shot generalizability and few-shot adaptability to specific human preferences. We will release SynGrasp-1B dataset and pre-trained weights to benefit the community.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025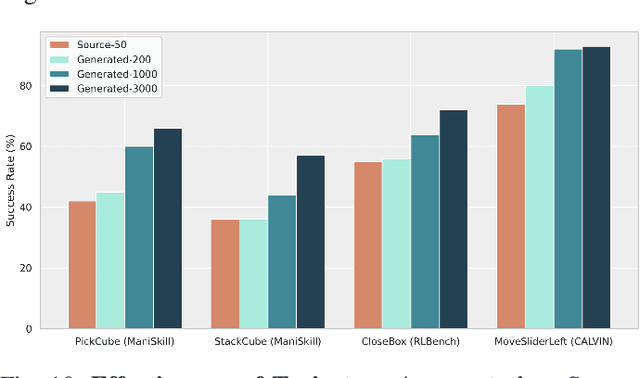



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Dec 09, 2024A practical navigation agent must be capable of handling a wide range of interaction demands, such as following instructions, searching objects, answering questions, tracking people, and more. Existing models for embodied navigation fall short of serving as practical generalists in the real world, as they are often constrained by specific task configurations or pre-defined maps with discretized waypoints. In this work, we present Uni-NaVid, the first video-based vision-language-action (VLA) model designed to unify diverse embodied navigation tasks and enable seamless navigation for mixed long-horizon tasks in unseen real-world environments. Uni-NaVid achieves this by harmonizing the input and output data configurations for all commonly used embodied navigation tasks and thereby integrating all tasks in one model. For training Uni-NaVid, we collect 3.6 million navigation data samples in total from four essential navigation sub-tasks and foster synergy in learning across them. Extensive experiments on comprehensive navigation benchmarks clearly demonstrate the advantages of unification modeling in Uni-NaVid and show it achieves state-of-the-art performance. Additionally, real-world experiments confirm the model's effectiveness and efficiency, shedding light on its strong generalizability.
RoboHanger: Learning Generalizable Robotic Hanger Insertion for Diverse Garments
Dec 02, 2024



For the task of hanging clothes, learning how to insert a hanger into a garment is crucial but has been seldom explored in robotics. In this work, we address the problem of inserting a hanger into various unseen garments that are initially laid out flat on a table. This task is challenging due to its long-horizon nature, the high degrees of freedom of the garments, and the lack of data. To simplify the learning process, we first propose breaking the task into several stages. Then, we formulate each stage as a policy learning problem and propose low-dimensional action parameterization. To overcome the challenge of limited data, we build our own simulator and create 144 synthetic clothing assets to effectively collect high-quality training data. Our approach uses single-view depth images and object masks as input, which mitigates the Sim2Real appearance gap and achieves high generalization capabilities for new garments. Extensive experiments in both simulation and the real world validate our proposed method. By training on various garments in the simulator, our method achieves a 75\% success rate with 8 different unseen garments in the real world.
GAPartManip: A Large-scale Part-centric Dataset for Material-Agnostic Articulated Object Manipulation
Nov 27, 2024Effectively manipulating articulated objects in household scenarios is a crucial step toward achieving general embodied artificial intelligence. Mainstream research in 3D vision has primarily focused on manipulation through depth perception and pose detection. However, in real-world environments, these methods often face challenges due to imperfect depth perception, such as with transparent lids and reflective handles. Moreover, they generally lack the diversity in part-based interactions required for flexible and adaptable manipulation. To address these challenges, we introduced a large-scale part-centric dataset for articulated object manipulation that features both photo-realistic material randomizations and detailed annotations of part-oriented, scene-level actionable interaction poses. We evaluated the effectiveness of our dataset by integrating it with several state-of-the-art methods for depth estimation and interaction pose prediction. Additionally, we proposed a novel modular framework that delivers superior and robust performance for generalizable articulated object manipulation. Our extensive experiments demonstrate that our dataset significantly improves the performance of depth perception and actionable interaction pose prediction in both simulation and real-world scenarios.
D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation
Sep 25, 2024



Depth sensing is an important problem for 3D vision-based robotics. Yet, a real-world active stereo or ToF depth camera often produces noisy and incomplete depth which bottlenecks robot performances. In this work, we propose D3RoMa, a learning-based depth estimation framework on stereo image pairs that predicts clean and accurate depth in diverse indoor scenes, even in the most challenging scenarios with translucent or specular surfaces where classical depth sensing completely fails. Key to our method is that we unify depth estimation and restoration into an image-to-image translation problem by predicting the disparity map with a denoising diffusion probabilistic model. At inference time, we further incorporated a left-right consistency constraint as classifier guidance to the diffusion process. Our framework combines recently advanced learning-based approaches and geometric constraints from traditional stereo vision. For model training, we create a large scene-level synthetic dataset with diverse transparent and specular objects to compensate for existing tabletop datasets. The trained model can be directly applied to real-world in-the-wild scenes and achieve state-of-the-art performance in multiple public depth estimation benchmarks. Further experiments in real environments show that accurate depth prediction significantly improves robotic manipulation in various scenarios.
SAGE: Bridging Semantic and Actionable Parts for GEneralizable Articulated-Object Manipulation under Language Instructions
Dec 03, 2023Generalizable manipulation of articulated objects remains a challenging problem in many real-world scenarios, given the diverse object structures, functionalities, and goals. In these tasks, both semantic interpretations and physical plausibilities are crucial for a policy to succeed. To address this problem, we propose SAGE, a novel framework that bridges the understanding of semantic and actionable parts of articulated objects to achieve generalizable manipulation under language instructions. Given a manipulation goal specified by natural language, an instruction interpreter with Large Language Models (LLMs) first translates them into programmatic actions on the object's semantic parts. This process also involves a scene context parser for understanding the visual inputs, which is designed to generate scene descriptions with both rich information and accurate interaction-related facts by joining the forces of generalist Visual-Language Models (VLMs) and domain-specialist part perception models. To further convert the action programs into executable policies, a part grounding module then maps the object semantic parts suggested by the instruction interpreter into so-called Generalizable Actionable Parts (GAParts). Finally, an interactive feedback module is incorporated to respond to failures, which greatly increases the robustness of the overall framework. Experiments both in simulation environments and on real robots show that our framework can handle a large variety of articulated objects with diverse language-instructed goals. We also provide a new benchmark for language-guided articulated-object manipulation in realistic scenarios.
FG-NeRF: Flow-GAN based Probabilistic Neural Radiance Field for Independence-Assumption-Free Uncertainty Estimation
Oct 04, 2023
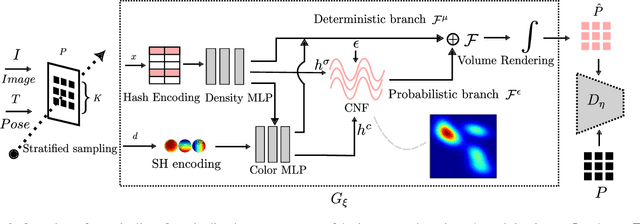


Neural radiance fields with stochasticity have garnered significant interest by enabling the sampling of plausible radiance fields and quantifying uncertainty for downstream tasks. Existing works rely on the independence assumption of points in the radiance field or the pixels in input views to obtain tractable forms of the probability density function. However, this assumption inadvertently impacts performance when dealing with intricate geometry and texture. In this work, we propose an independence-assumption-free probabilistic neural radiance field based on Flow-GAN. By combining the generative capability of adversarial learning and the powerful expressivity of normalizing flow, our method explicitly models the density-radiance distribution of the whole scene. We represent our probabilistic NeRF as a mean-shifted probabilistic residual neural model. Our model is trained without an explicit likelihood function, thereby avoiding the independence assumption. Specifically, We downsample the training images with different strides and centers to form fixed-size patches which are used to train the generator with patch-based adversarial learning. Through extensive experiments, our method demonstrates state-of-the-art performance by predicting lower rendering errors and more reliable uncertainty on both synthetic and real-world datasets.
3D Object Aided Self-Supervised Monocular Depth Estimation
Dec 04, 2022Monocular depth estimation has been actively studied in fields such as robot vision, autonomous driving, and 3D scene understanding. Given a sequence of color images, unsupervised learning methods based on the framework of Structure-From-Motion (SfM) simultaneously predict depth and camera relative pose. However, dynamically moving objects in the scene violate the static world assumption, resulting in inaccurate depths of dynamic objects. In this work, we propose a new method to address such dynamic object movements through monocular 3D object detection. Specifically, we first detect 3D objects in the images and build the per-pixel correspondence of the dynamic pixels with the detected object pose while leaving the static pixels corresponding to the rigid background to be modeled with camera motion. In this way, the depth of every pixel can be learned via a meaningful geometry model. Besides, objects are detected as cuboids with absolute scale, which is used to eliminate the scale ambiguity problem inherent in monocular vision. Experiments on the KITTI depth dataset show that our method achieves State-of-The-Art performance for depth estimation. Furthermore, joint training of depth, camera motion and object pose also improves monocular 3D object detection performance. To the best of our knowledge, this is the first work that allows a monocular 3D object detection network to be fine-tuned in a self-supervised manner.