 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Spatio-Temporal Alignment of End-to-End 3D Perception
Dec 29, 2025Spatio-temporal alignment is crucial for temporal modeling of end-to-end (E2E) perception in autonomous driving (AD), providing valuable structural and textural prior information. Existing methods typically rely on the attention mechanism to align objects across frames, simplifying the motion model with a unified explicit physical model (constant velocity, etc.). These approaches prefer semantic features for implicit alignment, challenging the importance of explicit motion modeling in the traditional perception paradigm. However, variations in motion states and object features across categories and frames render this alignment suboptimal. To address this, we propose HAT, a spatio-temporal alignment module that allows each object to adaptively decode the optimal alignment proposal from multiple hypotheses without direct supervision. Specifically, HAT first utilizes multiple explicit motion models to generate spatial anchors and motion-aware feature proposals for historical instances. It then performs multi-hypothesis decoding by incorporating semantic and motion cues embedded in cached object queries, ultimately providing the optimal alignment proposal for the target frame. On nuScenes, HAT consistently improves 3D temporal detectors and trackers across diverse baselines. It achieves state-of-the-art tracking results with 46.0% AMOTA on the test set when paired with the DETR3D detector. In an object-centric E2E AD method, HAT enhances perception accuracy (+1.3% mAP, +3.1% AMOTA) and reduces the collision rate by 32%. When semantics are corrupted (nuScenes-C), the enhancement of motion modeling by HAT enables more robust perception and planning in the E2E AD.
PCF-Grasp: Converting Point Completion to Geometry Feature to Enhance 6-DoF Grasp
Apr 22, 2025The 6-Degree of Freedom (DoF) grasp method based on point clouds has shown significant potential in enabling robots to grasp target objects. However, most existing methods are based on the point clouds (2.5D points) generated from single-view depth images. These point clouds only have one surface side of the object providing incomplete geometry information, which mislead the grasping algorithm to judge the shape of the target object, resulting in low grasping accuracy. Humans can accurately grasp objects from a single view by leveraging their geometry experience to estimate object shapes. Inspired by humans, we propose a novel 6-DoF grasping framework that converts the point completion results as object shape features to train the 6-DoF grasp network. Here, point completion can generate approximate complete points from the 2.5D points similar to the human geometry experience, and converting it as shape features is the way to utilize it to improve grasp efficiency. Furthermore, due to the gap between the network generation and actual execution, we integrate a score filter into our framework to select more executable grasp proposals for the real robot. This enables our method to maintain a high grasp quality in any camera viewpoint. Extensive experiments demonstrate that utilizing complete point features enables the generation of significantly more accurate grasp proposals and the inclusion of a score filter greatly enhances the credibility of real-world robot grasping. Our method achieves a 17.8\% success rate higher than the state-of-the-art method in real-world experiments.
PR2: A Physics- and Photo-realistic Testbed for Embodied AI and Humanoid Robots
Sep 03, 2024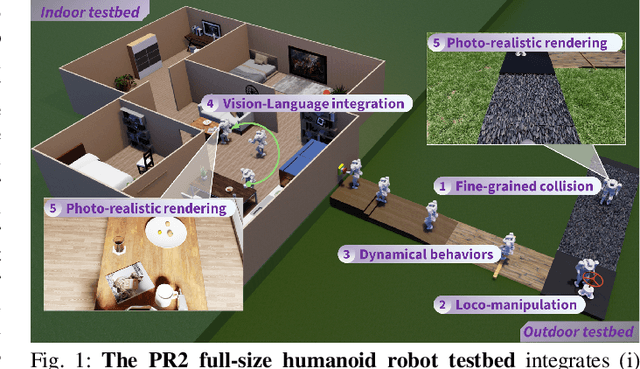



This paper presents the development of a Physics-realistic and Photo-\underline{r}ealistic humanoid robot testbed, PR2, to facilitate collaborative research between Embodied Artificial Intelligence (Embodied AI) and robotics. PR2 offers high-quality scene rendering and robot dynamic simulation, enabling (i) the creation of diverse scenes using various digital assets, (ii) the integration of advanced perception or foundation models, and (iii) the implementation of planning and control algorithms for dynamic humanoid robot behaviors based on environmental feedback. The beta version of PR2 has been deployed for the simulation track of a nationwide full-size humanoid robot competition for college students, attracting 137 teams and over 400 participants within four months. This competition covered traditional tasks in bipedal walking, as well as novel challenges in loco-manipulation and language-instruction-based object search, marking a first for public college robotics competitions. A retrospective analysis of the competition suggests that future events should emphasize the integration of locomotion with manipulation and perception. By making the PR2 testbed publicly available at https://github.com/pr2-humanoid/PR2-Platform, we aim to further advance education and training in humanoid robotics.
Learning effective pruning at initialization from iterative pruning
Aug 27, 2024Pruning at initialization (PaI) reduces training costs by removing weights before training, which becomes increasingly crucial with the growing network size. However, current PaI methods still have a large accuracy gap with iterative pruning, especially at high sparsity levels. This raises an intriguing question: can we get inspiration from iterative pruning to improve the PaI performance? In the lottery ticket hypothesis, the iterative rewind pruning (IRP) finds subnetworks retroactively by rewinding the parameter to the original initialization in every pruning iteration, which means all the subnetworks are based on the initial state. Here, we hypothesise the surviving subnetworks are more important and bridge the initial feature and their surviving score as the PaI criterion. We employ an end-to-end neural network (\textbf{AutoS}parse) to learn this correlation, input the model's initial features, output their score and then prune the lowest score parameters before training. To validate the accuracy and generalization of our method, we performed PaI across various models. Results show that our approach outperforms existing methods in high-sparsity settings. Notably, as the underlying logic of model pruning is consistent in different models, only one-time IRP on one model is needed (e.g., once IRP on ResNet-18/CIFAR-10, AutoS can be generalized to VGG-16/CIFAR-10, ResNet-18/TinyImageNet, et al.). As the first neural network-based PaI method, we conduct extensive experiments to validate the factors influencing this approach. These results reveal the learning tendencies of neural networks and provide new insights into our understanding and research of PaI from a practical perspective. Our code is available at: https://github.com/ChengYaofeng/AutoSparse.git.
CDM-MPC: An Integrated Dynamic Planning and Control Framework for Bipedal Robots Jumping
May 20, 2024



Performing acrobatic maneuvers like dynamic jumping in bipedal robots presents significant challenges in terms of actuation, motion planning, and control. Traditional approaches to these tasks often simplify dynamics to enhance computational efficiency, potentially overlooking critical factors such as the control of centroidal angular momentum (CAM) and the variability of centroidal composite rigid body inertia (CCRBI). This paper introduces a novel integrated dynamic planning and control framework, termed centroidal dynamics model-based model predictive control (CDM-MPC), designed for robust jumping control that fully considers centroidal momentum and non-constant CCRBI. The framework comprises an optimization-based kinodynamic motion planner and an MPC controller for real-time trajectory tracking and replanning. Additionally, a centroidal momentum-based inverse kinematics (IK) solver and a landing heuristic controller are developed to ensure stability during high-impact landings. The efficacy of the CDM-MPC framework is validated through extensive testing on the full-sized humanoid robot KUAVO in both simulations and experiments.
Socially Adaptive Path Planning Based on Generative Adversarial Network
Apr 29, 2024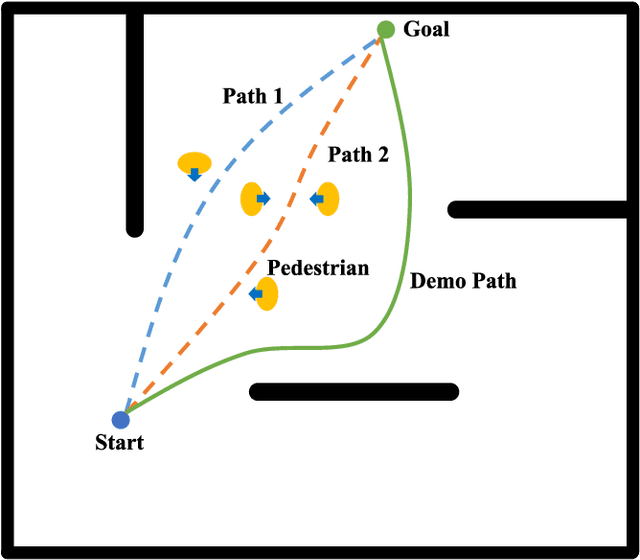

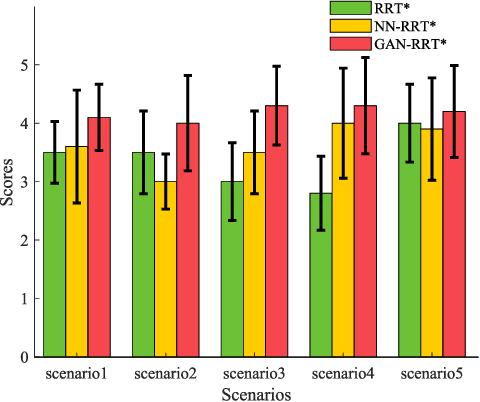
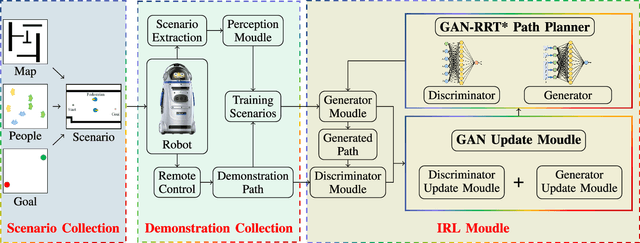
The natural interaction between robots and pedestrians in the process of autonomous navigation is crucial for the intelligent development of mobile robots, which requires robots to fully consider social rules and guarantee the psychological comfort of pedestrians. Among the research results in the field of robotic path planning, the learning-based socially adaptive algorithms have performed well in some specific human-robot interaction environments. However, human-robot interaction scenarios are diverse and constantly changing in daily life, and the generalization of robot socially adaptive path planning remains to be further investigated. In order to address this issue, this work proposes a new socially adaptive path planning algorithm by combining the generative adversarial network (GAN) with the Optimal Rapidly-exploring Random Tree (RRT*) navigation algorithm. Firstly, a GAN model with strong generalization performance is proposed to adapt the navigation algorithm to more scenarios. Secondly, a GAN model based Optimal Rapidly-exploring Random Tree navigation algorithm (GAN-RRT*) is proposed to generate paths in human-robot interaction environments. Finally, we propose a socially adaptive path planning framework named GAN-RTIRL, which combines the GAN model with Rapidly-exploring random Trees Inverse Reinforcement Learning (RTIRL) to improve the homotopy rate between planned and demonstration paths. In the GAN-RTIRL framework, the GAN-RRT* path planner can update the GAN model from the demonstration path. In this way, the robot can generate more anthropomorphic paths in human-robot interaction environments and has stronger generalization in more complex environments. Experimental results reveal that our proposed method can effectively improve the anthropomorphic degree of robot motion planning and the homotopy rate between planned and demonstration paths.
GVD-Exploration: An Efficient Autonomous Robot Exploration Framework Based on Fast Generalized Voronoi Diagram Extraction
Sep 12, 2023Rapidly-exploring Random Trees (RRTs) are a popular technique for autonomous exploration of mobile robots. However, the random sampling used by RRTs can result in inefficient and inaccurate frontiers extraction, which affects the exploration performance. To address the issues of slow path planning and high path cost, we propose a framework that uses a generalized Voronoi diagram (GVD) based multi-choice strategy for robot exploration. Our framework consists of three components: a novel mapping model that uses an end-to-end neural network to construct GVDs of the environments in real time; a GVD-based heuristic scheme that accelerates frontiers extraction and reduces frontiers redundancy; and a multi-choice frontiers assignment scheme that considers different types of frontiers and enables the robot to make rational decisions during the exploration process. We evaluate our method on simulation and real-world experiments and show that it outperforms RRT-based exploration methods in terms of efficiency and robustness.
3D Object Aided Self-Supervised Monocular Depth Estimation
Dec 04, 2022Monocular depth estimation has been actively studied in fields such as robot vision, autonomous driving, and 3D scene understanding. Given a sequence of color images, unsupervised learning methods based on the framework of Structure-From-Motion (SfM) simultaneously predict depth and camera relative pose. However, dynamically moving objects in the scene violate the static world assumption, resulting in inaccurate depths of dynamic objects. In this work, we propose a new method to address such dynamic object movements through monocular 3D object detection. Specifically, we first detect 3D objects in the images and build the per-pixel correspondence of the dynamic pixels with the detected object pose while leaving the static pixels corresponding to the rigid background to be modeled with camera motion. In this way, the depth of every pixel can be learned via a meaningful geometry model. Besides, objects are detected as cuboids with absolute scale, which is used to eliminate the scale ambiguity problem inherent in monocular vision. Experiments on the KITTI depth dataset show that our method achieves State-of-The-Art performance for depth estimation. Furthermore, joint training of depth, camera motion and object pose also improves monocular 3D object detection performance. To the best of our knowledge, this is the first work that allows a monocular 3D object detection network to be fine-tuned in a self-supervised manner.