 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially Adaptive Path Planning Based on Generative Adversarial Network
Apr 29, 2024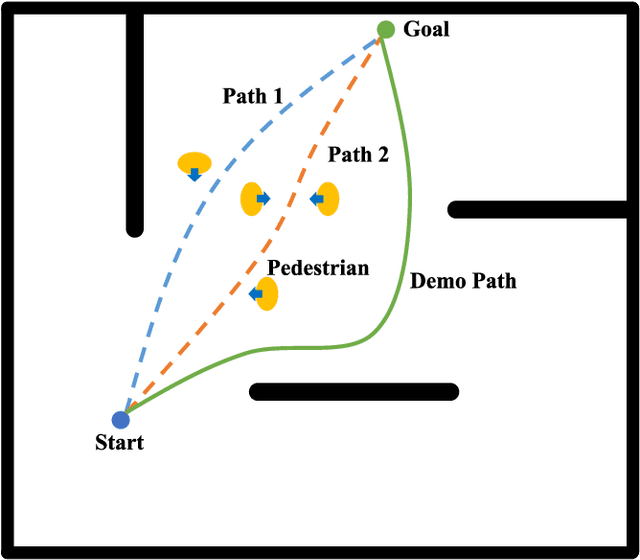

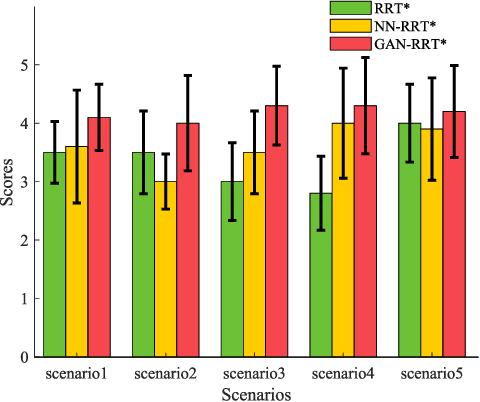
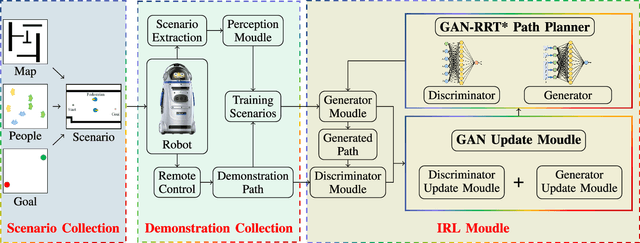
The natural interaction between robots and pedestrians in the process of autonomous navigation is crucial for the intelligent development of mobile robots, which requires robots to fully consider social rules and guarantee the psychological comfort of pedestrians. Among the research results in the field of robotic path planning, the learning-based socially adaptive algorithms have performed well in some specific human-robot interaction environments. However, human-robot interaction scenarios are diverse and constantly changing in daily life, and the generalization of robot socially adaptive path planning remains to be further investigated. In order to address this issue, this work proposes a new socially adaptive path planning algorithm by combining the generative adversarial network (GAN) with the Optimal Rapidly-exploring Random Tree (RRT*) navigation algorithm. Firstly, a GAN model with strong generalization performance is proposed to adapt the navigation algorithm to more scenarios. Secondly, a GAN model based Optimal Rapidly-exploring Random Tree navigation algorithm (GAN-RRT*) is proposed to generate paths in human-robot interaction environments. Finally, we propose a socially adaptive path planning framework named GAN-RTIRL, which combines the GAN model with Rapidly-exploring random Trees Inverse Reinforcement Learning (RTIRL) to improve the homotopy rate between planned and demonstration paths. In the GAN-RTIRL framework, the GAN-RRT* path planner can update the GAN model from the demonstration path. In this way, the robot can generate more anthropomorphic paths in human-robot interaction environments and has stronger generalization in more complex environments. Experimental results reveal that our proposed method can effectively improve the anthropomorphic degree of robot motion planning and the homotopy rate between planned and demonstration paths.
A Topological Method for Comparing Document Semantics
Dec 08, 2020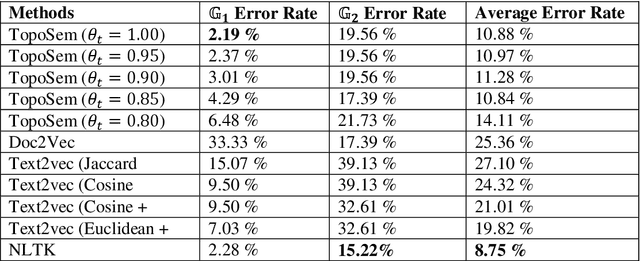
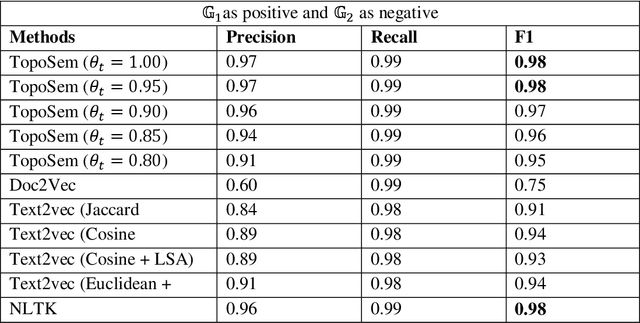
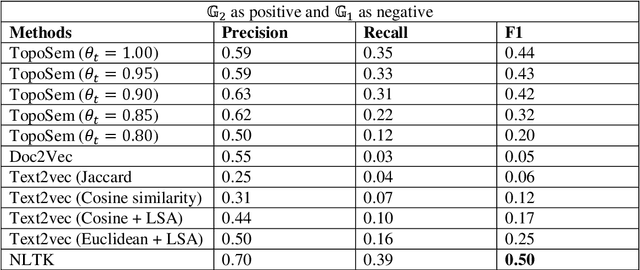
Comparing document semantics is one of the toughest tasks in both Natural Language Processing and Information Retrieval. To date, on one hand, the tools for this task are still rare. On the other hand, most relevant methods are devised from the statistic or the vector space model perspectives but nearly none from a topological perspective. In this paper, we hope to make a different sound. A novel algorithm based on topological persistence for comparing semantics similarity between two documents is proposed. Our experiments are conducted on a document dataset with human judges' results. A collection of state-of-the-art methods are selected for comparison. The experimental results show that our algorithm can produce highly human-consistent results, and also beats most state-of-the-art methods though ties with NLTK.
* 9 pages, 3 tables, 9th International Conference on Natural Language Processing (NLP 2020)