 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Degeneracy Scheme for Lidar SLAM based on Particle Filter in Geometry Feature-Less Environments
Feb 17, 2025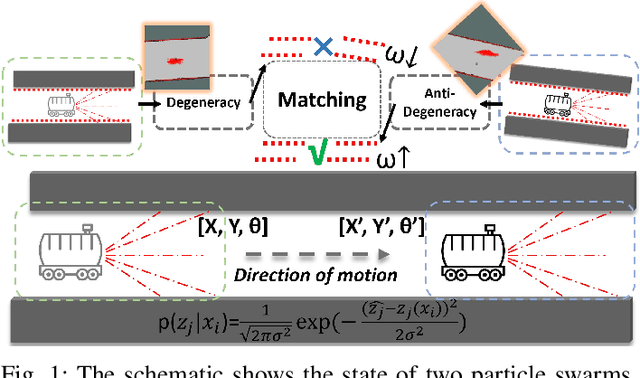

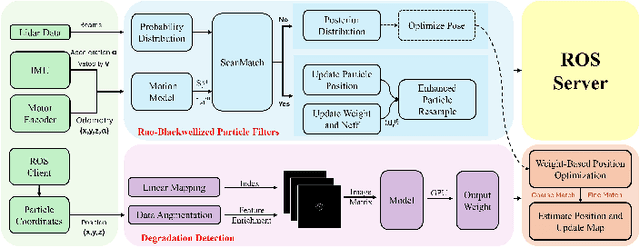
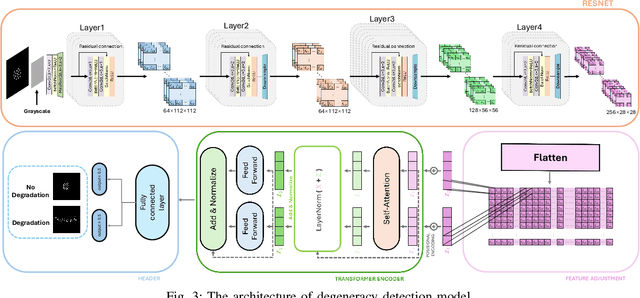
Simultaneous localization and mapping (SLAM) based on particle filtering has been extensively employed in indoor scenarios due to its high efficiency. However, in geometry feature-less scenes, the accuracy is severely reduced due to lack of constraints. In this article, we propose an anti-degeneracy system based on deep learning. Firstly, we design a scale-invariant linear mapping to convert coordinates in continuous space into discrete indexes, in which a data augmentation method based on Gaussian model is proposed to ensure the model performance by effectively mitigating the impact of changes in the number of particles on the feature distribution. Secondly, we develop a degeneracy detection model using residual neural networks (ResNet) and transformer which is able to identify degeneracy by scrutinizing the distribution of the particle population. Thirdly, an adaptive anti-degeneracy strategy is designed, which first performs fusion and perturbation on the resample process to provide rich and accurate initial values for the pose optimization, and use a hierarchical pose optimization combining coarse and fine matching, which is able to adaptively adjust the optimization frequency and the sensor trustworthiness according to the degree of degeneracy, in order to enhance the ability of searching the global optimal pose. Finally, we demonstrate the optimality of the model, as well as the improvement of the image matrix method and GPU on the computation time through ablation experiments, and verify the performance of the anti-degeneracy system in different scenarios through simulation experiments and real experiments. This work has been submitted to IEEE for publication. Copyright may be transferred without notice, after which this version may no longer be available.
Online Robot Motion Planning Methodology Guided by Group Social Proxemics Feature
Feb 07, 2025



Nowadays robot is supposed to demonstrate human-like perception, reasoning and behavior pattern in social or service application. However, most of the existing motion planning methods are incompatible with above requirement. A potential reason is that the existing navigation algorithms usually intend to treat people as another kind of obstacle, and hardly take the social principle or awareness into consideration. In this paper, we attempt to model the proxemics of group and blend it into the scenario perception and navigation of robot. For this purpose, a group clustering method considering both social relevance and spatial confidence is introduced. It can enable robot to identify individuals and divide them into groups. Next, we propose defining the individual proxemics within magnetic dipole model, and further established the group proxemics and scenario map through vector-field superposition. On the basis of the group clustering and proxemics modeling, we present the method to obtain the optimal observation positions (OOPs) of group. Once the OOPs grid and scenario map are established, a heuristic path is employed to generate path that guide robot cruising among the groups for interactive purpose. A series of experiments are conducted to validate the proposed methodology on the practical robot, the results have demonstrated that our methodology has achieved promising performance on group recognition accuracy and path-generation efficiency. This concludes that the group awareness evolved as an important module to make robot socially behave in the practical scenario.
Socially Adaptive Path Planning Based on Generative Adversarial Network
Apr 29, 2024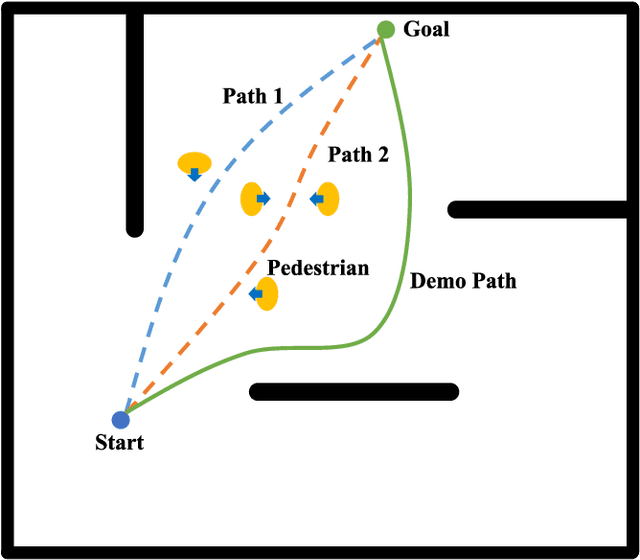

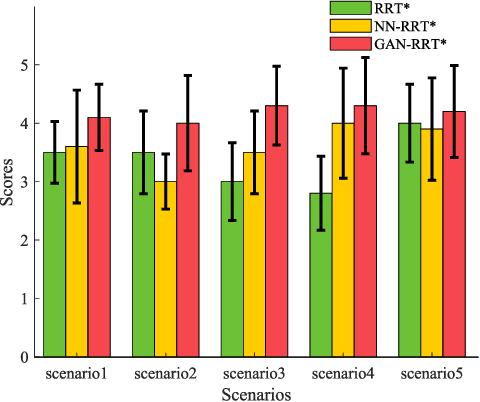
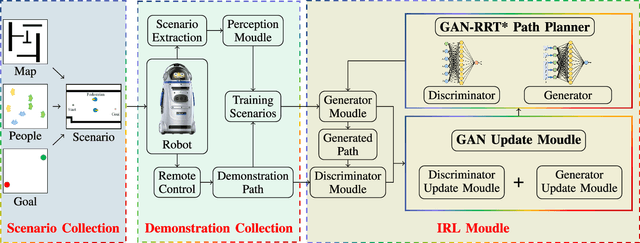
The natural interaction between robots and pedestrians in the process of autonomous navigation is crucial for the intelligent development of mobile robots, which requires robots to fully consider social rules and guarantee the psychological comfort of pedestrians. Among the research results in the field of robotic path planning, the learning-based socially adaptive algorithms have performed well in some specific human-robot interaction environments. However, human-robot interaction scenarios are diverse and constantly changing in daily life, and the generalization of robot socially adaptive path planning remains to be further investigated. In order to address this issue, this work proposes a new socially adaptive path planning algorithm by combining the generative adversarial network (GAN) with the Optimal Rapidly-exploring Random Tree (RRT*) navigation algorithm. Firstly, a GAN model with strong generalization performance is proposed to adapt the navigation algorithm to more scenarios. Secondly, a GAN model based Optimal Rapidly-exploring Random Tree navigation algorithm (GAN-RRT*) is proposed to generate paths in human-robot interaction environments. Finally, we propose a socially adaptive path planning framework named GAN-RTIRL, which combines the GAN model with Rapidly-exploring random Trees Inverse Reinforcement Learning (RTIRL) to improve the homotopy rate between planned and demonstration paths. In the GAN-RTIRL framework, the GAN-RRT* path planner can update the GAN model from the demonstration path. In this way, the robot can generate more anthropomorphic paths in human-robot interaction environments and has stronger generalization in more complex environments. Experimental results reveal that our proposed method can effectively improve the anthropomorphic degree of robot motion planning and the homotopy rate between planned and demonstration paths.
HeR-DRL:Heterogeneous Relational Deep Reinforcement Learning for Decentralized Multi-Robot Crowd Navigation
Mar 15, 2024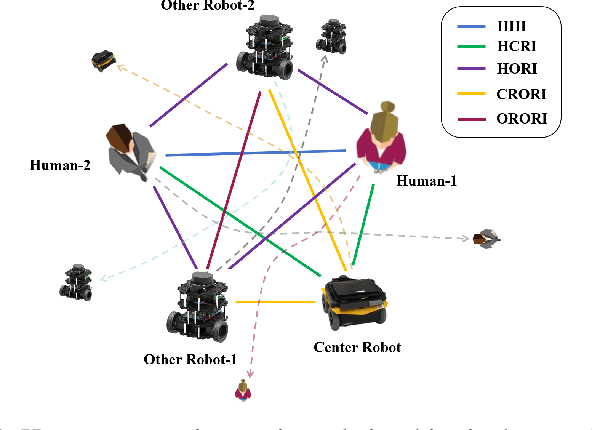
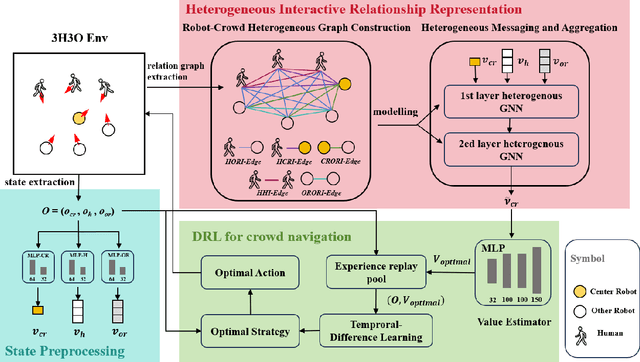
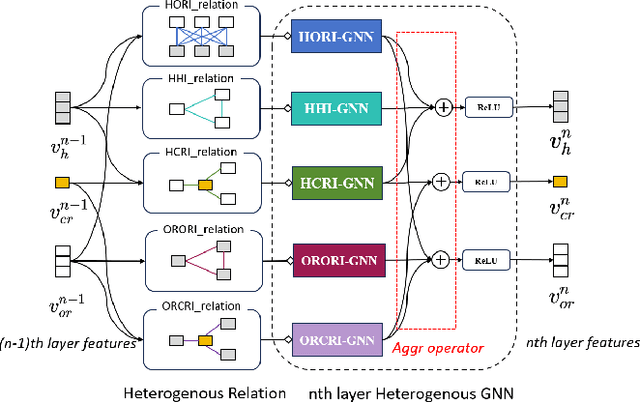
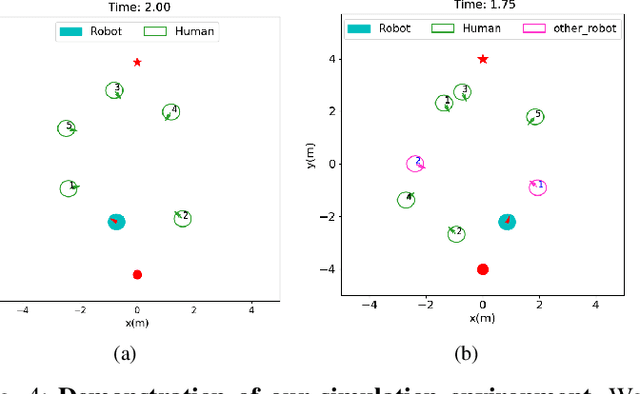
Crowd navigation has received significant research attention in recent years, especially DRL-based methods. While single-robot crowd scenarios have dominated research, they offer limited applicability to real-world complexities. The heterogeneity of interaction among multiple agent categories, like in decentralized multi-robot pedestrian scenarios, are frequently disregarded. This "interaction blind spot" hinders generalizability and restricts progress towards robust navigation algorithms. In this paper, we propose a heterogeneous relational deep reinforcement learning(HeR-DRL), based on customised heterogeneous GNN, in order to improve navigation strategies in decentralized multi-robot crowd navigation. Firstly, we devised a method for constructing robot-crowd heterogenous relation graph that effectively simulates the heterogeneous pair-wise interaction relationships. We proposed a new heterogeneous graph neural network for transferring and aggregating the heterogeneous state information. Finally, we incorporate the encoded information into deep reinforcement learning to explore the optimal policy. HeR-DRL are rigorously evaluated through comparing it to state-of-the-art algorithms in both single-robot and multi-robot circle crowssing scenario. The experimental results demonstrate that HeR-DRL surpasses the state-of-the-art approaches in overall performance, particularly excelling in safety and comfort metrics. This underscores the significance of interaction heterogeneity for crowd navigation. The source code will be publicly released in https://github.com/Zhouxy-Debugging-Den/HeR-DRL.
Graph Neural Network Based Method for Path Planning Problem
Sep 26, 2023



Sampling-based path planning is a widely used method in robotics, particularly in high-dimensional state space. Among the whole process of the path planning, collision detection is the most time-consuming operation. In this paper, we propose a learning-based path planning method that aims to reduce the number of collision detection. We develop an efficient neural network model based on Graph Neural Networks (GNN) and use the environment map as input. The model outputs weights for each neighbor based on the input and current vertex information, which are used to guide the planner in avoiding obstacles. We evaluate the proposed method's efficiency through simulated random worlds and real-world experiments, respectively. The results demonstrate that the proposed method significantly reduces the number of collision detection and improves the path planning speed in high-dimensional environments.
GVD-Exploration: An Efficient Autonomous Robot Exploration Framework Based on Fast Generalized Voronoi Diagram Extraction
Sep 12, 2023Rapidly-exploring Random Trees (RRTs) are a popular technique for autonomous exploration of mobile robots. However, the random sampling used by RRTs can result in inefficient and inaccurate frontiers extraction, which affects the exploration performance. To address the issues of slow path planning and high path cost, we propose a framework that uses a generalized Voronoi diagram (GVD) based multi-choice strategy for robot exploration. Our framework consists of three components: a novel mapping model that uses an end-to-end neural network to construct GVDs of the environments in real time; a GVD-based heuristic scheme that accelerates frontiers extraction and reduces frontiers redundancy; and a multi-choice frontiers assignment scheme that considers different types of frontiers and enables the robot to make rational decisions during the exploration process. We evaluate our method on simulation and real-world experiments and show that it outperforms RRT-based exploration methods in terms of efficiency and robustness.
3D Object Aided Self-Supervised Monocular Depth Estimation
Dec 04, 2022Monocular depth estimation has been actively studied in fields such as robot vision, autonomous driving, and 3D scene understanding. Given a sequence of color images, unsupervised learning methods based on the framework of Structure-From-Motion (SfM) simultaneously predict depth and camera relative pose. However, dynamically moving objects in the scene violate the static world assumption, resulting in inaccurate depths of dynamic objects. In this work, we propose a new method to address such dynamic object movements through monocular 3D object detection. Specifically, we first detect 3D objects in the images and build the per-pixel correspondence of the dynamic pixels with the detected object pose while leaving the static pixels corresponding to the rigid background to be modeled with camera motion. In this way, the depth of every pixel can be learned via a meaningful geometry model. Besides, objects are detected as cuboids with absolute scale, which is used to eliminate the scale ambiguity problem inherent in monocular vision. Experiments on the KITTI depth dataset show that our method achieves State-of-The-Art performance for depth estimation. Furthermore, joint training of depth, camera motion and object pose also improves monocular 3D object detection performance. To the best of our knowledge, this is the first work that allows a monocular 3D object detection network to be fine-tuned in a self-supervised manner.
Learning-based Fast Path Planning in Complex Environments
Oct 19, 2021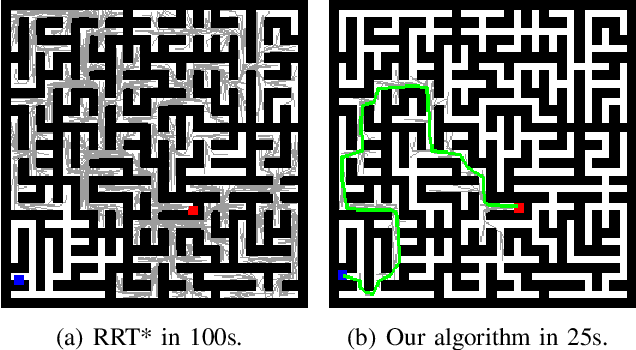
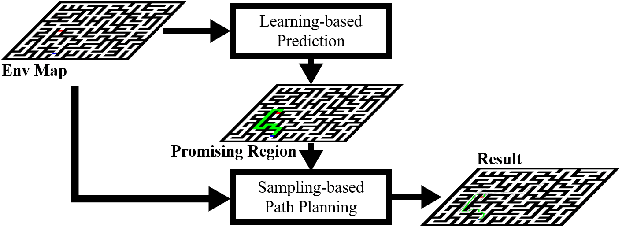
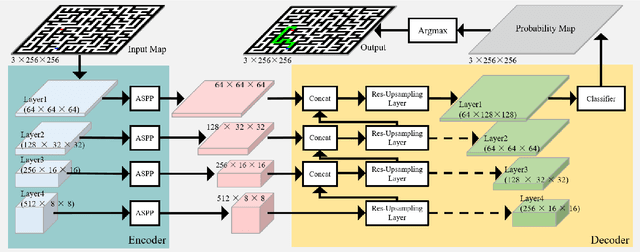
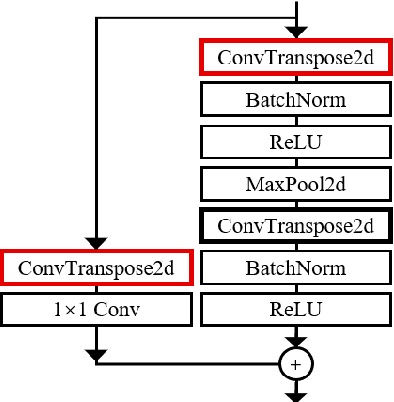
In this paper, we present a novel path planning algorithm to achieve fast path planning in complex environments. Most existing path planning algorithms are difficult to quickly find a feasible path in complex environments or even fail. However, our proposed framework can overcome this difficulty by using a learning-based prediction module and a sampling-based path planning module. The prediction module utilizes an auto-encoder-decoder-like convolutional neural network (CNN) to output a promising region where the feasible path probably lies in. In this process, the environment is treated as an RGB image to feed in our designed CNN module, and the output is also an RGB image. No extra computation is required so that we can maintain a high processing speed of 60 frames-per-second (FPS). Incorporated with a sampling-based path planner, we can extract a feasible path from the output image so that the robot can track it from start to goal. To demonstrate the advantage of the proposed algorithm, we compare it with conventional path planning algorithms in a series of simulation experiments. The results reveal that the proposed algorithm can achieve much better performance in terms of planning time, success rate, and path length.