 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Sparse Attention for Fast Video Generation via Offline Layer-Wise Sparsity Profiling and Online Bidirectional Co-Clustering
Mar 19, 2026Diffusion Transformers (DiTs) achieve strong video generation quality but suffer from high inference cost due to dense 3D attention, leading to the development of sparse attention technologies to improve efficiency. However, existing training-free sparse attention methods in video generation still face two unresolved limitations: ignoring layer heterogeneity in attention pruning and ignoring query-key coupling in block partitioning, which hinder a better quality-speedup trade-off. In this work, we uncover a critical insight that the attention sparsity of each layer is its intrinsic property, with minor effects across different inputs. Motivated by this, we propose SVOO, a training-free Sparse attention framework for fast Video generation via Offline layer-wise sparsity profiling and Online bidirectional co-clustering. Specifically, SVOO adopts a two-stage paradigm: (i) offline layer-wise sensitivity profiling to derive intrinsic per-layer pruning levels, and (ii) online block-wise sparse attention via a novel bidirectional co-clustering algorithm. Extensive experiments on seven widely used video generation models demonstrate that SVOO achieves a superior quality-speedup trade-off over state-of-the-art methods, delivering up to $1.93\times$ speedup while maintaining a PSNR of up to 29 dB on Wan2.1.
SurgAtt-Tracker: Online Surgical Attention Tracking via Temporal Proposal Reranking and Motion-Aware Refinement
Feb 24, 2026Accurate and stable field-of-view (FoV) guidance is critical for safe and efficient minimally invasive surgery, yet existing approaches often conflate visual attention estimation with downstream camera control or rely on direct object-centric assumptions. In this work, we formulate surgical attention tracking as a spatio-temporal learning problem and model surgeon focus as a dense attention heatmap, enabling continuous and interpretable frame-wise FoV guidance. We propose SurgAtt-Tracker, a holistic framework that robustly tracks surgical attention by exploiting temporal coherence through proposal-level reranking and motion-aware refinement, rather than direct regression. To support systematic training and evaluation, we introduce SurgAtt-1.16M, a large-scale benchmark with a clinically grounded annotation protocol that enables comprehensive heatmap-based attention analysis across procedures and institutions. Extensive experiments on multiple surgical datasets demonstrate that SurgAtt-Tracker consistently achieves state-of-the-art performance and strong robustness under occlusion, multi-instrument interference, and cross-domain settings. Beyond attention tracking, our approach provides a frame-wise FoV guidance signal that can directly support downstream robotic FoV planning and automatic camera control.
Robust Docking Maneuvers for Autonomous Trolley Collection: An Optimization-Based Visual Servoing Scheme
Sep 09, 2025
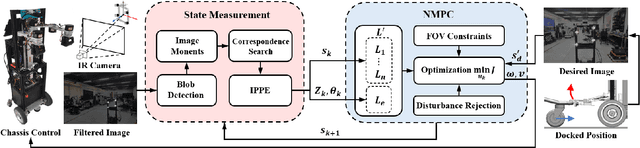
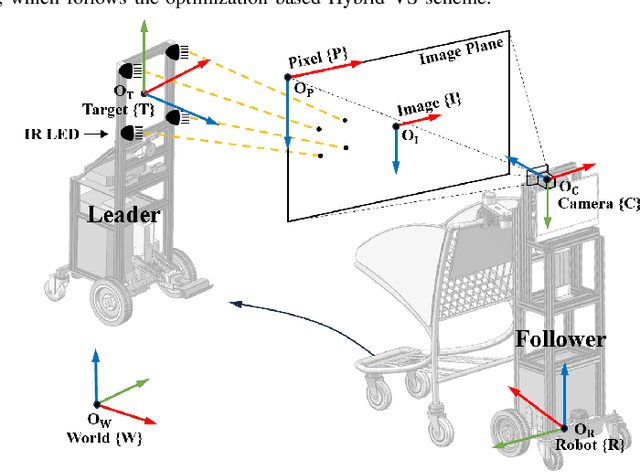

Service robots have demonstrated significant potential for autonomous trolley collection and redistribution in public spaces like airports or warehouses to improve efficiency and reduce cost. Usually, a fully autonomous system for the collection and transportation of multiple trolleys is based on a Leader-Follower formation of mobile manipulators, where reliable docking maneuvers of the mobile base are essential to align trolleys into organized queues. However, developing a vision-based robotic docking system faces significant challenges: high precision requirements, environmental disturbances, and inherent robot constraints. To address these challenges, we propose an optimization-based Visual Servoing scheme that incorporates active infrared markers for robust feature extraction across diverse lighting conditions. This framework explicitly models nonholonomic kinematics and visibility constraints within the Hybrid Visual Servoing problem, augmented with an observer for disturbance rejection to ensure precise and stable docking. Experimental results across diverse environments demonstrate the robustness of this system, with quantitative evaluations confirming high docking accuracy.
Socially Aware Robot Crowd Navigation via Online Uncertainty-Driven Risk Adaptation
Jun 17, 2025Navigation in human-robot shared crowded environments remains challenging, as robots are expected to move efficiently while respecting human motion conventions. However, many existing approaches emphasize safety or efficiency while overlooking social awareness. This article proposes Learning-Risk Model Predictive Control (LR-MPC), a data-driven navigation algorithm that balances efficiency, safety, and social awareness. LR-MPC consists of two phases: an offline risk learning phase, where a Probabilistic Ensemble Neural Network (PENN) is trained using risk data from a heuristic MPC-based baseline (HR-MPC), and an online adaptive inference phase, where local waypoints are sampled and globally guided by a Multi-RRT planner. Each candidate waypoint is evaluated for risk by PENN, and predictions are filtered using epistemic and aleatoric uncertainty to ensure robust decision-making. The safest waypoint is selected as the MPC input for real-time navigation. Extensive experiments demonstrate that LR-MPC outperforms baseline methods in success rate and social awareness, enabling robots to navigate complex crowds with high adaptability and low disruption. A website about this work is available at https://sites.google.com/view/lr-mpc.
Uni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
PierGuard: A Planning Framework for Underwater Robotic Inspection of Coastal Piers
May 07, 2025Using underwater robots instead of humans for the inspection of coastal piers can enhance efficiency while reducing risks. A key challenge in performing these tasks lies in achieving efficient and rapid path planning within complex environments. Sampling-based path planning methods, such as Rapidly-exploring Random Tree* (RRT*), have demonstrated notable performance in high-dimensional spaces. In recent years, researchers have begun designing various geometry-inspired heuristics and neural network-driven heuristics to further enhance the effectiveness of RRT*. However, the performance of these general path planning methods still requires improvement when applied to highly cluttered underwater environments. In this paper, we propose PierGuard, which combines the strengths of bidirectional search and neural network-driven heuristic regions. We design a specialized neural network to generate high-quality heuristic regions in cluttered maps, thereby improving the performance of the path planning. Through extensive simulation and real-world ocean field experiments, we demonstrate the effectiveness and efficiency of our proposed method compared with previous research. Our method achieves approximately 2.6 times the performance of the state-of-the-art geometric-based sampling method and nearly 4.9 times that of the state-of-the-art learning-based sampling method. Our results provide valuable insights for the automation of pier inspection and the enhancement of maritime safety. The updated experimental video is available in the supplementary materials.
Dual Attention Driven Lumbar Magnetic Resonance Image Feature Enhancement and Automatic Diagnosis of Herniation
Apr 28, 2025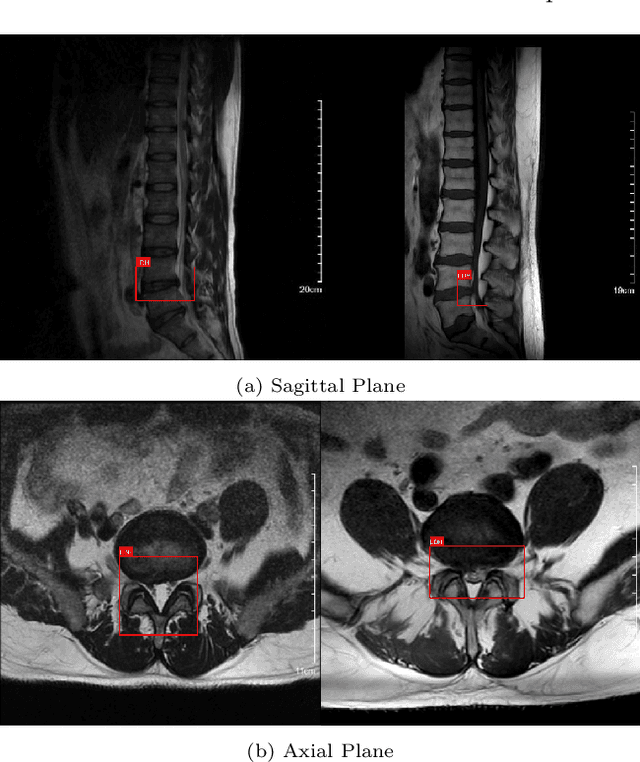
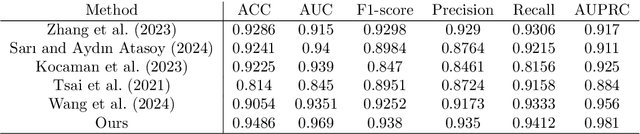
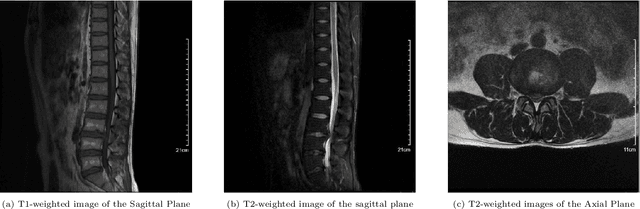
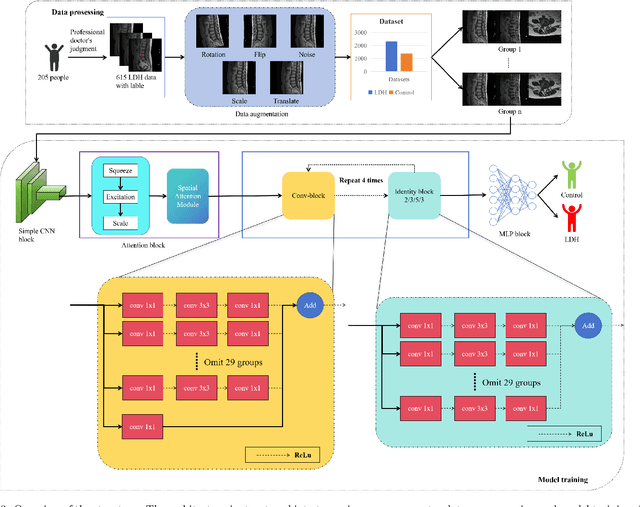
Lumbar disc herniation (LDH) is a common musculoskeletal disease that requires magnetic resonance imaging (MRI) for effective clinical management. However, the interpretation of MRI images heavily relies on the expertise of radiologists, leading to delayed diagnosis and high costs for training physicians. Therefore, this paper proposes an innovative automated LDH classification framework. To address these key issues, the framework utilizes T1-weighted and T2-weighted MRI images from 205 people. The framework extracts clinically actionable LDH features and generates standardized diagnostic outputs by leveraging data augmentation and channel and spatial attention mechanisms. These outputs can help physicians make confident and time-effective care decisions when needed. The proposed framework achieves an area under the receiver operating characteristic curve (AUC-ROC) of 0.969 and an accuracy of 0.9486 for LDH detection. The experimental results demonstrate the performance of the proposed framework. Our framework only requires a small number of datasets for training to demonstrate high diagnostic accuracy. This is expected to be a solution to enhance the LDH detection capabilities of primary hospitals.
Endo-TTAP: Robust Endoscopic Tissue Tracking via Multi-Facet Guided Attention and Hybrid Flow-point Supervision
Mar 28, 2025
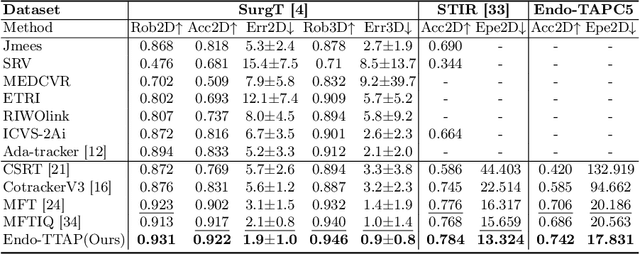
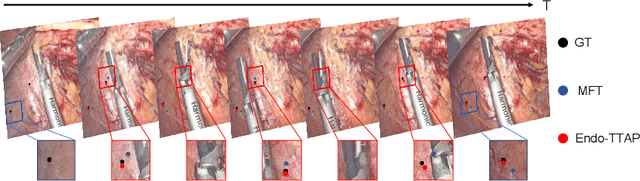

Accurate tissue point tracking in endoscopic videos is critical for robotic-assisted surgical navigation and scene understanding, but remains challenging due to complex deformations, instrument occlusion, and the scarcity of dense trajectory annotations. Existing methods struggle with long-term tracking under these conditions due to limited feature utilization and annotation dependence. We present Endo-TTAP, a novel framework addressing these challenges through: (1) A Multi-Facet Guided Attention (MFGA) module that synergizes multi-scale flow dynamics, DINOv2 semantic embeddings, and explicit motion patterns to jointly predict point positions with uncertainty and occlusion awareness; (2) A two-stage curriculum learning strategy employing an Auxiliary Curriculum Adapter (ACA) for progressive initialization and hybrid supervision. Stage I utilizes synthetic data with optical flow ground truth for uncertainty-occlusion regularization, while Stage II combines unsupervised flow consistency and semi-supervised learning with refined pseudo-labels from off-the-shelf trackers. Extensive validation on two MICCAI Challenge datasets and our collected dataset demonstrates that Endo-TTAP achieves state-of-the-art performance in tissue point tracking, particularly in scenarios characterized by complex endoscopic conditions. The source code and dataset will be available at https://anonymous.4open.science/r/Endo-TTAP-36E5.
Collision Risk Quantification and Conflict Resolution in Trajectory Tracking for Acceleration-Actuated Multi-Robot Systems
Jan 07, 2025



One of the pivotal challenges in a multi-robot system is how to give attention to accuracy and efficiency while ensuring safety. Prior arts cannot strictly guarantee collision-free for an arbitrarily large number of robots or the results are considerably conservative. Smoothness of the avoidance trajectory also needs to be further optimized. This paper proposes an accelerationactuated simultaneous obstacle avoidance and trajectory tracking method for arbitrarily large teams of robots, that provides a nonconservative collision avoidance strategy and gives approaches for deadlock avoidance. We propose two ways of deadlock resolution, one involves incorporating an auxiliary velocity vector into the error function of the trajectory tracking module, which is proven to have no influence on global convergence of the tracking error. Furthermore, unlike the traditional methods that they address conflicts after a deadlock occurs, our decision-making mechanism avoids the near-zero velocity, which is much more safer and efficient in crowed environments. Extensive comparison show that the proposed method is superior to the existing studies when deployed in a large-scale robot system, with minimal invasiveness.
Pan-infection Foundation Framework Enables Multiple Pathogen Prediction
Dec 31, 2024


Host-response-based diagnostics can improve the accuracy of diagnosing bacterial and viral infections, thereby reducing inappropriate antibiotic prescriptions. However, the existing cohorts with limited sample size and coarse infections types are unable to support the exploration of an accurate and generalizable diagnostic model. Here, we curate the largest infection host-response transcriptome data, including 11,247 samples across 89 blood transcriptome datasets from 13 countries and 21 platforms. We build a diagnostic model for pathogen prediction starting from a pan-infection model as foundation (AUC = 0.97) based on the pan-infection dataset. Then, we utilize knowledge distillation to efficiently transfer the insights from this "teacher" model to four lightweight pathogen "student" models, i.e., staphylococcal infection (AUC = 0.99), streptococcal infection (AUC = 0.94), HIV infection (AUC = 0.93), and RSV infection (AUC = 0.94), as well as a sepsis "student" model (AUC = 0.99). The proposed knowledge distillation framework not only facilitates the diagnosis of pathogens using pan-infection data, but also enables an across-disease study from pan-infection to sepsis. Moreover, the framework enables high-degree lightweight design of diagnostic models, which is expected to be adaptively deployed in clinical settings.