 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Attention Driven Lumbar Magnetic Resonance Image Feature Enhancement and Automatic Diagnosis of Herniation
Apr 28, 2025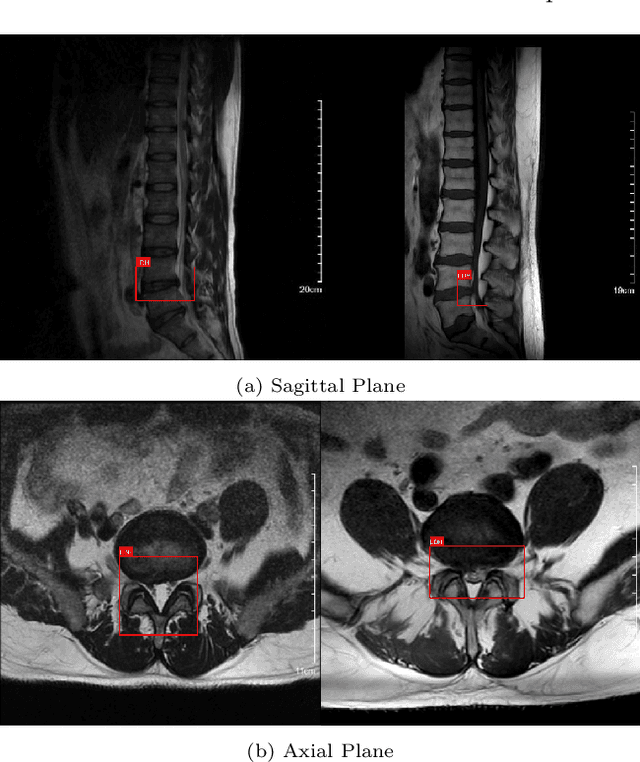
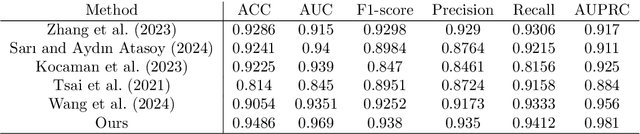
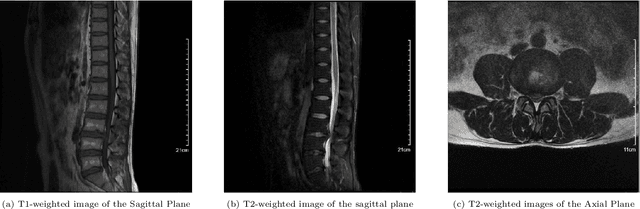
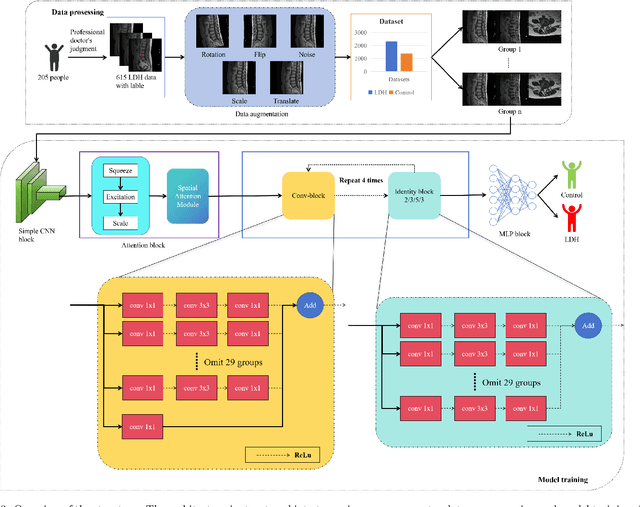
Lumbar disc herniation (LDH) is a common musculoskeletal disease that requires magnetic resonance imaging (MRI) for effective clinical management. However, the interpretation of MRI images heavily relies on the expertise of radiologists, leading to delayed diagnosis and high costs for training physicians. Therefore, this paper proposes an innovative automated LDH classification framework. To address these key issues, the framework utilizes T1-weighted and T2-weighted MRI images from 205 people. The framework extracts clinically actionable LDH features and generates standardized diagnostic outputs by leveraging data augmentation and channel and spatial attention mechanisms. These outputs can help physicians make confident and time-effective care decisions when needed. The proposed framework achieves an area under the receiver operating characteristic curve (AUC-ROC) of 0.969 and an accuracy of 0.9486 for LDH detection. The experimental results demonstrate the performance of the proposed framework. Our framework only requires a small number of datasets for training to demonstrate high diagnostic accuracy. This is expected to be a solution to enhance the LDH detection capabilities of primary hospitals.
COREval: A Comprehensive and Objective Benchmark for Evaluating the Remote Sensing Capabilities of Large Vision-Language Models
Nov 27, 2024



With the rapid development of Large Vision-Language Models (VLMs), both general-domain models and those specifically tailored for remote sensing Earth observation, have demonstrated exceptional perception and reasoning abilities within this specific field. However, the current absence of a comprehensive benchmark for holistically evaluating the remote sensing capabilities of these VLMs represents a significant gap. To bridge this gap, we propose COREval, the first benchmark designed to comprehensively and objectively evaluate the hierarchical remote sensing capabilities of VLMs. Concentrating on 2 primary capability dimensions essential to remote sensing: perception and reasoning, we further categorize 6 secondary dimensions and 22 leaf tasks to ensure a well-rounded assessment coverage for this specific field. COREval guarantees the quality of the total of 6,263 problems through a rigorous process of data collection from 50 globally distributed cities, question construction and quality control, and the format of multiple-choice questions with definitive answers allows for an objective and straightforward evaluation of VLM performance. We conducted a holistic evaluation of 13 prominent open-source VLMs from both the general and remote sensing domains, highlighting current shortcomings in their remote sensing capabilities and providing directions for improvements in their application within this specialized context. We hope that COREval will serve as a valuable resource and offer deeper insights into the challenges and potential of VLMs in the field of remote sensing.