 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseBench: A Benchmark for Remote Sensing Low-Level Visual Perception and Description in Large Vision-Language Models
May 11, 2026Low-level visual perception underpins reliable remote sensing (RS) image analysis, yet current image quality assessment (IQA) methods output uninterpretable scalar scores rather than characterizing physics-driven RS degradations, deviating markedly from the diagnostic needs of RS experts. While Vision-Language Models (VLMs) present a compelling alternative by delivering language-grounded IQA, their visual priors are heavily biased toward ground-level natural images. Consequently, whether VLMs can overcome this domain gap to perceive and articulate RS artifacts remains insufficiently studied. To bridge this gap, we propose \textbf{SenseBench}, the first dedicated diagnostic benchmark for RS low-level visual perception and description. Driven by a physics-based hierarchical taxonomy that unifies both non-reference and reference-based paradigms, SenseBench features over 10K meticulously curated instances across 6 major and 22 fine-grained RS degradation categories. Specifically, two complementary protocols are designed for evaluation: objective low-level visual \textit{perception} and subjective diagnostic \textit{description}. Comprehensive evaluation of 29 state-of-the-art VLMs reveals not only skewed domain priors and multi-distortion collapse, but also \textit{fluency illusion} and a \textit{perception-description inversion} effect. We hope SenseBench provides a robust evaluation testbed and high-quality diagnostic data to advance the development of VLMs in RS low-level perception. Code and datasets are available \href{https://github.com/Zhong-Chenchen/SenseBench}{\textcolor{blue}{here}}.
MolRecBench-Wild: A Real-World Benchmark for Optical Chemical Structure Recognition
May 07, 2026Optical Chemical Structure Recognition (OCSR) aims to translate molecular diagrams in scientific literature into machine-readable formats, but current systems remain unreliable on real-world images due to substantial visual and chemical complexity. We introduce MOSAIC, a dual-dimensional difficulty framework with 37 fine-grained labels that jointly characterize visual interference and chemical semantic challenges in molecular diagrams. Based on this framework, we construct MolRecBench-Wild, a benchmark of 5,029 structures from 820 recent chemistry papers, covering the full difficulty spectrum observed in real publications. To enable faithful semantic evaluation beyond SMILES and MolFile, we propose CARBON, a representation language capable of expressing valence variations, icon-based groups, and other non-standard chemical semantics. We further adopt a dual-track evaluation protocol supporting both CARBON and SMILES outputs for broad model compatibility. Comprehensive experiments over 18 OCSR-capable models reveal severe performance degradation on MolRecBench-Wild, exposing a large gap between previous patent benchmarks and real-world academic scenarios.
NMRTrans: Structure Elucidation from Experimental NMR Spectra via Set Transformers
Feb 10, 2026Nuclear Magnetic Resonance (NMR) spectroscopy is fundamental for molecular structure elucidation, yet interpreting spectra at scale remains time-consuming and highly expertise-dependent. While recent spectrum-as-language modeling and retrieval-based methods have shown promise, they rely heavily on large corpora of computed spectra and exhibit notable performance drops when applied to experimental measurements. To address these issues, we build NMRSpec, a large-scale corpus of experimental $^1$H and $^{13}$C spectra mined from chemical literature, and propose NMRTrans, which models spectra as unordered peak sets and aligns the model's inductive bias with the physical nature of NMR. To our best knowledge, NMRTrans is the first NMR Transformer trained solely on large-scale experimental spectra and achieves state-of-the-art performance on experimental benchmarks, improving Top-10 Accuracy over the strongest baseline by +17.82 points (61.15% vs. 43.33%), and underscoring the importance of experimental data and structure-aware architectures for reliable NMR structure elucidation.
OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
Mar 27, 2025
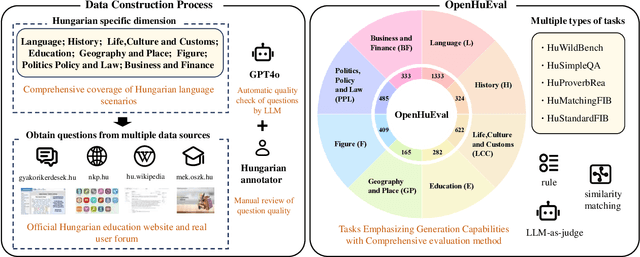


We introduce OpenHuEval, the first benchmark for LLMs focusing on the Hungarian language and specifics. OpenHuEval is constructed from a vast collection of Hungarian-specific materials sourced from multiple origins. In the construction, we incorporated the latest design principles for evaluating LLMs, such as using real user queries from the internet, emphasizing the assessment of LLMs' generative capabilities, and employing LLM-as-judge to enhance the multidimensionality and accuracy of evaluations. Ultimately, OpenHuEval encompasses eight Hungarian-specific dimensions, featuring five tasks and 3953 questions. Consequently, OpenHuEval provides the comprehensive, in-depth, and scientifically accurate assessment of LLM performance in the context of the Hungarian language and its specifics. We evaluated current mainstream LLMs, including both traditional LLMs and recently developed Large Reasoning Models. The results demonstrate the significant necessity for evaluation and model optimization tailored to the Hungarian language and specifics. We also established the framework for analyzing the thinking processes of LRMs with OpenHuEval, revealing intrinsic patterns and mechanisms of these models in non-English languages, with Hungarian serving as a representative example. We will release OpenHuEval at https://github.com/opendatalab/OpenHuEval .
COREval: A Comprehensive and Objective Benchmark for Evaluating the Remote Sensing Capabilities of Large Vision-Language Models
Nov 27, 2024



With the rapid development of Large Vision-Language Models (VLMs), both general-domain models and those specifically tailored for remote sensing Earth observation, have demonstrated exceptional perception and reasoning abilities within this specific field. However, the current absence of a comprehensive benchmark for holistically evaluating the remote sensing capabilities of these VLMs represents a significant gap. To bridge this gap, we propose COREval, the first benchmark designed to comprehensively and objectively evaluate the hierarchical remote sensing capabilities of VLMs. Concentrating on 2 primary capability dimensions essential to remote sensing: perception and reasoning, we further categorize 6 secondary dimensions and 22 leaf tasks to ensure a well-rounded assessment coverage for this specific field. COREval guarantees the quality of the total of 6,263 problems through a rigorous process of data collection from 50 globally distributed cities, question construction and quality control, and the format of multiple-choice questions with definitive answers allows for an objective and straightforward evaluation of VLM performance. We conducted a holistic evaluation of 13 prominent open-source VLMs from both the general and remote sensing domains, highlighting current shortcomings in their remote sensing capabilities and providing directions for improvements in their application within this specialized context. We hope that COREval will serve as a valuable resource and offer deeper insights into the challenges and potential of VLMs in the field of remote sensing.
H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model
Mar 29, 2024



The generic large Vision-Language Models (VLMs) is rapidly developing, but still perform poorly in Remote Sensing (RS) domain, which is due to the unique and specialized nature of RS imagery and the comparatively limited spatial perception of current VLMs. Existing Remote Sensing specific Vision Language Models (RSVLMs) still have considerable potential for improvement, primarily owing to the lack of large-scale, high-quality RS vision-language datasets. We constructed HqDC-1.4M, the large scale High quality and Detailed Captions for RS images, containing 1.4 million image-caption pairs, which not only enhance the RSVLM's understanding of RS images but also significantly improve the model's spatial perception abilities, such as localization and counting, thereby increasing the helpfulness of the RSVLM. Moreover, to address the inevitable "hallucination" problem in RSVLM, we developed RSSA, the first dataset aimed at enhancing the Self-Awareness capability of RSVLMs. By incorporating a variety of unanswerable questions into typical RS visual question-answering tasks, RSSA effectively improves the truthfulness and reduces the hallucinations of the model's outputs, thereby enhancing the honesty of the RSVLM. Based on these datasets, we proposed the H2RSVLM, the Helpful and Honest Remote Sensing Vision Language Model. H2RSVLM has achieved outstanding performance on multiple RS public datasets and is capable of recognizing and refusing to answer the unanswerable questions, effectively mitigating the incorrect generations. We will release the code, data and model weights at https://github.com/opendatalab/H2RSVLM .
Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations
Mar 21, 2024



We introduce CHARM, the first benchmark for comprehensively and in-depth evaluating the commonsense reasoning ability of large language models (LLMs) in Chinese, which covers both globally known and Chinese-specific commonsense. We evaluated 7 English and 12 Chinese-oriented LLMs on CHARM, employing 5 representative prompt strategies for improving LLMs' reasoning ability, such as Chain-of-Thought. Our findings indicate that the LLM's language orientation and the task's domain influence the effectiveness of the prompt strategy, which enriches previous research findings. We built closely-interconnected reasoning and memorization tasks, and found that some LLMs struggle with memorizing Chinese commonsense, affecting their reasoning ability, while others show differences in reasoning despite similar memorization performance. We also evaluated the LLMs' memorization-independent reasoning abilities and analyzed the typical errors. Our study precisely identified the LLMs' strengths and weaknesses, providing the clear direction for optimization. It can also serve as a reference for studies in other fields. We will release CHARM at https://github.com/opendatalab/CHARM .