 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTR-CoT: Graph Traversal as Visual Chain of Thought for Molecular Structure Recognition
Jun 09, 2025



Optical Chemical Structure Recognition (OCSR) is crucial for digitizing chemical knowledge by converting molecular images into machine-readable formats. While recent vision-language models (VLMs) have shown potential in this task, their image-captioning approach often struggles with complex molecular structures and inconsistent annotations. To overcome these challenges, we introduce GTR-Mol-VLM, a novel framework featuring two key innovations: (1) the \textit{Graph Traversal as Visual Chain of Thought} mechanism that emulates human reasoning by incrementally parsing molecular graphs through sequential atom-bond predictions, and (2) the data-centric principle of \textit{Faithfully Recognize What You've Seen}, which addresses the mismatch between abbreviated structures in images and their expanded annotations. To support model development, we constructed GTR-CoT-1.3M, a large-scale instruction-tuning dataset with meticulously corrected annotations, and introduced MolRec-Bench, the first benchmark designed for a fine-grained evaluation of graph-parsing accuracy in OCSR. Comprehensive experiments demonstrate that GTR-Mol-VLM achieves superior results compared to specialist models, chemistry-domain VLMs, and commercial general-purpose VLMs. Notably, in scenarios involving molecular images with functional group abbreviations, GTR-Mol-VLM outperforms the second-best baseline by approximately 14 percentage points, both in SMILES-based and graph-based metrics. We hope that this work will drive OCSR technology to more effectively meet real-world needs, thereby advancing the fields of cheminformatics and AI for Science. We will release GTR-CoT at https://github.com/opendatalab/GTR-CoT.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025



We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
Mar 27, 2025
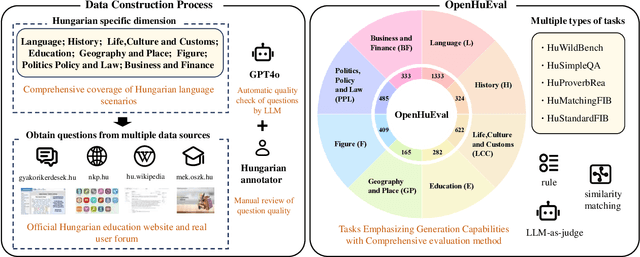


We introduce OpenHuEval, the first benchmark for LLMs focusing on the Hungarian language and specifics. OpenHuEval is constructed from a vast collection of Hungarian-specific materials sourced from multiple origins. In the construction, we incorporated the latest design principles for evaluating LLMs, such as using real user queries from the internet, emphasizing the assessment of LLMs' generative capabilities, and employing LLM-as-judge to enhance the multidimensionality and accuracy of evaluations. Ultimately, OpenHuEval encompasses eight Hungarian-specific dimensions, featuring five tasks and 3953 questions. Consequently, OpenHuEval provides the comprehensive, in-depth, and scientifically accurate assessment of LLM performance in the context of the Hungarian language and its specifics. We evaluated current mainstream LLMs, including both traditional LLMs and recently developed Large Reasoning Models. The results demonstrate the significant necessity for evaluation and model optimization tailored to the Hungarian language and specifics. We also established the framework for analyzing the thinking processes of LRMs with OpenHuEval, revealing intrinsic patterns and mechanisms of these models in non-English languages, with Hungarian serving as a representative example. We will release OpenHuEval at https://github.com/opendatalab/OpenHuEval .
UrBench: A Comprehensive Benchmark for Evaluating Large Multimodal Models in Multi-View Urban Scenarios
Aug 30, 2024Recent evaluations of Large Multimodal Models (LMMs) have explored their capabilities in various domains, with only few benchmarks specifically focusing on urban environments. Moreover, existing urban benchmarks have been limited to evaluating LMMs with basic region-level urban tasks under singular views, leading to incomplete evaluations of LMMs' abilities in urban environments. To address these issues, we present UrBench, a comprehensive benchmark designed for evaluating LMMs in complex multi-view urban scenarios. UrBench contains 11.6K meticulously curated questions at both region-level and role-level that cover 4 task dimensions: Geo-Localization, Scene Reasoning, Scene Understanding, and Object Understanding, totaling 14 task types. In constructing UrBench, we utilize data from existing datasets and additionally collect data from 11 cities, creating new annotations using a cross-view detection-matching method. With these images and annotations, we then integrate LMM-based, rule-based, and human-based methods to construct large-scale high-quality questions. Our evaluations on 21 LMMs show that current LMMs struggle in the urban environments in several aspects. Even the best performing GPT-4o lags behind humans in most tasks, ranging from simple tasks such as counting to complex tasks such as orientation, localization and object attribute recognition, with an average performance gap of 17.4%. Our benchmark also reveals that LMMs exhibit inconsistent behaviors with different urban views, especially with respect to understanding cross-view relations. UrBench datasets and benchmark results will be publicly available at https://opendatalab.github.io/UrBench/.
Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Aug 10, 2024Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at \url{https://github.com/yejy53/EP-BEV}.
SkyDiffusion: Street-to-Satellite Image Synthesis with Diffusion Models and BEV Paradigm
Aug 03, 2024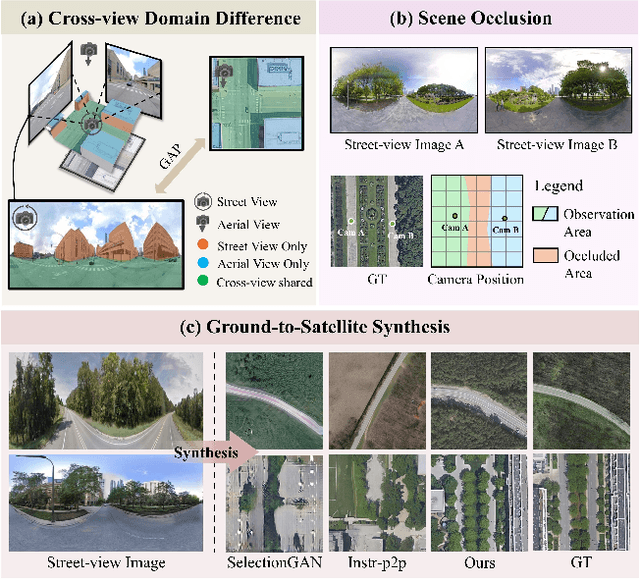



Street-to-satellite image synthesis focuses on generating realistic satellite images from corresponding ground street-view images while maintaining a consistent content layout, similar to looking down from the sky. The significant differences in perspectives create a substantial domain gap between the views, making this cross-view generation task particularly challenging. In this paper, we introduce SkyDiffusion, a novel cross-view generation method for synthesizing satellite images from street-view images, leveraging diffusion models and Bird's Eye View (BEV) paradigm. First, we design a Curved-BEV method to transform street-view images to the satellite view, reformulating the challenging cross-domain image synthesis task into a conditional generation problem. Curved-BEV also includes a "Multi-to-One" mapping strategy for combining multiple street-view images within the same satellite coverage area, effectively solving the occlusion issues in dense urban scenes. Next, we design a BEV-controlled diffusion model to generate satellite images consistent with the street-view content, which also incorporates a light manipulation module to optimize the lighting condition of the synthesized image using a reference satellite. Experimental results demonstrate that SkyDiffusion outperforms state-of-the-art methods on both suburban (CVUSA & CVACT) and urban (VIGOR-Chicago) cross-view datasets, with an average SSIM increase of 14.5% and a FID reduction of 29.6%, achieving realistic and content-consistent satellite image generation. The code and models of this work will be released at https://opendatalab.github.io/skydiffusion/.
3D Building Reconstruction from Monocular Remote Sensing Images with Multi-level Supervisions
Apr 07, 20243D building reconstruction from monocular remote sensing images is an important and challenging research problem that has received increasing attention in recent years, owing to its low cost of data acquisition and availability for large-scale applications. However, existing methods rely on expensive 3D-annotated samples for fully-supervised training, restricting their application to large-scale cross-city scenarios. In this work, we propose MLS-BRN, a multi-level supervised building reconstruction network that can flexibly utilize training samples with different annotation levels to achieve better reconstruction results in an end-to-end manner. To alleviate the demand on full 3D supervision, we design two new modules, Pseudo Building Bbox Calculator and Roof-Offset guided Footprint Extractor, as well as new tasks and training strategies for different types of samples. Experimental results on several public and new datasets demonstrate that our proposed MLS-BRN achieves competitive performance using much fewer 3D-annotated samples, and significantly improves the footprint extraction and 3D reconstruction performance compared with current state-of-the-art. The code and datasets of this work will be released at https://github.com/opendatalab/MLS-BRN.git.