 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGION: Learning to Ground and Explain for Synthetic Image Detection
Mar 19, 2025The rapid advancements in generative technology have emerged as a double-edged sword. While offering powerful tools that enhance convenience, they also pose significant social concerns. As defenders, current synthetic image detection methods often lack artifact-level textual interpretability and are overly focused on image manipulation detection, and current datasets usually suffer from outdated generators and a lack of fine-grained annotations. In this paper, we introduce SynthScars, a high-quality and diverse dataset consisting of 12,236 fully synthetic images with human-expert annotations. It features 4 distinct image content types, 3 categories of artifacts, and fine-grained annotations covering pixel-level segmentation, detailed textual explanations, and artifact category labels. Furthermore, we propose LEGION (LEarning to Ground and explain for Synthetic Image detectiON), a multimodal large language model (MLLM)-based image forgery analysis framework that integrates artifact detection, segmentation, and explanation. Building upon this capability, we further explore LEGION as a controller, integrating it into image refinement pipelines to guide the generation of higher-quality and more realistic images. Extensive experiments show that LEGION outperforms existing methods across multiple benchmarks, particularly surpassing the second-best traditional expert on SynthScars by 3.31% in mIoU and 7.75% in F1 score. Moreover, the refined images generated under its guidance exhibit stronger alignment with human preferences. The code, model, and dataset will be released.
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
Oct 13, 2024
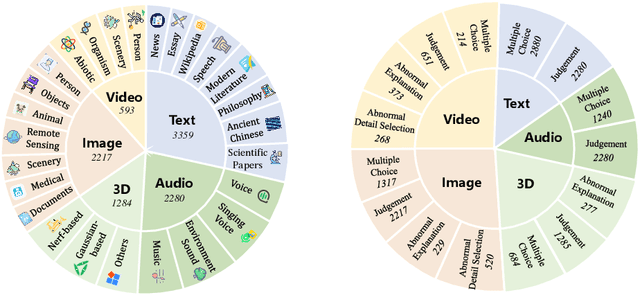

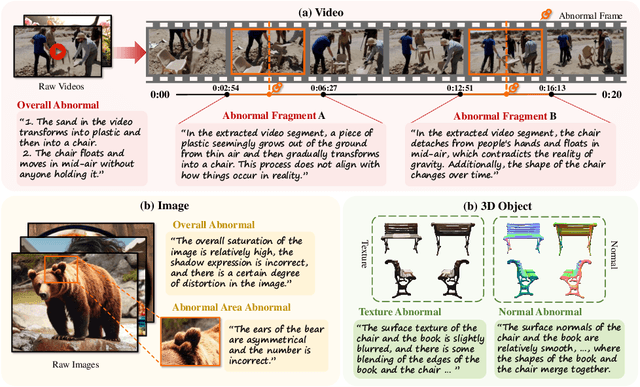
With the rapid development of AI-generated content, the future internet may be inundated with synthetic data, making the discrimination of authentic and credible multimodal data increasingly challenging. Synthetic data detection has thus garnered widespread attention, and the performance of large multimodal models (LMMs) in this task has attracted significant interest. LMMs can provide natural language explanations for their authenticity judgments, enhancing the explainability of synthetic content detection. Simultaneously, the task of distinguishing between real and synthetic data effectively tests the perception, knowledge, and reasoning capabilities of LMMs. In response, we introduce LOKI, a novel benchmark designed to evaluate the ability of LMMs to detect synthetic data across multiple modalities. LOKI encompasses video, image, 3D, text, and audio modalities, comprising 18K carefully curated questions across 26 subcategories with clear difficulty levels. The benchmark includes coarse-grained judgment and multiple-choice questions, as well as fine-grained anomaly selection and explanation tasks, allowing for a comprehensive analysis of LMMs. We evaluated 22 open-source LMMs and 6 closed-source models on LOKI, highlighting their potential as synthetic data detectors and also revealing some limitations in the development of LMM capabilities. More information about LOKI can be found at https://opendatalab.github.io/LOKI/
UrBench: A Comprehensive Benchmark for Evaluating Large Multimodal Models in Multi-View Urban Scenarios
Aug 30, 2024Recent evaluations of Large Multimodal Models (LMMs) have explored their capabilities in various domains, with only few benchmarks specifically focusing on urban environments. Moreover, existing urban benchmarks have been limited to evaluating LMMs with basic region-level urban tasks under singular views, leading to incomplete evaluations of LMMs' abilities in urban environments. To address these issues, we present UrBench, a comprehensive benchmark designed for evaluating LMMs in complex multi-view urban scenarios. UrBench contains 11.6K meticulously curated questions at both region-level and role-level that cover 4 task dimensions: Geo-Localization, Scene Reasoning, Scene Understanding, and Object Understanding, totaling 14 task types. In constructing UrBench, we utilize data from existing datasets and additionally collect data from 11 cities, creating new annotations using a cross-view detection-matching method. With these images and annotations, we then integrate LMM-based, rule-based, and human-based methods to construct large-scale high-quality questions. Our evaluations on 21 LMMs show that current LMMs struggle in the urban environments in several aspects. Even the best performing GPT-4o lags behind humans in most tasks, ranging from simple tasks such as counting to complex tasks such as orientation, localization and object attribute recognition, with an average performance gap of 17.4%. Our benchmark also reveals that LMMs exhibit inconsistent behaviors with different urban views, especially with respect to understanding cross-view relations. UrBench datasets and benchmark results will be publicly available at https://opendatalab.github.io/UrBench/.
TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models
May 20, 2024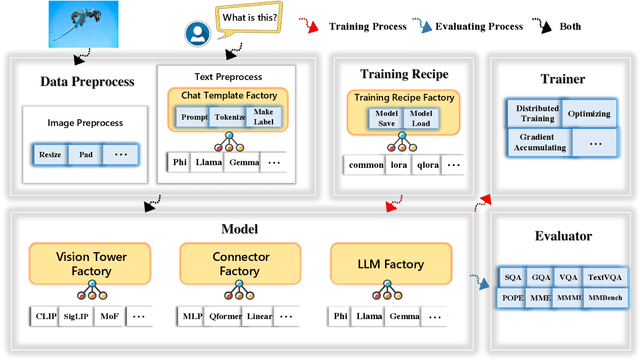
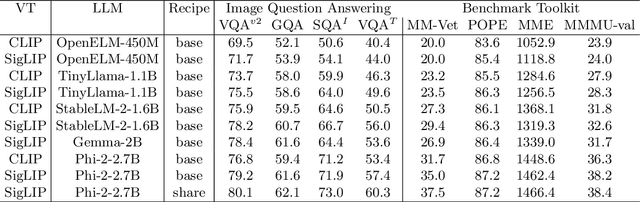
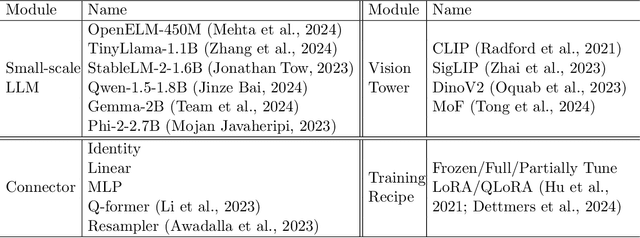
We present TinyLLaVA Factory, an open-source modular codebase for small-scale large multimodal models (LMMs) with a focus on simplicity of code implementations, extensibility of new features, and reproducibility of training results. Following the design philosophy of the factory pattern in software engineering, TinyLLaVA Factory modularizes the entire system into interchangeable components, with each component integrating a suite of cutting-edge models and methods, meanwhile leaving room for extensions to more features. In addition to allowing users to customize their own LMMs, TinyLLaVA Factory provides popular training recipes to let users pretrain and finetune their models with less coding effort. Empirical experiments validate the effectiveness of our codebase. The goal of TinyLLaVA Factory is to assist researchers and practitioners in exploring the wide landscape of designing and training small-scale LMMs with affordable computational resources.
TinyLLaVA: A Framework of Small-scale Large Multimodal Models
Feb 22, 2024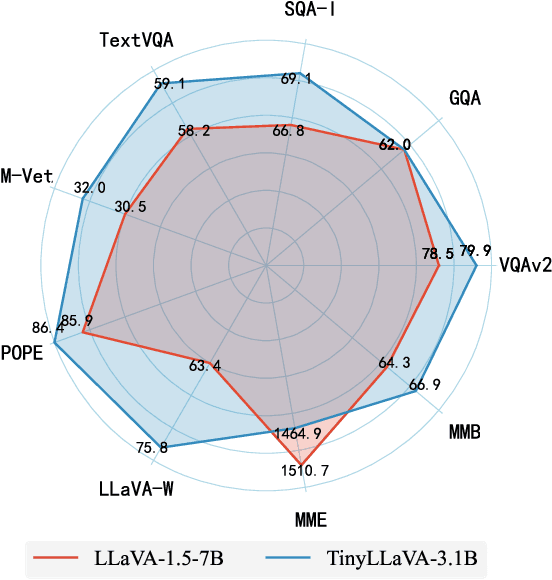
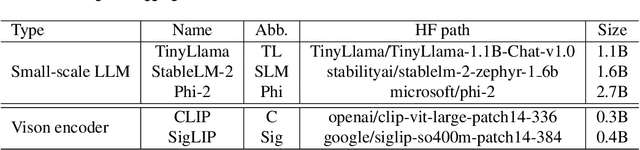
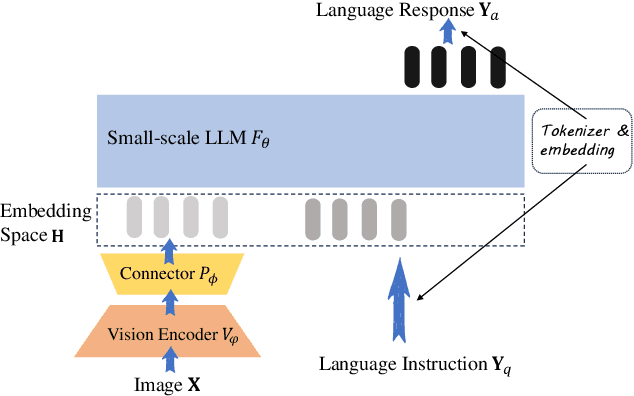

We present the TinyLLaVA framework that provides a unified perspective in designing and analyzing the small-scale Large Multimodal Models (LMMs). We empirically study the effects of different vision encoders, connection modules, language models, training data and training recipes. Our extensive experiments showed that better quality of data combined with better training recipes, smaller LMMs can consistently achieve on-par performances compared to bigger LMMs. Under our framework, we train a family of small-scale LMMs. Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. We hope our findings can serve as baselines for future research in terms of data scaling, training setups and model selections. Our model weights and codes will be made public.