 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicyLong: Towards On-Policy Context Extension
Apr 09, 2026Extending LLM context windows is hindered by scarce high-quality long-context data. Recent methods synthesize data with genuine long-range dependencies via information-theoretic verification, selecting contexts that reduce a base model's predictive entropy. However, their single-pass offline construction with a fixed model creates a fundamental off-policy gap: the static screening landscape misaligns with the model's evolving capabilities, causing the training distribution to drift. We propose PolicyLong, shifting data construction towards a dynamic on-policy paradigm. By iteratively re-executing data screening (entropy computation, retrieval, and verification) using the current model, PolicyLong ensures the training distribution tracks evolving capabilities, yielding an emergent self-curriculum. Crucially, both positive and hard negative contexts derive from the current model's entropy landscape, co-evolving what the model learns to exploit and resist. Experiments on RULER, HELMET, and LongBench-v2 (Qwen2.5-3B) show PolicyLong consistently outperforms EntropyLong and NExtLong, with gains growing at longer contexts (e.g., +2.54 at 128K on RULER), confirming the value of on-policy data evolution.
LongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
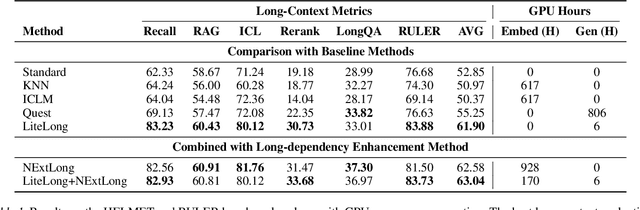


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
On the Nonlinearity of Layer Normalization
Jun 03, 2024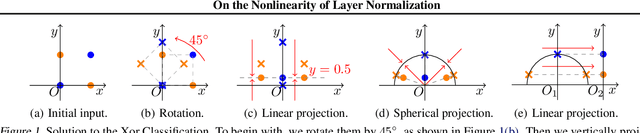
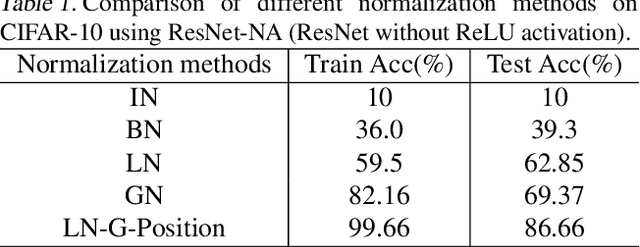
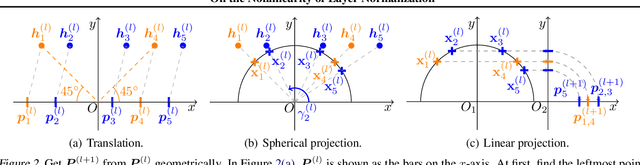
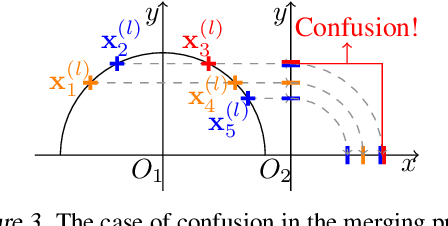
Layer normalization (LN) is a ubiquitous technique in deep learning but our theoretical understanding to it remains elusive. This paper investigates a new theoretical direction for LN, regarding to its nonlinearity and representation capacity. We investigate the representation capacity of a network with layerwise composition of linear and LN transformations, referred to as LN-Net. We theoretically show that, given $m$ samples with any label assignment, an LN-Net with only 3 neurons in each layer and $O(m)$ LN layers can correctly classify them. We further show the lower bound of the VC dimension of an LN-Net. The nonlinearity of LN can be amplified by group partition, which is also theoretically demonstrated with mild assumption and empirically supported by our experiments. Based on our analyses, we consider to design neural architecture by exploiting and amplifying the nonlinearity of LN, and the effectiveness is supported by our experiments.
TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models
May 20, 2024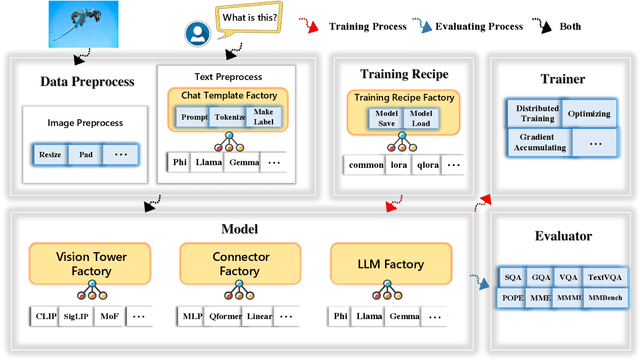
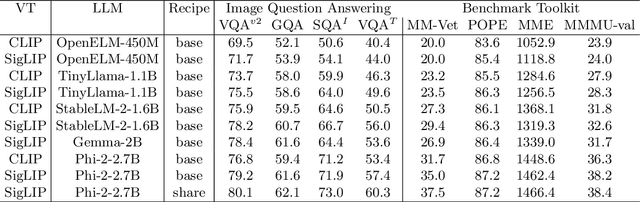
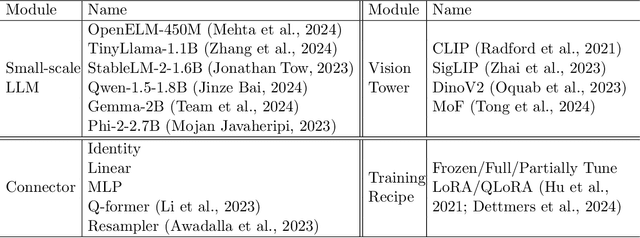
We present TinyLLaVA Factory, an open-source modular codebase for small-scale large multimodal models (LMMs) with a focus on simplicity of code implementations, extensibility of new features, and reproducibility of training results. Following the design philosophy of the factory pattern in software engineering, TinyLLaVA Factory modularizes the entire system into interchangeable components, with each component integrating a suite of cutting-edge models and methods, meanwhile leaving room for extensions to more features. In addition to allowing users to customize their own LMMs, TinyLLaVA Factory provides popular training recipes to let users pretrain and finetune their models with less coding effort. Empirical experiments validate the effectiveness of our codebase. The goal of TinyLLaVA Factory is to assist researchers and practitioners in exploring the wide landscape of designing and training small-scale LMMs with affordable computational resources.
TinyLLaVA: A Framework of Small-scale Large Multimodal Models
Feb 22, 2024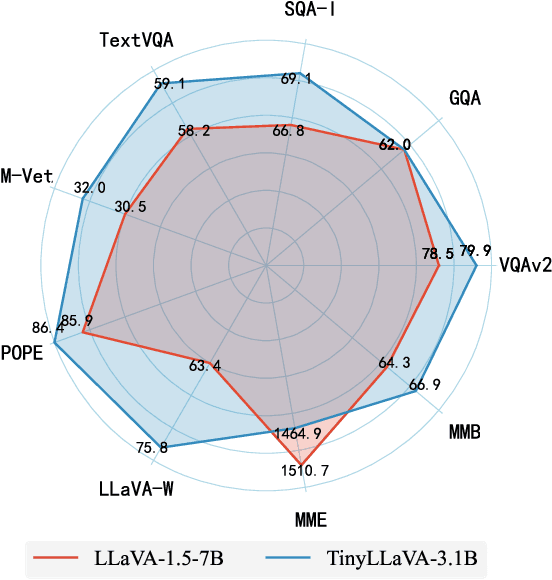
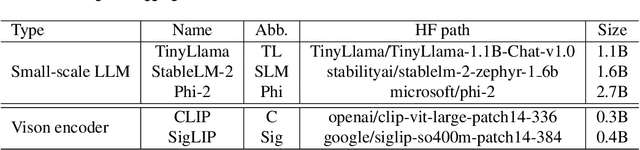
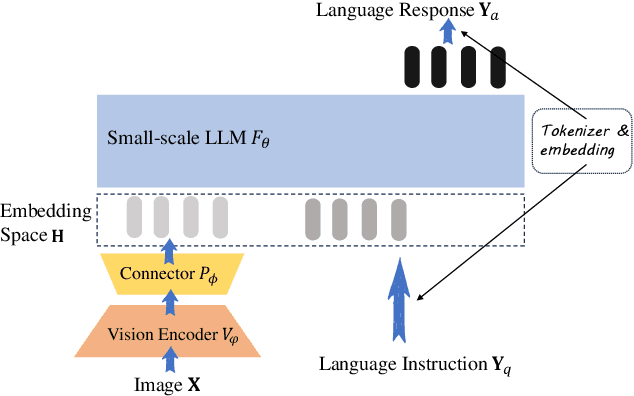

We present the TinyLLaVA framework that provides a unified perspective in designing and analyzing the small-scale Large Multimodal Models (LMMs). We empirically study the effects of different vision encoders, connection modules, language models, training data and training recipes. Our extensive experiments showed that better quality of data combined with better training recipes, smaller LMMs can consistently achieve on-par performances compared to bigger LMMs. Under our framework, we train a family of small-scale LMMs. Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. We hope our findings can serve as baselines for future research in terms of data scaling, training setups and model selections. Our model weights and codes will be made public.