 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Adaptive Side Information Fusion for Sequential Recommendation
Dec 30, 2025Incorporating item-side information, such as category and brand, into sequential recommendation is a well-established and effective approach for improving performance. However, despite significant advancements, current models are generally limited by three key challenges: they often overlook the fine-grained temporal dynamics inherent in timestamps, exhibit vulnerability to noise in user interaction sequences, and rely on computationally expensive fusion architectures. To systematically address these challenges, we propose the Time-Aware Adaptive Side Information Fusion (TASIF) framework. TASIF integrates three synergistic components: (1) a simple, plug-and-play time span partitioning mechanism to capture global temporal patterns; (2) an adaptive frequency filter that leverages a learnable gate to denoise feature sequences adaptively, thereby providing higher-quality inputs for subsequent fusion modules; and (3) an efficient adaptive side information fusion layer, this layer employs a "guide-not-mix" architecture, where attributes guide the attention mechanism without being mixed into the content-representing item embeddings, ensuring deep interaction while ensuring computational efficiency. Extensive experiments on four public datasets demonstrate that TASIF significantly outperforms state-of-the-art baselines while maintaining excellent efficiency in training. Our source code is available at https://github.com/jluo00/TASIF.
Mip-NeWRF: Enhanced Wireless Radiance Field with Hybrid Encoding for Channel Prediction
Nov 12, 2025Recent work on wireless radiance fields represents a promising deep learning approach for channel prediction, however, in complex environments these methods still exhibit limited robustness, slow convergence, and modest accuracy due to insufficiently refined modeling. To address this issue, we propose Mip-NeWRF, a physics-informed neural framework for accurate indoor channel prediction based on sparse channel measurements. The framework operates in a ray-based pipeline with coarse-to-fine importance sampling: frustum samples are encoded, processed by a shared multilayer perceptron (MLP), and the outputs are synthesized into the channel frequency response (CFR). Prior to MLP input, Mip-NeWRF performs conical-frustum sampling and applies a scale-consistent hybrid positional encoding to each frustum. The scale-consistent normalization aligns positional encodings across scene scales, while the hybrid encoding supplies both scale-robust, low-frequency stability to accelerate convergence and fine spatial detail to improve accuracy. During training, a curriculum learning schedule is applied to stabilize and accelerate convergence of the shared MLP. During channel synthesis, the MLP outputs, including predicted virtual transmitter presence probabilities and amplitudes, are combined with modeled pathloss and surface interaction attenuation to enhance physical fidelity and further improve accuracy. Simulation results demonstrate the effectiveness of the proposed approach: in typical scenarios, the normalized mean square error (NMSE) is reduced by 14.3 dB versus state-of-the-art baselines.
Vulnerable Agent Identification in Large-Scale Multi-Agent Reinforcement Learning
Sep 18, 2025Partial agent failure becomes inevitable when systems scale up, making it crucial to identify the subset of agents whose compromise would most severely degrade overall performance. In this paper, we study this Vulnerable Agent Identification (VAI) problem in large-scale multi-agent reinforcement learning (MARL). We frame VAI as a Hierarchical Adversarial Decentralized Mean Field Control (HAD-MFC), where the upper level involves an NP-hard combinatorial task of selecting the most vulnerable agents, and the lower level learns worst-case adversarial policies for these agents using mean-field MARL. The two problems are coupled together, making HAD-MFC difficult to solve. To solve this, we first decouple the hierarchical process by Fenchel-Rockafellar transform, resulting a regularized mean-field Bellman operator for upper level that enables independent learning at each level, thus reducing computational complexity. We then reformulate the upper-level combinatorial problem as a MDP with dense rewards from our regularized mean-field Bellman operator, enabling us to sequentially identify the most vulnerable agents by greedy and RL algorithms. This decomposition provably preserves the optimal solution of the original HAD-MFC. Experiments show our method effectively identifies more vulnerable agents in large-scale MARL and the rule-based system, fooling system into worse failures, and learns a value function that reveals the vulnerability of each agent.
Symmetry-Guided Multi-Agent Inverse Reinforcement Learning
Sep 11, 2025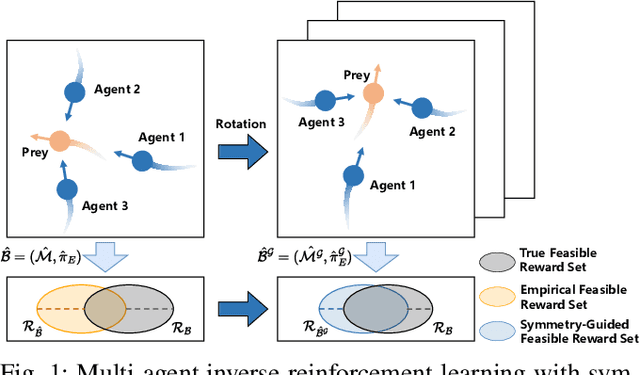
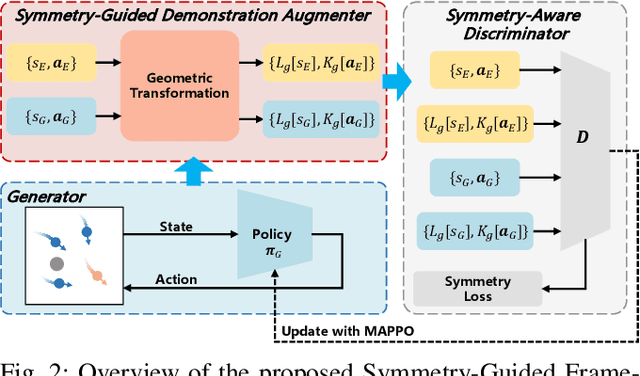
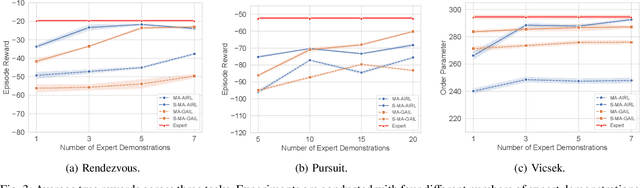
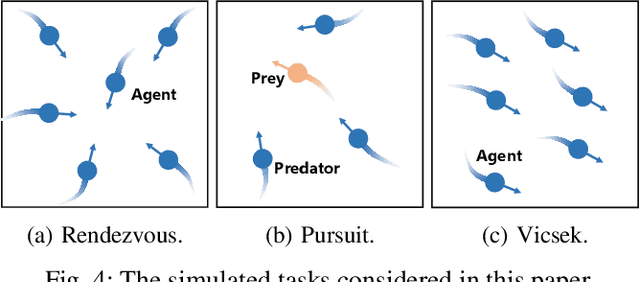
In robotic systems, the performance of reinforcement learning depends on the rationality of predefined reward functions. However, manually designed reward functions often lead to policy failures due to inaccuracies. Inverse Reinforcement Learning (IRL) addresses this problem by inferring implicit reward functions from expert demonstrations. Nevertheless, existing methods rely heavily on large amounts of expert demonstrations to accurately recover the reward function. The high cost of collecting expert demonstrations in robotic applications, particularly in multi-robot systems, severely hinders the practical deployment of IRL. Consequently, improving sample efficiency has emerged as a critical challenge in multi-agent inverse reinforcement learning (MIRL). Inspired by the symmetry inherent in multi-agent systems, this work theoretically demonstrates that leveraging symmetry enables the recovery of more accurate reward functions. Building upon this insight, we propose a universal framework that integrates symmetry into existing multi-agent adversarial IRL algorithms, thereby significantly enhancing sample efficiency. Experimental results from multiple challenging tasks have demonstrated the effectiveness of this framework. Further validation in physical multi-robot systems has shown the practicality of our method.
Drive Any Mesh: 4D Latent Diffusion for Mesh Deformation from Video
Jun 09, 2025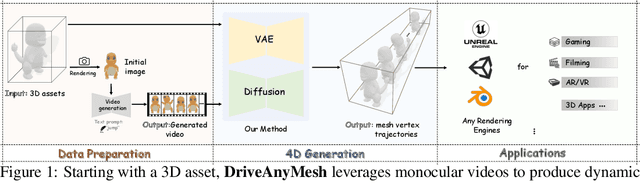



We propose DriveAnyMesh, a method for driving mesh guided by monocular video. Current 4D generation techniques encounter challenges with modern rendering engines. Implicit methods have low rendering efficiency and are unfriendly to rasterization-based engines, while skeletal methods demand significant manual effort and lack cross-category generalization. Animating existing 3D assets, instead of creating 4D assets from scratch, demands a deep understanding of the input's 3D structure. To tackle these challenges, we present a 4D diffusion model that denoises sequences of latent sets, which are then decoded to produce mesh animations from point cloud trajectory sequences. These latent sets leverage a transformer-based variational autoencoder, simultaneously capturing 3D shape and motion information. By employing a spatiotemporal, transformer-based diffusion model, information is exchanged across multiple latent frames, enhancing the efficiency and generalization of the generated results. Our experimental results demonstrate that DriveAnyMesh can rapidly produce high-quality animations for complex motions and is compatible with modern rendering engines. This method holds potential for applications in both the gaming and filming industries.
VoQA: Visual-only Question Answering
May 20, 2025We propose Visual-only Question Answering (VoQA), a novel multimodal task in which questions are visually embedded within images, without any accompanying textual input. This requires models to locate, recognize, and reason over visually embedded textual questions, posing challenges for existing large vision-language models (LVLMs), which show notable performance drops even with carefully designed prompts. To bridge this gap, we introduce Guided Response Triggering Supervised Fine-tuning (GRT-SFT), a structured fine-tuning strategy that guides the model to perform step-by-step reasoning purely based on visual input, significantly improving model performance. Our work enhances models' capacity for human-like visual understanding in complex multimodal scenarios, where information, including language, is perceived visually.
Enhancing the Efficiency of Complex Systems Crystal Structure Prediction by Active Learning Guided Machine Learning Potential
May 13, 2025Understanding multicomponent complex material systems is essential for design of advanced materials for a wide range of technological applications. While state-of-the-art crystal structure prediction (CSP) methods effectively identify new structures and assess phase stability, they face fundamental limitations when applied to complex systems. This challenge stems from the combinatorial explosion of atomic configurations and the vast stoichiometric space, both of which contribute to computational demands that rapidly exceed practical feasibility. In this work, we propose a flexible and automated workflow to build a highly generalizable and data-efficient machine learning potential (MLP), effectively unlocking the full potential of CSP algorithms. The workflow is validated on both Mg-Ca-H ternary and Be-P-N-O quaternary systems, demonstrating substantial machine learning acceleration in high-throughput structural optimization and enabling the efficient identification of promising compounds. These results underscore the effectiveness of our approach in exploring complex material systems and accelerating the discovery of new multicomponent materials.
An Empirical Study of Qwen3 Quantization
May 04, 2025The Qwen series has emerged as a leading family of open-source Large Language Models (LLMs), demonstrating remarkable capabilities in natural language understanding tasks. With the recent release of Qwen3, which exhibits superior performance across diverse benchmarks, there is growing interest in deploying these models efficiently in resource-constrained environments. Low-bit quantization presents a promising solution, yet its impact on Qwen3's performance remains underexplored. This study conducts a systematic evaluation of Qwen3's robustness under various quantization settings, aiming to uncover both opportunities and challenges in compressing this state-of-the-art model. We rigorously assess 5 existing classic post-training quantization techniques applied to Qwen3, spanning bit-widths from 1 to 8 bits, and evaluate their effectiveness across multiple datasets. Our findings reveal that while Qwen3 maintains competitive performance at moderate bit-widths, it experiences notable degradation in linguistic tasks under ultra-low precision, underscoring the persistent hurdles in LLM compression. These results emphasize the need for further research to mitigate performance loss in extreme quantization scenarios. We anticipate that this empirical analysis will provide actionable insights for advancing quantization methods tailored to Qwen3 and future LLMs, ultimately enhancing their practicality without compromising accuracy. Our project is released on https://github.com/Efficient-ML/Qwen3-Quantization and https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b.
1-Tb/s/λ Transmission over Record 10714-km AR-HCF
Apr 02, 2025We present the first single-channel 1.001-Tb/s DP-36QAM-PCS recirculating transmission over 73 loops of 146.77-km ultra-low-loss & low-IMI DNANF-5 fiber, achieving a record transmission distance of 10,714.28 km.
Coarse-to-Fine Semantic Communication Systems for Text Transmission
Apr 02, 2025



Achieving more powerful semantic representations and semantic understanding is one of the key problems in improving the performance of semantic communication systems. This work focuses on enhancing the semantic understanding of the text data to improve the effectiveness of semantic exchange. We propose a novel semantic communication system for text transmission, in which the semantic understanding is enhanced by coarse-to-fine processing. Especially, a dual attention mechanism is proposed to capture both the coarse and fine semantic information. Numerical experiments show the proposed system outperforms the benchmarks in terms of bilingual evaluation, sentence similarity, and robustness under various channel conditions.