 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBin~Wan,G2HFNet: GeoGran-Aware Hierarchical Feature Fusion Network for Salient Object Detection in Optical Remote Sensing Images
Mar 13, 2026Remote sensing images captured from aerial perspectives often exhibit significant scale variations and complex backgrounds, posing challenges for salient object detection (SOD). Existing methods typically extract multi-level features at a single scale using uniform attention mechanisms, leading to suboptimal representations and incomplete detection results. To address these issues, we propose a GeoGran-Aware Hierarchical Feature Fusion Network (G2HFNet) that fully exploits geometric and granular cues in optical remote sensing images. Specifically, G2HFNet adopts Swin Transformer as the backbone to extract multi-level features and integrates three key modules: the multi-scale detail enhancement (MDE) module to handle object scale variations and enrich fine details, the dual-branch geo-gran complementary (DGC) module to jointly capture fine-grained details and positional information in mid-level features, and the deep semantic perception (DSP) module to refine high-level positional cues via self-attention. Additionally, a local-global guidance fusion (LGF) module is introduced to replace traditional convolutions for effective multi-level feature integration. Extensive experiments demonstrate that G2HFNet achieves high-quality saliency maps and significantly improves detection performance in challenging remote sensing scenarios.
RSONet: Region-guided Selective Optimization Network for RGB-T Salient Object Detection
Mar 13, 2026This paper focuses on the inconsistency in salient regions between RGB and thermal images. To address this issue, we propose the Region-guided Selective Optimization Network for RGB-T Salient Object Detection, which consists of the region guidance stage and saliency generation stage. In the region guidance stage, three parallel branches with same encoder-decoder structure equipped with the context interaction (CI) module and spatial-aware fusion (SF) module are designed to generate the guidance maps which are leveraged to calculate similarity scores. Then, in the saliency generation stage, the selective optimization (SO) module fuses RGB and thermal features based on the previously obtained similarity values to mitigate the impact of inconsistent distribution of salient targets between the two modalities. After that, to generate high-quality detection result, the dense detail enhancement (DDE) module which adopts the multiple dense connections and visual state space blocks is applied to low-level features for optimizing the detail information. In addition, the mutual interaction semantic (MIS) module is placed in the high-level features to dig the location cues by the mutual fusion strategy. We conduct extensive experiments on the RGB-T dataset, and the results demonstrate that the proposed RSONet achieves competitive performance against 27 state-of-the-art SOD methods.
Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Feb 04, 2026Advanced autoregressive (AR) video generation models have improved visual fidelity and interactivity, but the quadratic complexity of attention remains a primary bottleneck for efficient deployment. While existing sparse attention solutions have shown promise on bidirectional models, we identify that applying these solutions to AR models leads to considerable performance degradation for two reasons: isolated consideration of chunk generation and insufficient utilization of past informative context. Motivated by these observations, we propose \textsc{Light Forcing}, the \textit{first} sparse attention solution tailored for AR video generation models. It incorporates a \textit{Chunk-Aware Growth} mechanism to quantitatively estimate the contribution of each chunk, which determines their sparsity allocation. This progressive sparsity increase strategy enables the current chunk to inherit prior knowledge in earlier chunks during generation. Additionally, we introduce a \textit{Hierarchical Sparse Attention} to capture informative historical and local context in a coarse-to-fine manner. Such two-level mask selection strategy (\ie, frame and block level) can adaptively handle diverse attention patterns. Extensive experiments demonstrate that our method outperforms existing sparse attention in quality (\eg, 84.5 on VBench) and efficiency (\eg, $1.2{\sim}1.3\times$ end-to-end speedup). Combined with FP8 quantization and LightVAE, \textsc{Light Forcing} further achieves a $2.3\times$ speedup and 19.7\,FPS on an RTX~5090 GPU. Code will be released at \href{https://github.com/chengtao-lv/LightForcing}{https://github.com/chengtao-lv/LightForcing}.
LLMC+: Benchmarking Vision-Language Model Compression with a Plug-and-play Toolkit
Aug 13, 2025Large Vision-Language Models (VLMs) exhibit impressive multi-modal capabilities but suffer from prohibitive computational and memory demands, due to their long visual token sequences and massive parameter sizes. To address these issues, recent works have proposed training-free compression methods. However, existing efforts often suffer from three major limitations: (1) Current approaches do not decompose techniques into comparable modules, hindering fair evaluation across spatial and temporal redundancy. (2) Evaluation confined to simple single-turn tasks, failing to reflect performance in realistic scenarios. (3) Isolated use of individual compression techniques, without exploring their joint potential. To overcome these gaps, we introduce LLMC+, a comprehensive VLM compression benchmark with a versatile, plug-and-play toolkit. LLMC+ supports over 20 algorithms across five representative VLM families and enables systematic study of token-level and model-level compression. Our benchmark reveals that: (1) Spatial and temporal redundancies demand distinct technical strategies. (2) Token reduction methods degrade significantly in multi-turn dialogue and detail-sensitive tasks. (3) Combining token and model compression achieves extreme compression with minimal performance loss. We believe LLMC+ will facilitate fair evaluation and inspire future research in efficient VLM. Our code is available at https://github.com/ModelTC/LightCompress.
QVGen: Pushing the Limit of Quantized Video Generative Models
May 16, 2025Video diffusion models (DMs) have enabled high-quality video synthesis. Yet, their substantial computational and memory demands pose serious challenges to real-world deployment, even on high-end GPUs. As a commonly adopted solution, quantization has proven notable success in reducing cost for image DMs, while its direct application to video DMs remains ineffective. In this paper, we present QVGen, a novel quantization-aware training (QAT) framework tailored for high-performance and inference-efficient video DMs under extremely low-bit quantization (e.g., 4-bit or below). We begin with a theoretical analysis demonstrating that reducing the gradient norm is essential to facilitate convergence for QAT. To this end, we introduce auxiliary modules ($\Phi$) to mitigate large quantization errors, leading to significantly enhanced convergence. To eliminate the inference overhead of $\Phi$, we propose a rank-decay strategy that progressively eliminates $\Phi$. Specifically, we repeatedly employ singular value decomposition (SVD) and a proposed rank-based regularization $\mathbf{\gamma}$ to identify and decay low-contributing components. This strategy retains performance while zeroing out inference overhead. Extensive experiments across $4$ state-of-the-art (SOTA) video DMs, with parameter sizes ranging from $1.3$B $\sim14$B, show that QVGen is the first to reach full-precision comparable quality under 4-bit settings. Moreover, it significantly outperforms existing methods. For instance, our 3-bit CogVideoX-2B achieves improvements of $+25.28$ in Dynamic Degree and $+8.43$ in Scene Consistency on VBench.
A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms
Sep 25, 2024



Large language models (LLMs) have achieved remarkable advancements in natural language processing, showcasing exceptional performance across various tasks. However, the expensive memory and computational requirements present significant challenges for their practical deployment. Low-bit quantization has emerged as a critical approach to mitigate these challenges by reducing the bit-width of model parameters, activations, and gradients, thus decreasing memory usage and computational demands. This paper presents a comprehensive survey of low-bit quantization methods tailored for LLMs, covering the fundamental principles, system implementations, and algorithmic strategies. An overview of basic concepts and new data formats specific to low-bit LLMs is first introduced, followed by a review of frameworks and systems that facilitate low-bit LLMs across various hardware platforms. Then, we categorize and analyze techniques and toolkits for efficient low-bit training and inference of LLMs. Finally, we conclude with a discussion of future trends and potential advancements of low-bit LLMs. Our systematic overview from basic, system, and algorithm perspectives can offer valuable insights and guidelines for future works to enhance the efficiency and applicability of LLMs through low-bit quantization.
QVD: Post-training Quantization for Video Diffusion Models
Jul 16, 2024Recently, video diffusion models (VDMs) have garnered significant attention due to their notable advancements in generating coherent and realistic video content. However, processing multiple frame features concurrently, coupled with the considerable model size, results in high latency and extensive memory consumption, hindering their broader application. Post-training quantization (PTQ) is an effective technique to reduce memory footprint and improve computational efficiency. Unlike image diffusion, we observe that the temporal features, which are integrated into all frame features, exhibit pronounced skewness. Furthermore, we investigate significant inter-channel disparities and asymmetries in the activation of video diffusion models, resulting in low coverage of quantization levels by individual channels and increasing the challenge of quantization. To address these issues, we introduce the first PTQ strategy tailored for video diffusion models, dubbed QVD. Specifically, we propose the High Temporal Discriminability Quantization (HTDQ) method, designed for temporal features, which retains the high discriminability of quantized features, providing precise temporal guidance for all video frames. In addition, we present the Scattered Channel Range Integration (SCRI) method which aims to improve the coverage of quantization levels across individual channels. Experimental validations across various models, datasets, and bit-width settings demonstrate the effectiveness of our QVD in terms of diverse metrics. In particular, we achieve near-lossless performance degradation on W8A8, outperforming the current methods by 205.12 in FVD.
PTQ4SAM: Post-Training Quantization for Segment Anything
May 06, 2024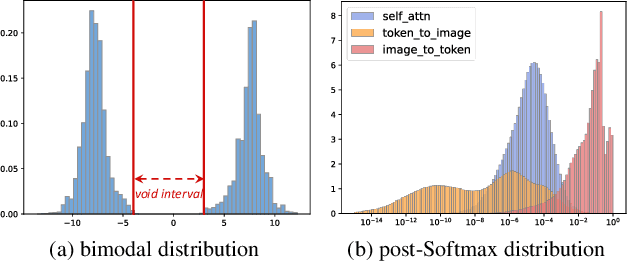
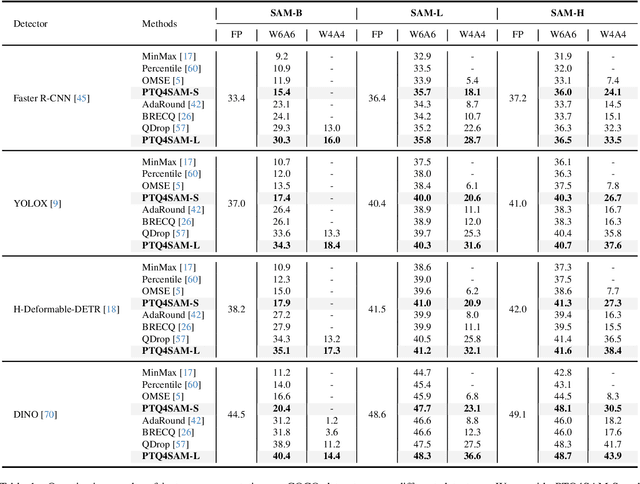
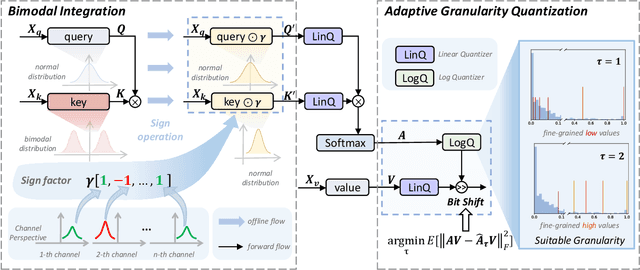
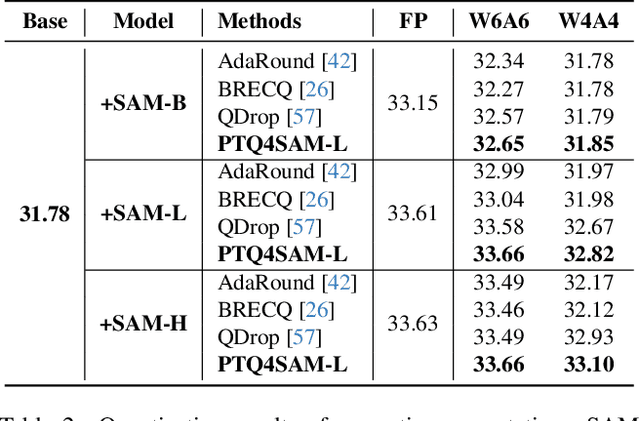
Segment Anything Model (SAM) has achieved impressive performance in many computer vision tasks. However, as a large-scale model, the immense memory and computation costs hinder its practical deployment. In this paper, we propose a post-training quantization (PTQ) framework for Segment Anything Model, namely PTQ4SAM. First, we investigate the inherent bottleneck of SAM quantization attributed to the bimodal distribution in post-Key-Linear activations. We analyze its characteristics from both per-tensor and per-channel perspectives, and propose a Bimodal Integration strategy, which utilizes a mathematically equivalent sign operation to transform the bimodal distribution into a relatively easy-quantized normal distribution offline. Second, SAM encompasses diverse attention mechanisms (i.e., self-attention and two-way cross-attention), resulting in substantial variations in the post-Softmax distributions. Therefore, we introduce an Adaptive Granularity Quantization for Softmax through searching the optimal power-of-two base, which is hardware-friendly. Extensive experimental results across various vision tasks (instance segmentation, semantic segmentation and object detection), datasets and model variants show the superiority of PTQ4SAM. For example, when quantizing SAM-L to 6-bit, we achieve lossless accuracy for instance segmentation, about 0.5\% drop with theoretical 3.9$\times$ acceleration. The code is available at \url{https://github.com/chengtao-lv/PTQ4SAM}.
How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study
Apr 22, 2024Meta's LLaMA family has become one of the most powerful open-source Large Language Model (LLM) series. Notably, LLaMA3 models have recently been released and achieve impressive performance across various with super-large scale pre-training on over 15T tokens of data. Given the wide application of low-bit quantization for LLMs in resource-limited scenarios, we explore LLaMA3's capabilities when quantized to low bit-width. This exploration holds the potential to unveil new insights and challenges for low-bit quantization of LLaMA3 and other forthcoming LLMs, especially in addressing performance degradation problems that suffer in LLM compression. Specifically, we evaluate the 10 existing post-training quantization and LoRA-finetuning methods of LLaMA3 on 1-8 bits and diverse datasets to comprehensively reveal LLaMA3's low-bit quantization performance. Our experiment results indicate that LLaMA3 still suffers non-negligent degradation in these scenarios, especially in ultra-low bit-width. This highlights the significant performance gap under low bit-width that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, pushing the LLMs to lower bit-width with higher accuracy for being practical. Our project is released on https://github.com/Macaronlin/LLaMA3-Quantization and quantized LLaMA3 models are released in https://huggingface.co/LLMQ.
DB-LLM: Accurate Dual-Binarization for Efficient LLMs
Feb 19, 2024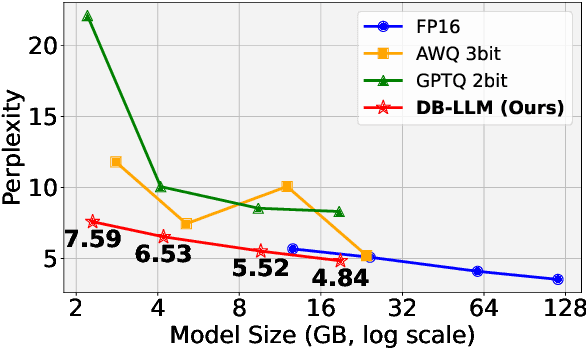
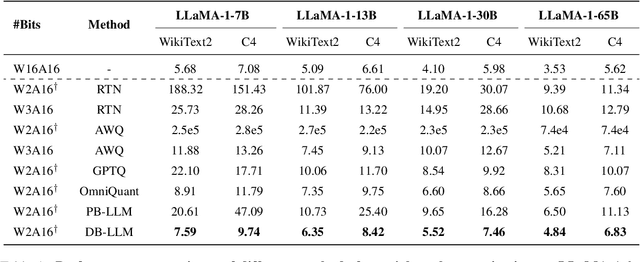
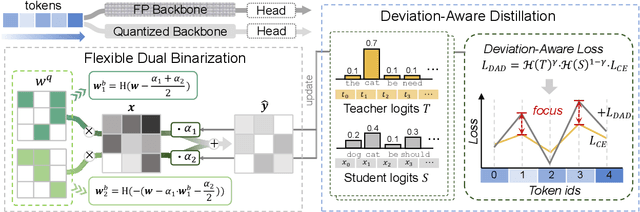
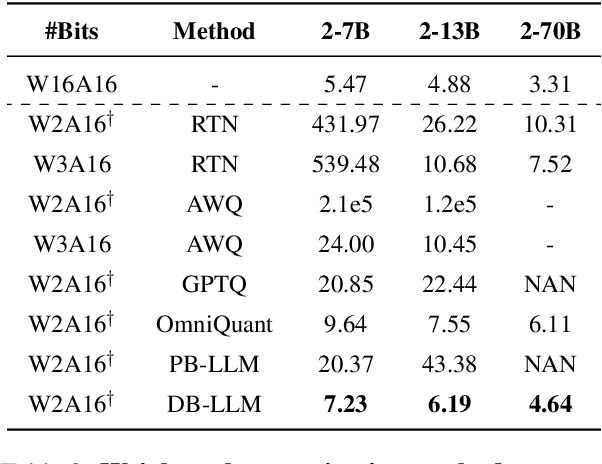
Large language models (LLMs) have significantly advanced the field of natural language processing, while the expensive memory and computation consumption impede their practical deployment. Quantization emerges as one of the most effective methods for improving the computational efficiency of LLMs. However, existing ultra-low-bit quantization always causes severe accuracy drops. In this paper, we empirically relieve the micro and macro characteristics of ultra-low bit quantization and present a novel Dual-Binarization method for LLMs, namely DB-LLM. For the micro-level, we take both the accuracy advantage of 2-bit-width and the efficiency advantage of binarization into account, introducing Flexible Dual Binarization (FDB). By splitting 2-bit quantized weights into two independent sets of binaries, FDB ensures the accuracy of representations and introduces flexibility, utilizing the efficient bitwise operations of binarization while retaining the inherent high sparsity of ultra-low bit quantization. For the macro-level, we find the distortion that exists in the prediction of LLM after quantization, which is specified as the deviations related to the ambiguity of samples. We propose the Deviation-Aware Distillation (DAD) method, enabling the model to focus differently on various samples. Comprehensive experiments show that our DB-LLM not only significantly surpasses the current State-of-The-Art (SoTA) in ultra-low bit quantization (eg, perplexity decreased from 9.64 to 7.23), but also achieves an additional 20\% reduction in computational consumption compared to the SOTA method under the same bit-width. Our code will be released soon.