 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-SAM3D: 3Dfy Anything in Images but Faster
Feb 05, 2026SAM3D enables scalable, open-world 3D reconstruction from complex scenes, yet its deployment is hindered by prohibitive inference latency. In this work, we conduct the \textbf{first systematic investigation} into its inference dynamics, revealing that generic acceleration strategies are brittle in this context. We demonstrate that these failures stem from neglecting the pipeline's inherent multi-level \textbf{heterogeneity}: the kinematic distinctiveness between shape and layout, the intrinsic sparsity of texture refinement, and the spectral variance across geometries. To address this, we present \textbf{Fast-SAM3D}, a training-free framework that dynamically aligns computation with instantaneous generation complexity. Our approach integrates three heterogeneity-aware mechanisms: (1) \textit{Modality-Aware Step Caching} to decouple structural evolution from sensitive layout updates; (2) \textit{Joint Spatiotemporal Token Carving} to concentrate refinement on high-entropy regions; and (3) \textit{Spectral-Aware Token Aggregation} to adapt decoding resolution. Extensive experiments demonstrate that Fast-SAM3D delivers up to \textbf{2.67$\times$} end-to-end speedup with negligible fidelity loss, establishing a new Pareto frontier for efficient single-view 3D generation. Our code is released in https://github.com/wlfeng0509/Fast-SAM3D.
LEVIO: Lightweight Embedded Visual Inertial Odometry for Resource-Constrained Devices
Feb 03, 2026Accurate, infrastructure-less sensor systems for motion tracking are essential for mobile robotics and augmented reality (AR) applications. The most popular state-of-the-art visual-inertial odometry (VIO) systems, however, are too computationally demanding for resource-constrained hardware, such as micro-drones and smart glasses. This work presents LEVIO, a fully featured VIO pipeline optimized for ultra-low-power compute platforms, allowing six-degrees-of-freedom (DoF) real-time sensing. LEVIO incorporates established VIO components such as Oriented FAST and Rotated BRIEF (ORB) feature tracking and bundle adjustment, while emphasizing a computationally efficient architecture with parallelization and low memory usage to suit embedded microcontrollers and low-power systems-on-chip (SoCs). The paper proposes and details the algorithmic design choices and the hardware-software co-optimization approach, and presents real-time performance on resource-constrained hardware. LEVIO is validated on a parallel-processing ultra-low-power RISC-V SoC, achieving 20 FPS while consuming less than 100 mW, and benchmarked against public VIO datasets, offering a compelling balance between efficiency and accuracy. To facilitate reproducibility and adoption, the complete implementation is released as open-source.
* This article has been accepted for publication in the IEEE Sensors Journal (JSEN)
Eco-WakeLoc: An Energy-Neutral and Cooperative UWB Real-Time Locating System
Jan 06, 2026Indoor localization systems face a fundamental trade-off between efficiency and responsiveness, which is especially important for emerging use cases such as mobile robots operating in GPS-denied environments. Traditional RTLS either require continuously powered infrastructure, limiting their scalability, or are limited by their responsiveness. This work presents Eco-WakeLoc, designed to achieve centimeter-level UWB localization while remaining energy-neutral by combining ultra-low power wake-up radios (WuRs) with solar energy harvesting. By activating anchor nodes only on demand, the proposed system eliminates constant energy consumption while achieving centimeter-level positioning accuracy. To reduce coordination overhead and improve scalability, Eco-WakeLoc employs cooperative localization where active tags initiate ranging exchanges (trilateration), while passive tags opportunistically reuse these messages for TDOA positioning. An additive-increase/multiplicative-decrease (AIMD)-based energy-aware scheduler adapts localization rates according to the harvested energy, thereby maximizing the overall performance of the sensor network while ensuring long-term energy neutrality. The measured energy consumption is only 3.22mJ per localization for active tags, 951uJ for passive tags, and 353uJ for anchors. Real-world deployment on a quadruped robot with nine anchors confirms the practical feasibility, achieving an average accuracy of 43cm in dynamic indoor environments. Year-long simulations show that tags achieve an average of 2031 localizations per day, retaining over 7% battery capacity after one year -- demonstrating that the RTLS achieves sustained energy-neutral operation. Eco-WakeLoc demonstrates that high-accuracy indoor localization can be achieved at scale without continuous infrastructure operation, combining energy neutrality, cooperative positioning, and adaptive scheduling.
$\text{S}^2$Q-VDiT: Accurate Quantized Video Diffusion Transformer with Salient Data and Sparse Token Distillation
Aug 06, 2025Diffusion transformers have emerged as the mainstream paradigm for video generation models. However, the use of up to billions of parameters incurs significant computational costs. Quantization offers a promising solution by reducing memory usage and accelerating inference. Nonetheless, we observe that the joint modeling of spatial and temporal information in video diffusion models (V-DMs) leads to extremely long token sequences, which introduces high calibration variance and learning challenges. To address these issues, we propose \textbf{$\text{S}^2$Q-VDiT}, a post-training quantization framework for V-DMs that leverages \textbf{S}alient data and \textbf{S}parse token distillation. During the calibration phase, we identify that quantization performance is highly sensitive to the choice of calibration data. To mitigate this, we introduce \textit{Hessian-aware Salient Data Selection}, which constructs high-quality calibration datasets by considering both diffusion and quantization characteristics unique to V-DMs. To tackle the learning challenges, we further analyze the sparse attention patterns inherent in V-DMs. Based on this observation, we propose \textit{Attention-guided Sparse Token Distillation}, which exploits token-wise attention distributions to emphasize tokens that are more influential to the model's output. Under W4A6 quantization, $\text{S}^2$Q-VDiT achieves lossless performance while delivering $3.9\times$ model compression and $1.3\times$ inference acceleration. Code will be available at \href{https://github.com/wlfeng0509/s2q-vdit}{https://github.com/wlfeng0509/s2q-vdit}.
EdgeCodec: Onboard Lightweight High Fidelity Neural Compressor with Residual Vector Quantization
Jul 08, 2025We present EdgeCodec, an end-to-end neural compressor for barometric data collected from wind turbine blades. EdgeCodec leverages a heavily asymmetric autoencoder architecture, trained with a discriminator and enhanced by a Residual Vector Quantizer to maximize compression efficiency. It achieves compression rates between 2'560:1 and 10'240:1 while maintaining a reconstruction error below 3%, and operates in real time on the GAP9 microcontroller with bitrates ranging from 11.25 to 45 bits per second. Bitrates can be selected on a sample-by-sample basis, enabling on-the-fly adaptation to varying network conditions. In its highest compression mode, EdgeCodec reduces the energy consumption of wireless data transmission by up to 2.9x, significantly extending the operational lifetime of deployed sensor units.
PicoSAM2: Low-Latency Segmentation In-Sensor for Edge Vision Applications
Jun 24, 2025Real-time, on-device segmentation is critical for latency-sensitive and privacy-aware applications like smart glasses and IoT devices. We introduce PicoSAM2, a lightweight (1.3M parameters, 336M MACs) promptable segmentation model optimized for edge and in-sensor execution, including the Sony IMX500. It builds on a depthwise separable U-Net, with knowledge distillation and fixed-point prompt encoding to learn from the Segment Anything Model 2 (SAM2). On COCO and LVIS, it achieves 51.9% and 44.9% mIoU, respectively. The quantized model (1.22MB) runs at 14.3 ms on the IMX500-achieving 86 MACs/cycle, making it the only model meeting both memory and compute constraints for in-sensor deployment. Distillation boosts LVIS performance by +3.5% mIoU and +5.1% mAP. These results demonstrate that efficient, promptable segmentation is feasible directly on-camera, enabling privacy-preserving vision without cloud or host processing.
Post-Training Quantization for Video Matting
Jun 12, 2025Video matting is crucial for applications such as film production and virtual reality, yet deploying its computationally intensive models on resource-constrained devices presents challenges. Quantization is a key technique for model compression and acceleration. As an efficient approach, Post-Training Quantization (PTQ) is still in its nascent stages for video matting, facing significant hurdles in maintaining accuracy and temporal coherence. To address these challenges, this paper proposes a novel and general PTQ framework specifically designed for video matting models, marking, to the best of our knowledge, the first systematic attempt in this domain. Our contributions include: (1) A two-stage PTQ strategy that combines block-reconstruction-based optimization for fast, stable initial quantization and local dependency capture, followed by a global calibration of quantization parameters to minimize accuracy loss. (2) A Statistically-Driven Global Affine Calibration (GAC) method that enables the network to compensate for cumulative statistical distortions arising from factors such as neglected BN layer effects, even reducing the error of existing PTQ methods on video matting tasks up to 20%. (3) An Optical Flow Assistance (OFA) component that leverages temporal and semantic priors from frames to guide the PTQ process, enhancing the model's ability to distinguish moving foregrounds in complex scenes and ultimately achieving near full-precision performance even under ultra-low-bit quantization. Comprehensive quantitative and visual results show that our PTQ4VM achieves the state-of-the-art accuracy performance across different bit-widths compared to the existing quantization methods. We highlight that the 4-bit PTQ4VM even achieves performance close to the full-precision counterpart while enjoying 8x FLOP savings.
Q-SAM2: Accurate Quantization for Segment Anything Model 2
Jun 11, 2025The Segment Anything Model 2 (SAM2) has gained significant attention as a foundational approach for promptable image and video segmentation. However, its expensive computational and memory consumption poses a severe challenge for its application in resource-constrained scenarios. In this paper, we propose an accurate low-bit quantization method for efficient SAM2, termed Q-SAM2. To address the performance degradation caused by the singularities in weight and activation distributions during quantization, Q-SAM2 introduces two novel technical contributions. We first introduce a linear layer calibration method for low-bit initialization of SAM2, which minimizes the Frobenius norm over a small image batch to reposition weight distributions for improved quantization. We then propose a Quantization-Aware Training (QAT) pipeline that applies clipping to suppress outliers and allows the network to adapt to quantization thresholds during training. Our comprehensive experiments demonstrate that Q-SAM2 allows for highly accurate inference while substantially improving efficiency. Both quantitative and visual results show that our Q-SAM2 surpasses existing state-of-the-art general quantization schemes, especially for ultra-low 2-bit quantization. While designed for quantization-aware training, our proposed calibration technique also proves effective in post-training quantization, achieving up to a 66% mIoU accuracy improvement over non-calibrated models.
R-CARLA: High-Fidelity Sensor Simulations with Interchangeable Dynamics for Autonomous Racing
Jun 11, 2025Autonomous racing has emerged as a crucial testbed for autonomous driving algorithms, necessitating a simulation environment for both vehicle dynamics and sensor behavior. Striking the right balance between vehicle dynamics and sensor accuracy is crucial for pushing vehicles to their performance limits. However, autonomous racing developers often face a trade-off between accurate vehicle dynamics and high-fidelity sensor simulations. This paper introduces R-CARLA, an enhancement of the CARLA simulator that supports holistic full-stack testing, from perception to control, using a single system. By seamlessly integrating accurate vehicle dynamics with sensor simulations, opponents simulation as NPCs, and a pipeline for creating digital twins from real-world robotic data, R-CARLA empowers researchers to push the boundaries of autonomous racing development. Furthermore, it is developed using CARLA's rich suite of sensor simulations. Our results indicate that incorporating the proposed digital-twin framework into R-CARLA enables more realistic full-stack testing, demonstrating a significant reduction in the Sim-to-Real gap of car dynamics simulation by 42% and by 82% in the case of sensor simulation across various testing scenarios.
Event-Priori-Based Vision-Language Model for Efficient Visual Understanding
Jun 09, 2025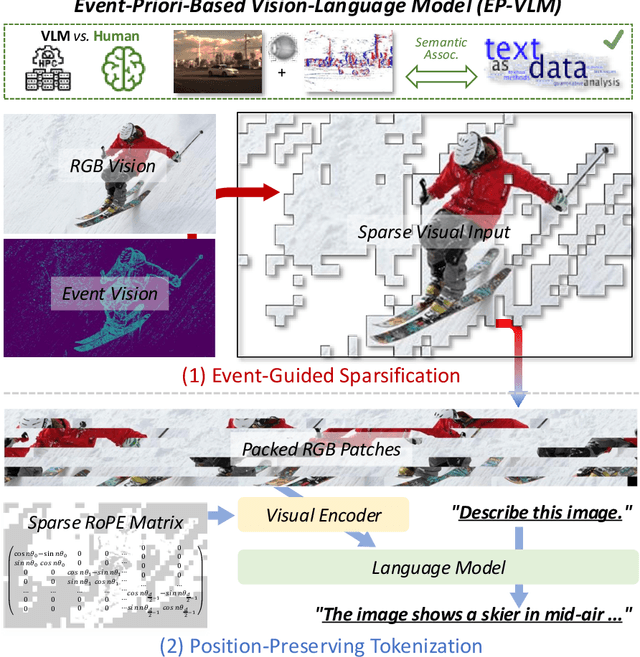
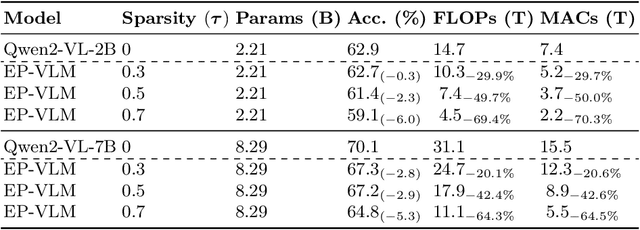


Large Language Model (LLM)-based Vision-Language Models (VLMs) have substantially extended the boundaries of visual understanding capabilities. However, their high computational demands hinder deployment on resource-constrained edge devices. A key source of inefficiency stems from the VLM's need to process dense and redundant visual information. Visual inputs contain significant regions irrelevant to text semantics, rendering the associated computations ineffective for inference. This paper introduces a novel Event-Priori-Based Vision-Language Model, termed EP-VLM. Its core contribution is a novel mechanism leveraging motion priors derived from dynamic event vision to enhance VLM efficiency. Inspired by human visual cognition, EP-VLM first employs event data to guide the patch-wise sparsification of RGB visual inputs, progressively concentrating VLM computation on salient regions of the visual input. Subsequently, we construct a position-preserving tokenization strategy for the visual encoder within the VLM architecture. This strategy processes the event-guided, unstructured, sparse visual input while accurately preserving positional understanding within the visual input. Experimental results demonstrate that EP-VLM achieves significant efficiency improvements while maintaining nearly lossless accuracy compared to baseline models from the Qwen2-VL series. For instance, against the original Qwen2-VL-2B, EP-VLM achieves 50% FLOPs savings while retaining 98% of the original accuracy on the RealWorldQA dataset. This work demonstrates the potential of event-based vision priors for improving VLM inference efficiency, paving the way for creating more efficient and deployable VLMs for sustainable visual understanding at the edge.