 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompting Meets Feature Reconstruction-Based Anomaly Detection with Dual-Teacher Supervision
Jun 08, 2026Recent Anomaly Detection methods achieve perfect detection and segmentation scores on well-established datasets, such as MVTec. However, many of these methods face challenges when foundational assumptions - such as consistent object scale, viewpoint, background, illumination, and centered placement - are violated. Those variations that occur render anomaly detection methods unusable in many real-world scenarios. To address these limitations, we introduce three key contributions: (1) a visual prompting pipeline that isolates objects using foreground-background masking; (2) a mechanism for unfreezing the teacher in student-teacher models to improve domain adaptability; and (3) a data augmentation strategy leveraging diffusion-generated synthetic images to enhance anomaly detection performance. We achieve a 3.5 percentage point improvement over the previous state-of-the-art on the challenging AeBAD dataset by using the Masked Multiscale Reconstruction (MMR) model as our backbone.
Cracks in the Foundation: A Civil Infrastructure Dataset to Challenge Vision Foundation Models
May 19, 2026Automated structural health monitoring is essential to prevent catastrophic infrastructure failures. Precise, pixel-level defect segmentation is needed to accurately assess structural integrity, but progress in defect segmentation for civil infrastructures has been held back by an extreme scarcity of data, which requires costly expert annotation. The need for data is accentuated by algorithmic hurdles intrinsic to the problem, including center-bias and the need to rely more on shape when inspecting nearly textureless building materials. To remove the bottleneck, we introduce Cracks in the Foundation (CiF), the largest and most detailed civil infrastructure (instance) segmentation dataset to date, comprising $\approx$150,000 high-resolution images meticulously curated over five years in collaboration with civil engineering experts. With the help of this unprecedented data source, we expose a blind spot of current visual AI: despite the advent of promptable Foundation Models (FMs) and Vision Language Models (VLMs), and despite the impressive abilities of today's specialised segmentation models, it turns out that dense image understanding in the built environment is nowhere near solved. Our evaluations indicate that even the most recent zero-shot FMs face significant challenges when deployed on real-world infrastructure and even the performance of specialised models with domain-specific supervision plateaus at $\approx$25% mAP. CiF establishes inspection of civil infrastructure, an elementary and seemingly easy perceptual task, as an open challenge that reveals fundamental weaknesses of present-day models trained predominantly on internet images, literally and figuratively highlighting cracks in the current foundation model paradigm.
Q-SAM2: Accurate Quantization for Segment Anything Model 2
Jun 11, 2025The Segment Anything Model 2 (SAM2) has gained significant attention as a foundational approach for promptable image and video segmentation. However, its expensive computational and memory consumption poses a severe challenge for its application in resource-constrained scenarios. In this paper, we propose an accurate low-bit quantization method for efficient SAM2, termed Q-SAM2. To address the performance degradation caused by the singularities in weight and activation distributions during quantization, Q-SAM2 introduces two novel technical contributions. We first introduce a linear layer calibration method for low-bit initialization of SAM2, which minimizes the Frobenius norm over a small image batch to reposition weight distributions for improved quantization. We then propose a Quantization-Aware Training (QAT) pipeline that applies clipping to suppress outliers and allows the network to adapt to quantization thresholds during training. Our comprehensive experiments demonstrate that Q-SAM2 allows for highly accurate inference while substantially improving efficiency. Both quantitative and visual results show that our Q-SAM2 surpasses existing state-of-the-art general quantization schemes, especially for ultra-low 2-bit quantization. While designed for quantization-aware training, our proposed calibration technique also proves effective in post-training quantization, achieving up to a 66% mIoU accuracy improvement over non-calibrated models.
VP Lab: a PEFT-Enabled Visual Prompting Laboratory for Semantic Segmentation
May 21, 2025Large-scale pretrained vision backbones have transformed computer vision by providing powerful feature extractors that enable various downstream tasks, including training-free approaches like visual prompting for semantic segmentation. Despite their success in generic scenarios, these models often fall short when applied to specialized technical domains where the visual features differ significantly from their training distribution. To bridge this gap, we introduce VP Lab, a comprehensive iterative framework that enhances visual prompting for robust segmentation model development. At the core of VP Lab lies E-PEFT, a novel ensemble of parameter-efficient fine-tuning techniques specifically designed to adapt our visual prompting pipeline to specific domains in a manner that is both parameter- and data-efficient. Our approach not only surpasses the state-of-the-art in parameter-efficient fine-tuning for the Segment Anything Model (SAM), but also facilitates an interactive, near-real-time loop, allowing users to observe progressively improving results as they experiment within the framework. By integrating E-PEFT with visual prompting, we demonstrate a remarkable 50\% increase in semantic segmentation mIoU performance across various technical datasets using only 5 validated images, establishing a new paradigm for fast, efficient, and interactive model deployment in new, challenging domains. This work comes in the form of a demonstration.
Show or Tell? Effectively prompting Vision-Language Models for semantic segmentation
Mar 25, 2025Large Vision-Language Models (VLMs) are increasingly being regarded as foundation models that can be instructed to solve diverse tasks by prompting, without task-specific training. We examine the seemingly obvious question: how to effectively prompt VLMs for semantic segmentation. To that end, we systematically evaluate the segmentation performance of several recent models guided by either text or visual prompts on the out-of-distribution MESS dataset collection. We introduce a scalable prompting scheme, few-shot prompted semantic segmentation, inspired by open-vocabulary segmentation and few-shot learning. It turns out that VLMs lag far behind specialist models trained for a specific segmentation task, by about 30% on average on the Intersection-over-Union metric. Moreover, we find that text prompts and visual prompts are complementary: each one of the two modes fails on many examples that the other one can solve. Our analysis suggests that being able to anticipate the most effective prompt modality can lead to a 11% improvement in performance. Motivated by our findings, we propose PromptMatcher, a remarkably simple training-free baseline that combines both text and visual prompts, achieving state-of-the-art results outperforming the best text-prompted VLM by 2.5%, and the top visual-prompted VLM by 3.5% on few-shot prompted semantic segmentation.
Outline-Guided Object Inpainting with Diffusion Models
Feb 26, 2024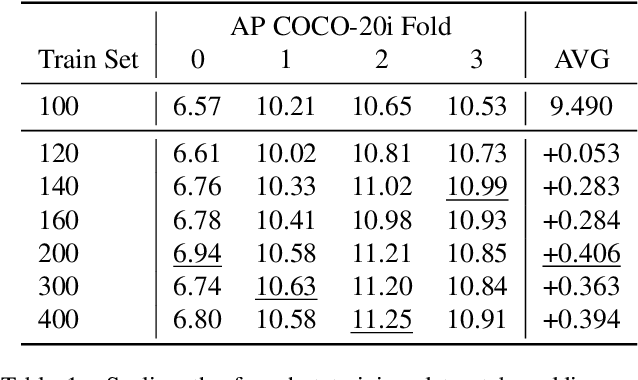


Instance segmentation datasets play a crucial role in training accurate and robust computer vision models. However, obtaining accurate mask annotations to produce high-quality segmentation datasets is a costly and labor-intensive process. In this work, we show how this issue can be mitigated by starting with small annotated instance segmentation datasets and augmenting them to effectively obtain a sizeable annotated dataset. We achieve that by creating variations of the available annotated object instances in a way that preserves the provided mask annotations, thereby resulting in new image-mask pairs to be added to the set of annotated images. Specifically, we generate new images using a diffusion-based inpainting model to fill out the masked area with a desired object class by guiding the diffusion through the object outline. We show that the object outline provides a simple, but also reliable and convenient training-free guidance signal for the underlying inpainting model that is often sufficient to fill out the mask with an object of the correct class without further text guidance and preserve the correspondence between generated images and the mask annotations with high precision. Our experimental results reveal that our method successfully generates realistic variations of object instances, preserving their shape characteristics while introducing diversity within the augmented area. We also show that the proposed method can naturally be combined with text guidance and other image augmentation techniques.
Active Learning for Imbalanced Civil Infrastructure Data
Oct 19, 2022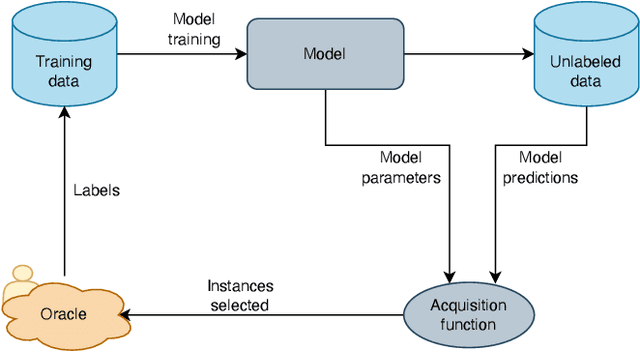


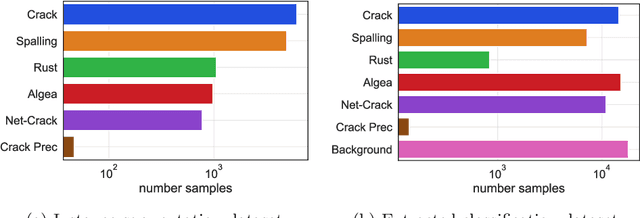
Aging civil infrastructures are closely monitored by engineers for damage and critical defects. As the manual inspection of such large structures is costly and time-consuming, we are working towards fully automating the visual inspections to support the prioritization of maintenance activities. To that end we combine recent advances in drone technology and deep learning. Unfortunately, annotation costs are incredibly high as our proprietary civil engineering dataset must be annotated by highly trained engineers. Active learning is, therefore, a valuable tool to optimize the trade-off between model performance and annotation costs. Our use-case differs from the classical active learning setting as our dataset suffers from heavy class imbalance and consists of a much larger already labeled data pool than other active learning research. We present a novel method capable of operating in this challenging setting by replacing the traditional active learning acquisition function with an auxiliary binary discriminator. We experimentally show that our novel method outperforms the best-performing traditional active learning method (BALD) by 5% and 38% accuracy on CIFAR-10 and our proprietary dataset respectively.
Model-Assisted Labeling via Explainability for Visual Inspection of Civil Infrastructures
Sep 22, 2022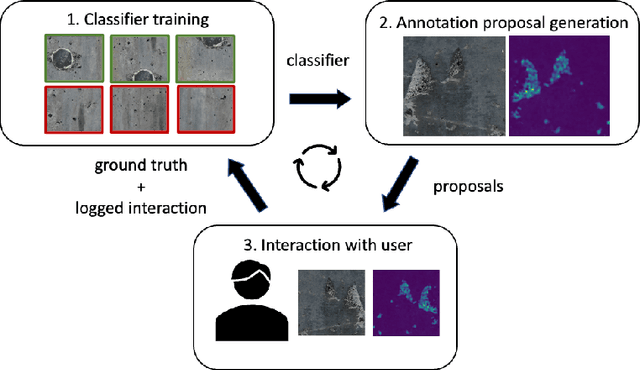
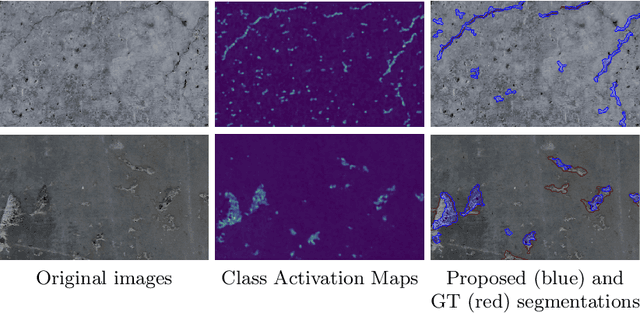
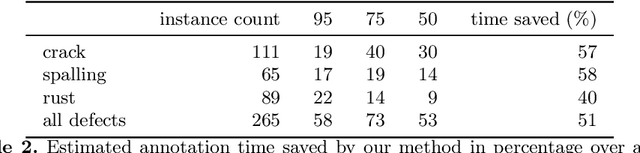
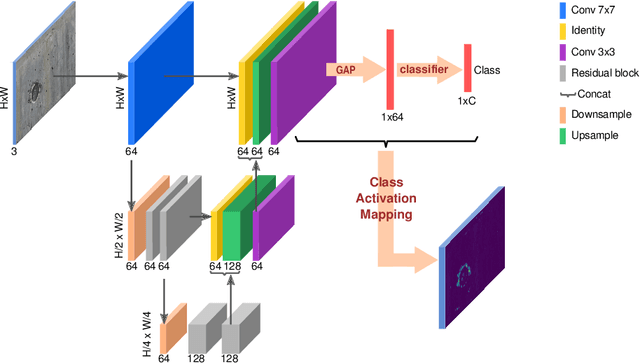
Labeling images for visual segmentation is a time-consuming task which can be costly, particularly in application domains where labels have to be provided by specialized expert annotators, such as civil engineering. In this paper, we propose to use attribution methods to harness the valuable interactions between expert annotators and the data to be annotated in the case of defect segmentation for visual inspection of civil infrastructures. Concretely, a classifier is trained to detect defects and coupled with an attribution-based method and adversarial climbing to generate and refine segmentation masks corresponding to the classification outputs. These are used within an assisted labeling framework where the annotators can interact with them as proposal segmentation masks by deciding to accept, reject or modify them, and interactions are logged as weak labels to further refine the classifier. Applied on a real-world dataset resulting from the automated visual inspection of bridges, our proposed method is able to save more than 50\% of annotators' time when compared to manual annotation of defects.
Enabling Reproducibility and Meta-learning Through a Lifelong Database of Experiments (LDE)
Feb 23, 2022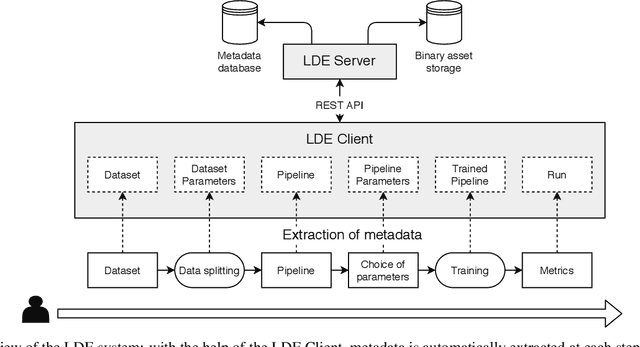
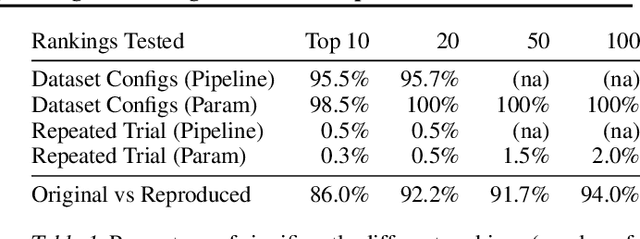
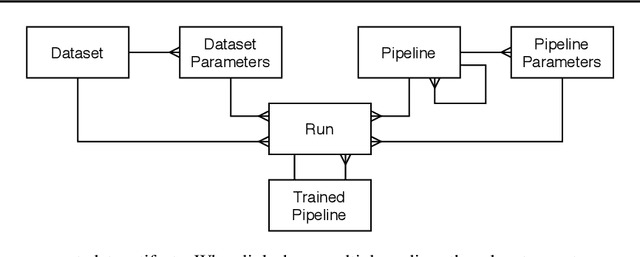

Artificial Intelligence (AI) development is inherently iterative and experimental. Over the course of normal development, especially with the advent of automated AI, hundreds or thousands of experiments are generated and are often lost or never examined again. There is a lost opportunity to document these experiments and learn from them at scale, but the complexity of tracking and reproducing these experiments is often prohibitive to data scientists. We present the Lifelong Database of Experiments (LDE) that automatically extracts and stores linked metadata from experiment artifacts and provides features to reproduce these artifacts and perform meta-learning across them. We store context from multiple stages of the AI development lifecycle including datasets, pipelines, how each is configured, and training runs with information about their runtime environment. The standardized nature of the stored metadata allows for querying and aggregation, especially in terms of ranking artifacts by performance metrics. We exhibit the capabilities of the LDE by reproducing an existing meta-learning study and storing the reproduced metadata in our system. Then, we perform two experiments on this metadata: 1) examining the reproducibility and variability of the performance metrics and 2) implementing a number of meta-learning algorithms on top of the data and examining how variability in experimental results impacts recommendation performance. The experimental results suggest significant variation in performance, especially depending on dataset configurations; this variation carries over when meta-learning is built on top of the results, with performance improving when using aggregated results. This suggests that a system that automatically collects and aggregates results such as the LDE not only assists in implementing meta-learning but may also improve its performance.
Generating Efficient DNN-Ensembles with Evolutionary Computation
Sep 18, 2020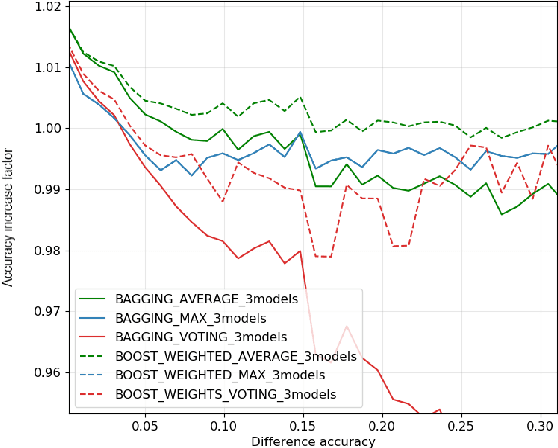
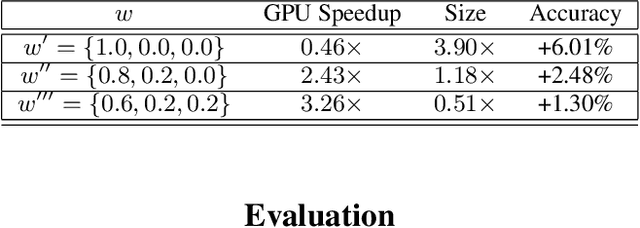
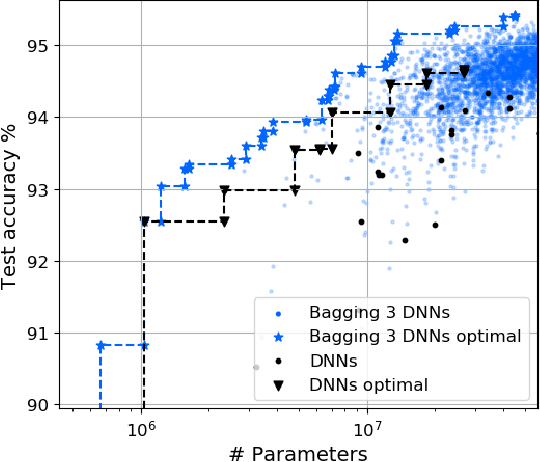
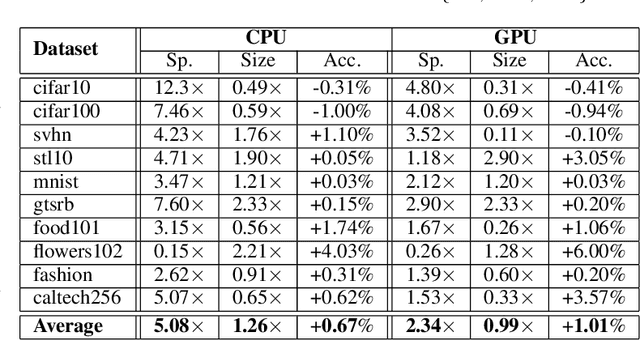
In this work, we leverage ensemble learning as a tool for the creation of faster, smaller, and more accurate deep learning models. We demonstrate that we can jointly optimize for accuracy, inference time, and the number of parameters by combining DNN classifiers. To achieve this, we combine multiple ensemble strategies: bagging, boosting, and an ordered chain of classifiers. To reduce the number of DNN ensemble evaluations during the search, we propose EARN, an evolutionary approach that optimizes the ensemble according to three objectives regarding the constraints specified by the user. We run EARN on 10 image classification datasets with an initial pool of 32 state-of-the-art DCNN on both CPU and GPU platforms, and we generate models with speedups up to $7.60\times$, reductions of parameters by $10\times$, or increases in accuracy up to $6.01\%$ regarding the best DNN in the pool. In addition, our method generates models that are $5.6\times$ faster than the state-of-the-art methods for automatic model generation.