 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster by Design: Interactive Aerodynamics via Neural Surrogates Trained on Expert-Validated CFD
Apr 20, 2026Computational Fluid Dynamics (CFD) is central to race-car aerodynamic development, yet its cost -- tens of thousands of core-hours per high-fidelity evaluation -- severely limits the design space exploration feasible within realistic budgets. AI-based surrogate models promise to alleviate this bottleneck, but progress has been constrained by the limited complexity of public datasets, which are dominated by smoothed passenger-car shapes that fail to exercise surrogates on the thin, complex, highly loaded components governing motorsport performance. This work presents three primary contributions. First, we introduce a high-fidelity RANS dataset built on a parametric LMP2-class CAD model and spanning six operating conditions (map points) covering straight-line and cornering regimes, generated and validated by aerodynamics experts at Dallara to preserve features relevant to industrial motorsport. Second, we present the Gauge-Invariant Spectral Transformer (GIST), a graph-based neural operator whose spectral embeddings encode mesh connectivity to enhance predictions on tightly packed, complex geometries. GIST guarantees discretization invariance and scales linearly with mesh size, achieving state-of-the-art accuracy on both public benchmarks and the proposed race-car dataset. Third, we demonstrate that GIST achieves a level of predictive accuracy suitable for early-stage aerodynamic design, providing a first validation of the concept of interactive design-space exploration -- where engineers query a surrogate in place of the CFD solver -- within industrial motorsport workflows.
GIST: Gauge-Invariant Spectral Transformers for Scalable Graph Neural Operators
Mar 17, 2026Adapting transformer positional encoding to meshes and graph-structured data presents significant computational challenges: exact spectral methods require cubic-complexity eigendecomposition and can inadvertently break gauge invariance through numerical solver artifacts, while efficient approximate methods sacrifice gauge symmetry by design. Both failure modes cause catastrophic generalization in inductive learning, where models trained with one set of numerical choices fail when encountering different spectral decompositions of similar graphs or discretizations of the same mesh. We propose GIST (Gauge-Invariant Spectral Transformers), a new graph transformer architecture that resolves this challenge by achieving end-to-end $\mathcal{O}(N)$ complexity through random projections while algorithmically preserving gauge invariance via inner-product-based attention on the projected embeddings. We prove GIST achieves discretization-invariant learning with bounded mismatch error, enabling parameter transfer across arbitrary mesh resolutions for neural operator applications. Empirically, GIST matches state-of-the-art on standard graph benchmarks (e.g., achieving 99.50% micro-F1 on PPI) while uniquely scaling to mesh-based Neural Operator benchmarks with up to 750K nodes, achieving state-of-the-art aerodynamic prediction on the challenging DrivAerNet and DrivAerNet++ datasets.
SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
Feb 06, 2026Despite recent successes, test-time scaling - i.e., dynamically expanding the token budget during inference as needed - remains brittle for vision-language models (VLMs): unstructured chains-of-thought about images entangle perception and reasoning, leading to long, disorganized contexts where small perceptual mistakes may cascade into completely wrong answers. Moreover, expensive reinforcement learning with hand-crafted rewards is required to achieve good performance. Here, we introduce SPARC (Separating Perception And Reasoning Circuits), a modular framework that explicitly decouples visual perception from reasoning. Inspired by sequential sensory-to-cognitive processing in the brain, SPARC implements a two-stage pipeline where the model first performs explicit visual search to localize question-relevant regions, then conditions its reasoning on those regions to produce the final answer. This separation enables independent test-time scaling with asymmetric compute allocation (e.g., prioritizing perceptual processing under distribution shift), supports selective optimization (e.g., improving the perceptual stage alone when it is the bottleneck for end-to-end performance), and accommodates compressed contexts by running global search at lower image resolutions and allocating high-resolution processing only to selected regions, thereby reducing total visual tokens count and compute. Across challenging visual reasoning benchmarks, SPARC outperforms monolithic baselines and strong visual-grounding approaches. For instance, SPARC improves the accuracy of Qwen3VL-4B on the $V^*$ VQA benchmark by 6.7 percentage points, and it surpasses "thinking with images" by 4.6 points on a challenging OOD task despite requiring a 200$\times$ lower token budget.
Eliciting Reasoning in Language Models with Cognitive Tools
Jun 13, 2025The recent advent of reasoning models like OpenAI's o1 was met with excited speculation by the AI community about the mechanisms underlying these capabilities in closed models, followed by a rush of replication efforts, particularly from the open source community. These speculations were largely settled by the demonstration from DeepSeek-R1 that chains-of-thought and reinforcement learning (RL) can effectively replicate reasoning on top of base LLMs. However, it remains valuable to explore alternative methods for theoretically eliciting reasoning that could help elucidate the underlying mechanisms, as well as providing additional methods that may offer complementary benefits. Here, we build on the long-standing literature in cognitive psychology and cognitive architectures, which postulates that reasoning arises from the orchestrated, sequential execution of a set of modular, predetermined cognitive operations. Crucially, we implement this key idea within a modern agentic tool-calling framework. In particular, we endow an LLM with a small set of "cognitive tools" encapsulating specific reasoning operations, each executed by the LLM itself. Surprisingly, this simple strategy results in considerable gains in performance on standard mathematical reasoning benchmarks compared to base LLMs, for both closed and open-weight models. For instance, providing our "cognitive tools" to GPT-4.1 increases its pass@1 performance on AIME2024 from 26.7% to 43.3%, bringing it very close to the performance of o1-preview. In addition to its practical implications, this demonstration contributes to the debate regarding the role of post-training methods in eliciting reasoning in LLMs versus the role of inherent capabilities acquired during pre-training, and whether post-training merely uncovers these latent abilities.
Q-SAM2: Accurate Quantization for Segment Anything Model 2
Jun 11, 2025The Segment Anything Model 2 (SAM2) has gained significant attention as a foundational approach for promptable image and video segmentation. However, its expensive computational and memory consumption poses a severe challenge for its application in resource-constrained scenarios. In this paper, we propose an accurate low-bit quantization method for efficient SAM2, termed Q-SAM2. To address the performance degradation caused by the singularities in weight and activation distributions during quantization, Q-SAM2 introduces two novel technical contributions. We first introduce a linear layer calibration method for low-bit initialization of SAM2, which minimizes the Frobenius norm over a small image batch to reposition weight distributions for improved quantization. We then propose a Quantization-Aware Training (QAT) pipeline that applies clipping to suppress outliers and allows the network to adapt to quantization thresholds during training. Our comprehensive experiments demonstrate that Q-SAM2 allows for highly accurate inference while substantially improving efficiency. Both quantitative and visual results show that our Q-SAM2 surpasses existing state-of-the-art general quantization schemes, especially for ultra-low 2-bit quantization. While designed for quantization-aware training, our proposed calibration technique also proves effective in post-training quantization, achieving up to a 66% mIoU accuracy improvement over non-calibrated models.
Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
May 28, 2025We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
VP Lab: a PEFT-Enabled Visual Prompting Laboratory for Semantic Segmentation
May 21, 2025Large-scale pretrained vision backbones have transformed computer vision by providing powerful feature extractors that enable various downstream tasks, including training-free approaches like visual prompting for semantic segmentation. Despite their success in generic scenarios, these models often fall short when applied to specialized technical domains where the visual features differ significantly from their training distribution. To bridge this gap, we introduce VP Lab, a comprehensive iterative framework that enhances visual prompting for robust segmentation model development. At the core of VP Lab lies E-PEFT, a novel ensemble of parameter-efficient fine-tuning techniques specifically designed to adapt our visual prompting pipeline to specific domains in a manner that is both parameter- and data-efficient. Our approach not only surpasses the state-of-the-art in parameter-efficient fine-tuning for the Segment Anything Model (SAM), but also facilitates an interactive, near-real-time loop, allowing users to observe progressively improving results as they experiment within the framework. By integrating E-PEFT with visual prompting, we demonstrate a remarkable 50\% increase in semantic segmentation mIoU performance across various technical datasets using only 5 validated images, establishing a new paradigm for fast, efficient, and interactive model deployment in new, challenging domains. This work comes in the form of a demonstration.
Show or Tell? Effectively prompting Vision-Language Models for semantic segmentation
Mar 25, 2025Large Vision-Language Models (VLMs) are increasingly being regarded as foundation models that can be instructed to solve diverse tasks by prompting, without task-specific training. We examine the seemingly obvious question: how to effectively prompt VLMs for semantic segmentation. To that end, we systematically evaluate the segmentation performance of several recent models guided by either text or visual prompts on the out-of-distribution MESS dataset collection. We introduce a scalable prompting scheme, few-shot prompted semantic segmentation, inspired by open-vocabulary segmentation and few-shot learning. It turns out that VLMs lag far behind specialist models trained for a specific segmentation task, by about 30% on average on the Intersection-over-Union metric. Moreover, we find that text prompts and visual prompts are complementary: each one of the two modes fails on many examples that the other one can solve. Our analysis suggests that being able to anticipate the most effective prompt modality can lead to a 11% improvement in performance. Motivated by our findings, we propose PromptMatcher, a remarkably simple training-free baseline that combines both text and visual prompts, achieving state-of-the-art results outperforming the best text-prompted VLM by 2.5%, and the top visual-prompted VLM by 3.5% on few-shot prompted semantic segmentation.
Multivariate Stochastic Dominance via Optimal Transport and Applications to Models Benchmarking
Jun 10, 2024Stochastic dominance is an important concept in probability theory, econometrics and social choice theory for robustly modeling agents' preferences between random outcomes. While many works have been dedicated to the univariate case, little has been done in the multivariate scenario, wherein an agent has to decide between different multivariate outcomes. By exploiting a characterization of multivariate first stochastic dominance in terms of couplings, we introduce a statistic that assesses multivariate almost stochastic dominance under the framework of Optimal Transport with a smooth cost. Further, we introduce an entropic regularization of this statistic, and establish a central limit theorem (CLT) and consistency of the bootstrap procedure for the empirical statistic. Armed with this CLT, we propose a hypothesis testing framework as well as an efficient implementation using the Sinkhorn algorithm. We showcase our method in comparing and benchmarking Large Language Models that are evaluated on multiple metrics. Our multivariate stochastic dominance test allows us to capture the dependencies between the metrics in order to make an informed and statistically significant decision on the relative performance of the models.
Distributional Preference Alignment of LLMs via Optimal Transport
Jun 09, 2024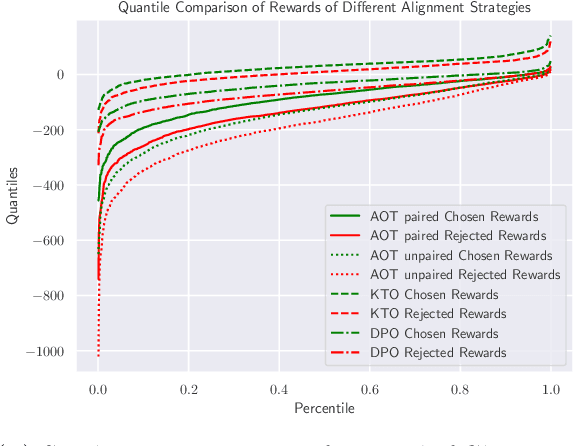
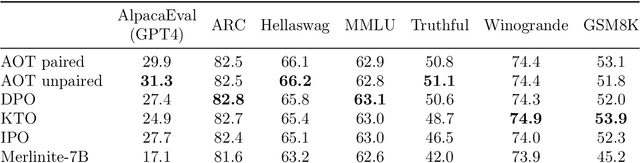
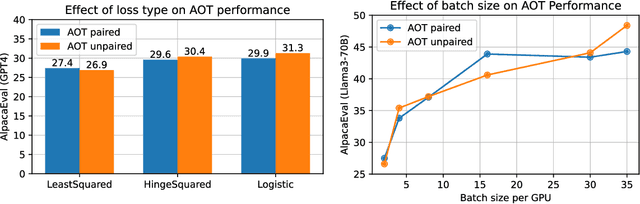

Current LLM alignment techniques use pairwise human preferences at a sample level, and as such, they do not imply an alignment on the distributional level. We propose in this paper Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT aligns LLMs on unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. We introduce a convex relaxation of this first-order stochastic dominance and cast it as an optimal transport problem with a smooth and convex cost. Thanks to the one-dimensional nature of the resulting optimal transport problem and the convexity of the cost, it has a closed-form solution via sorting on empirical measures. We fine-tune LLMs with this AOT objective, which enables alignment by penalizing the violation of the stochastic dominance of the reward distribution of the positive samples on the reward distribution of the negative samples. We analyze the sample complexity of AOT by considering the dual of the OT problem and show that it converges at the parametric rate. Empirically, we show on a diverse set of alignment datasets and LLMs that AOT leads to state-of-the-art models in the 7B family of models when evaluated with Open LLM Benchmarks and AlpacaEval.