 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Limitations of refinement methods for weak to strong generalization
Aug 23, 2025



Standard techniques for aligning large language models (LLMs) utilize human-produced data, which could limit the capability of any aligned LLM to human level. Label refinement and weak training have emerged as promising strategies to address this superalignment problem. In this work, we adopt probabilistic assumptions commonly used to study label refinement and analyze whether refinement can be outperformed by alternative approaches, including computationally intractable oracle methods. We show that both weak training and label refinement suffer from irreducible error, leaving a performance gap between label refinement and the oracle. These results motivate future research into developing alternative methods for weak to strong generalization that synthesize the practicality of label refinement or weak training and the optimality of the oracle procedure.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025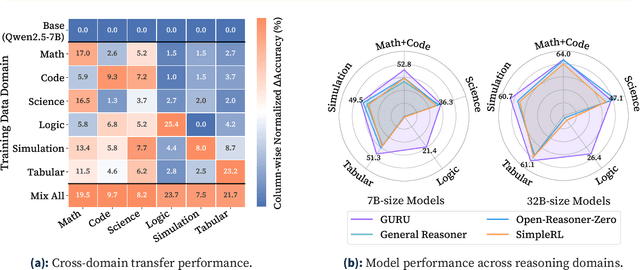
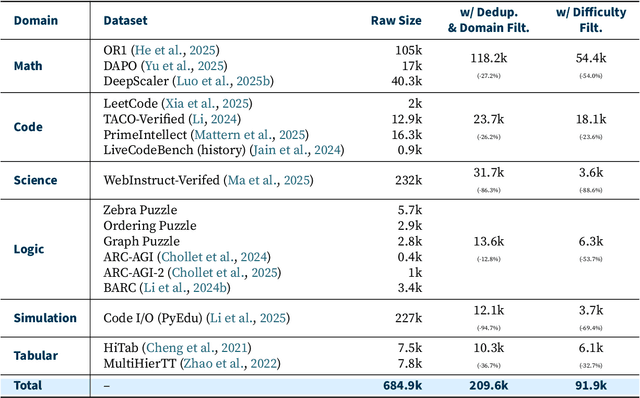
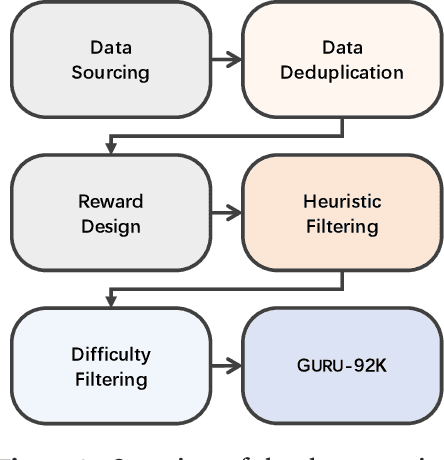

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Speculate, then Collaborate: Fusing Knowledge of Language Models during Decoding
Feb 11, 2025Large Language Models (LLMs) often excel in specific domains but fall short in others due to the limitations of their training. Thus, enabling LLMs to solve problems collaboratively by integrating their complementary knowledge promises to improve their performance across domains. To realize this potential, we introduce a novel Collaborative Speculative Decoding (CoSD) algorithm that enables efficient LLM knowledge fusion at test time without requiring additional model training. CoSD employs a draft model to generate initial sequences and an easy-to-learn rule or decision tree to decide when to invoke an assistant model to improve these drafts. CoSD not only enhances knowledge fusion but also improves inference efficiency, is transferable across domains and models, and offers greater explainability. Experimental results demonstrate that CoSD improves accuracy by up to 10\% across benchmarks compared to existing methods, providing a scalable and effective solution for LLM-based applications
CARROT: A Cost Aware Rate Optimal Router
Feb 05, 2025



With the rapid growth in the number of Large Language Models (LLMs), there has been a recent interest in LLM routing, or directing queries to the cheapest LLM that can deliver a suitable response. Following this line of work, we introduce CARROT, a Cost AwaRe Rate Optimal rouTer that can select models based on any desired trade-off between performance and cost. Given a query, CARROT selects a model based on estimates of models' cost and performance. Its simplicity lends CARROT computational efficiency, while our theoretical analysis demonstrates minimax rate-optimality in its routing performance. Alongside CARROT, we also introduce the Smart Price-aware Routing (SPROUT) dataset to facilitate routing on a wide spectrum of queries with the latest state-of-the-art LLMs. Using SPROUT and prior benchmarks such as Routerbench and open-LLM-leaderboard-v2 we empirically validate CARROT's performance against several alternative routers.
SPRI: Aligning Large Language Models with Context-Situated Principles
Feb 05, 2025



Aligning Large Language Models to integrate and reflect human values, especially for tasks that demand intricate human oversight, is arduous since it is resource-intensive and time-consuming to depend on human expertise for context-specific guidance. Prior work has utilized predefined sets of rules or principles to steer the behavior of models (Bai et al., 2022; Sun et al., 2023). However, these principles tend to be generic, making it challenging to adapt them to each individual input query or context. In this work, we present Situated-PRInciples (SPRI), a framework requiring minimal or no human effort that is designed to automatically generate guiding principles in real-time for each input query and utilize them to align each response. We evaluate SPRI on three tasks, and show that 1) SPRI can derive principles in a complex domain-specific task that leads to on-par performance as expert-crafted ones; 2) SPRI-generated principles lead to instance-specific rubrics that outperform prior LLM-as-a-judge frameworks; 3) using SPRI to generate synthetic SFT data leads to substantial improvement on truthfulness. We release our code and model generations at https://github.com/honglizhan/SPRI-public.
Out-of-Distribution Detection using Synthetic Data Generation
Feb 05, 2025Distinguishing in- and out-of-distribution (OOD) inputs is crucial for reliable deployment of classification systems. However, OOD data is typically unavailable or difficult to collect, posing a significant challenge for accurate OOD detection. In this work, we present a method that harnesses the generative capabilities of Large Language Models (LLMs) to create high-quality synthetic OOD proxies, eliminating the dependency on any external OOD data source. We study the efficacy of our method on classical text classification tasks such as toxicity detection and sentiment classification as well as classification tasks arising in LLM development and deployment, such as training a reward model for RLHF and detecting misaligned generations. Extensive experiments on nine InD-OOD dataset pairs and various model sizes show that our approach dramatically lowers false positive rates (achieving a perfect zero in some cases) while maintaining high accuracy on in-distribution tasks, outperforming baseline methods by a significant margin.
Sloth: scaling laws for LLM skills to predict multi-benchmark performance across families
Dec 09, 2024Scaling laws for large language models (LLMs) predict model performance based on parameters like size and training data. However, differences in training configurations and data processing across model families lead to significant variations in benchmark performance, making it difficult for a single scaling law to generalize across all LLMs. On the other hand, training family-specific scaling laws requires training models of varying sizes for every family. In this work, we propose Skills Scaling Laws (SSLaws, pronounced as Sloth), a novel scaling law that leverages publicly available benchmark data and assumes LLM performance is driven by low-dimensional latent skills, such as reasoning and instruction following. These latent skills are influenced by computational resources like model size and training tokens but with varying efficiencies across model families. Sloth exploits correlations across benchmarks to provide more accurate and interpretable predictions while alleviating the need to train multiple LLMs per family. We present both theoretical results on parameter identification and empirical evaluations on 12 prominent benchmarks, from Open LLM Leaderboard v1/v2, demonstrating that Sloth predicts LLM performance efficiently and offers insights into scaling behaviors for downstream tasks such as coding and emotional intelligence applications.
LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content
Oct 15, 2024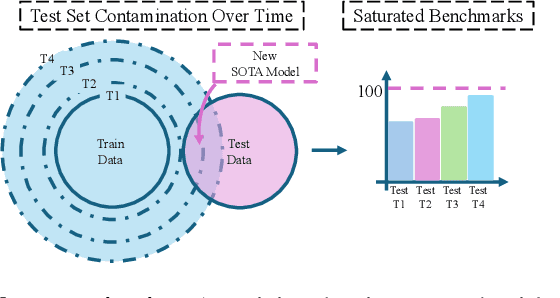



The large-scale training of multi-modal models on data scraped from the web has shown outstanding utility in infusing these models with the required world knowledge to perform effectively on multiple downstream tasks. However, one downside of scraping data from the web can be the potential sacrifice of the benchmarks on which the abilities of these models are often evaluated. To safeguard against test data contamination and to truly test the abilities of these foundation models we propose LiveXiv: A scalable evolving live benchmark based on scientific ArXiv papers. LiveXiv accesses domain-specific manuscripts at any given timestamp and proposes to automatically generate visual question-answer pairs (VQA). This is done without any human-in-the-loop, using the multi-modal content in the manuscripts, like graphs, charts, and tables. Moreover, we introduce an efficient evaluation approach that estimates the performance of all models on the evolving benchmark using evaluations of only a subset of models. This significantly reduces the overall evaluation cost. We benchmark multiple open and proprietary Large Multi-modal Models (LMMs) on the first version of our benchmark, showing its challenging nature and exposing the models true abilities, avoiding contamination. Lastly, in our commitment to high quality, we have collected and evaluated a manually verified subset. By comparing its overall results to our automatic annotations, we have found that the performance variance is indeed minimal (<2.5%). Our dataset is available online on HuggingFace, and our code will be available here.
Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead
Jun 17, 2024



Fine-tuning large language models (LLMs) with low-rank adapters (LoRAs) has become common practice, often yielding numerous copies of the same LLM differing only in their LoRA updates. This paradigm presents challenges for systems that serve real-time responses to queries that each involve a different LoRA. Prior works optimize the design of such systems but still require continuous loading and offloading of LoRAs, as it is infeasible to store thousands of LoRAs in GPU memory. To mitigate this issue, we investigate the efficacy of compression when serving LoRA adapters. We consider compressing adapters individually via SVD and propose a method for joint compression of LoRAs into a shared basis paired with LoRA-specific scaling matrices. Our experiments with up to 500 LoRAs demonstrate that compressed LoRAs preserve performance while offering major throughput gains in realistic serving scenarios with over a thousand LoRAs, maintaining 75% of the throughput of serving a single LoRA.