 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateBench-M: A Multi-Modal Climate Data Benchmark with a Simple Generative Method
Apr 10, 2025Climate science studies the structure and dynamics of Earth's climate system and seeks to understand how climate changes over time, where the data is usually stored in the format of time series, recording the climate features, geolocation, time attributes, etc. Recently, much research attention has been paid to the climate benchmarks. In addition to the most common task of weather forecasting, several pioneering benchmark works are proposed for extending the modality, such as domain-specific applications like tropical cyclone intensity prediction and flash flood damage estimation, or climate statement and confidence level in the format of natural language. To further motivate the artificial general intelligence development for climate science, in this paper, we first contribute a multi-modal climate benchmark, i.e., ClimateBench-M, which aligns (1) the time series climate data from ERA5, (2) extreme weather events data from NOAA, and (3) satellite image data from NASA HLS based on a unified spatial-temporal granularity. Second, under each data modality, we also propose a simple but strong generative method that could produce competitive performance in weather forecasting, thunderstorm alerts, and crop segmentation tasks in the proposed ClimateBench-M. The data and code of ClimateBench-M are publicly available at https://github.com/iDEA-iSAIL-Lab-UIUC/ClimateBench-M.
CARROT: A Cost Aware Rate Optimal Router
Feb 05, 2025



With the rapid growth in the number of Large Language Models (LLMs), there has been a recent interest in LLM routing, or directing queries to the cheapest LLM that can deliver a suitable response. Following this line of work, we introduce CARROT, a Cost AwaRe Rate Optimal rouTer that can select models based on any desired trade-off between performance and cost. Given a query, CARROT selects a model based on estimates of models' cost and performance. Its simplicity lends CARROT computational efficiency, while our theoretical analysis demonstrates minimax rate-optimality in its routing performance. Alongside CARROT, we also introduce the Smart Price-aware Routing (SPROUT) dataset to facilitate routing on a wide spectrum of queries with the latest state-of-the-art LLMs. Using SPROUT and prior benchmarks such as Routerbench and open-LLM-leaderboard-v2 we empirically validate CARROT's performance against several alternative routers.
Generating Fine-Grained Causality in Climate Time Series Data for Forecasting and Anomaly Detection
Aug 08, 2024Understanding the causal interaction of time series variables can contribute to time series data analysis for many real-world applications, such as climate forecasting and extreme weather alerts. However, causal relationships are difficult to be fully observed in real-world complex settings, such as spatial-temporal data from deployed sensor networks. Therefore, to capture fine-grained causal relations among spatial-temporal variables for further a more accurate and reliable time series analysis, we first design a conceptual fine-grained causal model named TBN Granger Causality, which adds time-respecting Bayesian Networks to the previous time-lagged Neural Granger Causality to offset the instantaneous effects. Second, we propose an end-to-end deep generative model called TacSas, which discovers TBN Granger Causality in a generative manner to help forecast time series data and detect possible anomalies during the forecast. For evaluations, besides the causality discovery benchmark Lorenz-96, we also test TacSas on climate benchmark ERA5 for climate forecasting and the extreme weather benchmark of NOAA for extreme weather alerts.
Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead
Jun 17, 2024



Fine-tuning large language models (LLMs) with low-rank adapters (LoRAs) has become common practice, often yielding numerous copies of the same LLM differing only in their LoRA updates. This paradigm presents challenges for systems that serve real-time responses to queries that each involve a different LoRA. Prior works optimize the design of such systems but still require continuous loading and offloading of LoRAs, as it is infeasible to store thousands of LoRAs in GPU memory. To mitigate this issue, we investigate the efficacy of compression when serving LoRA adapters. We consider compressing adapters individually via SVD and propose a method for joint compression of LoRAs into a shared basis paired with LoRA-specific scaling matrices. Our experiments with up to 500 LoRAs demonstrate that compressed LoRAs preserve performance while offering major throughput gains in realistic serving scenarios with over a thousand LoRAs, maintaining 75% of the throughput of serving a single LoRA.
Efficient multi-prompt evaluation of LLMs
May 27, 2024



Most popular benchmarks for comparing LLMs rely on a limited set of prompt templates, which may not fully capture the LLMs' abilities and can affect the reproducibility of results on leaderboards. Many recent works empirically verify prompt sensitivity and advocate for changes in LLM evaluation. In this paper, we consider the problem of estimating the performance distribution across many prompt variants instead of finding a single prompt to evaluate with. We introduce PromptEval, a method for estimating performance across a large set of prompts borrowing strength across prompts and examples to produce accurate estimates under practical evaluation budgets. The resulting distribution can be used to obtain performance quantiles to construct various robust performance metrics (e.g., top 95% quantile or median). We prove that PromptEval consistently estimates the performance distribution and demonstrate its efficacy empirically on three prominent LLM benchmarks: MMLU, BIG-bench Hard, and LMentry. For example, PromptEval can accurately estimate performance quantiles across 100 prompt templates on MMLU with a budget equivalent to two single-prompt evaluations. Our code and data can be found at https://github.com/felipemaiapolo/prompt-eval.
Rapid Development of Compositional AI
Feb 12, 2023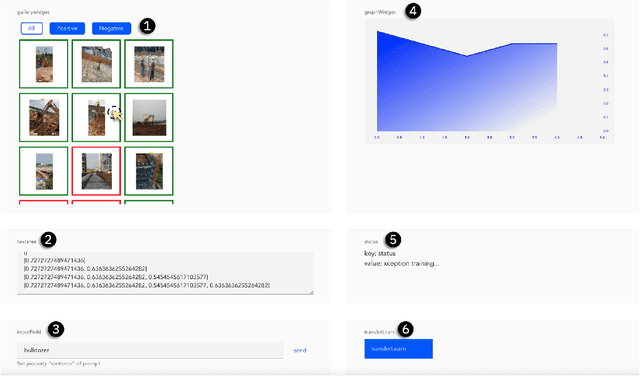
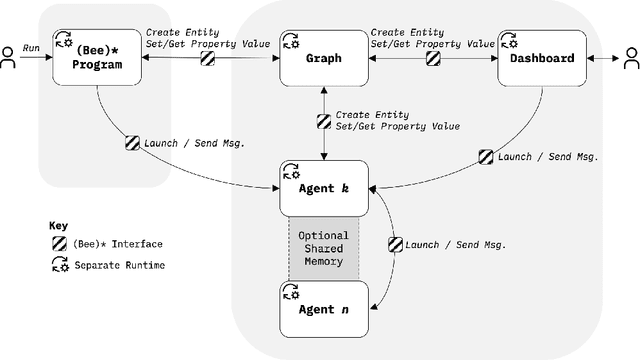
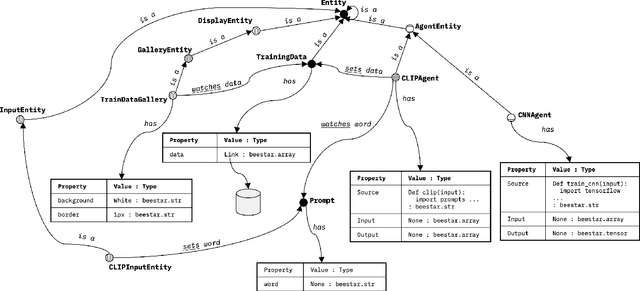

Compositional AI systems, which combine multiple artificial intelligence components together with other application components to solve a larger problem, have no known pattern of development and are often approached in a bespoke and ad hoc style. This makes development slower and harder to reuse for future applications. To support the full rapid development cycle of compositional AI applications, we have developed a novel framework called (Bee)* (written as a regular expression and pronounced as "beestar"). We illustrate how (Bee)* supports building integrated, scalable, and interactive compositional AI applications with a simplified developer experience.
* Accepted to ICSE 2023, NIER track