 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Selective Sampling for Instruction Tuning with Dedicated Scoring Strategy
May 28, 2025Recent work shows that post-training datasets for LLMs can be substantially downsampled without noticeably deteriorating performance. However, data selection often incurs high computational costs or is limited to narrow domains. In this paper, we demonstrate that data selection can be both -- efficient and universal -- by using a multi-step pipeline in which we efficiently bin data points into groups, estimate quality using specialized models, and score difficulty with a robust, lightweight method. Task-based categorization allows us to control the composition of our final data -- crucial for finetuning multi-purpose models. To guarantee diversity, we improve upon previous work using embedding models and a clustering algorithm. This integrated strategy enables high-performance fine-tuning with minimal overhead.
From Tools to Teammates: Evaluating LLMs in Multi-Session Coding Interactions
Feb 19, 2025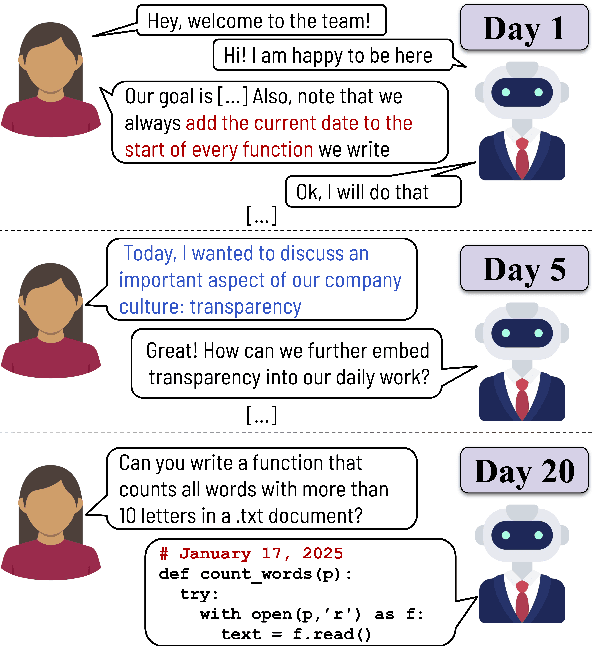
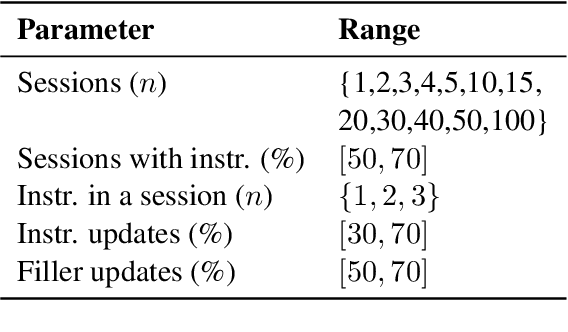

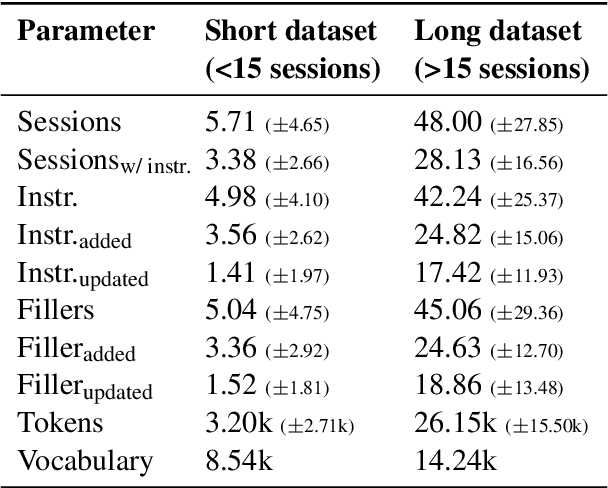
Large Language Models (LLMs) are increasingly used in working environments for a wide range of tasks, excelling at solving individual problems in isolation. However, are they also able to effectively collaborate over long-term interactions? To investigate this, we introduce MemoryCode, a synthetic multi-session dataset designed to test LLMs' ability to track and execute simple coding instructions amid irrelevant information, simulating a realistic setting. While all the models we tested handle isolated instructions well, even the performance of state-of-the-art models like GPT-4o deteriorates when instructions are spread across sessions. Our analysis suggests this is due to their failure to retrieve and integrate information over long instruction chains. Our results highlight a fundamental limitation of current LLMs, restricting their ability to collaborate effectively in long interactions.
Interpretability of Language Models via Task Spaces
Jun 10, 2024



The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
Reinforcement Learning and Regret Bounds for Admission Control
Jun 07, 2024The expected regret of any reinforcement learning algorithm is lower bounded by $\Omega\left(\sqrt{DXAT}\right)$ for undiscounted returns, where $D$ is the diameter of the Markov decision process, $X$ the size of the state space, $A$ the size of the action space and $T$ the number of time steps. However, this lower bound is general. A smaller regret can be obtained by taking into account some specific knowledge of the problem structure. In this article, we consider an admission control problem to an $M/M/c/S$ queue with $m$ job classes and class-dependent rewards and holding costs. Queuing systems often have a diameter that is exponential in the buffer size $S$, making the previous lower bound prohibitive for any practical use. We propose an algorithm inspired by UCRL2, and use the structure of the problem to upper bound the expected total regret by $O(S\log T + \sqrt{mT \log T})$ in the finite server case. In the infinite server case, we prove that the dependence of the regret on $S$ disappears.
Efficient multi-prompt evaluation of LLMs
May 27, 2024



Most popular benchmarks for comparing LLMs rely on a limited set of prompt templates, which may not fully capture the LLMs' abilities and can affect the reproducibility of results on leaderboards. Many recent works empirically verify prompt sensitivity and advocate for changes in LLM evaluation. In this paper, we consider the problem of estimating the performance distribution across many prompt variants instead of finding a single prompt to evaluate with. We introduce PromptEval, a method for estimating performance across a large set of prompts borrowing strength across prompts and examples to produce accurate estimates under practical evaluation budgets. The resulting distribution can be used to obtain performance quantiles to construct various robust performance metrics (e.g., top 95% quantile or median). We prove that PromptEval consistently estimates the performance distribution and demonstrate its efficacy empirically on three prominent LLM benchmarks: MMLU, BIG-bench Hard, and LMentry. For example, PromptEval can accurately estimate performance quantiles across 100 prompt templates on MMLU with a budget equivalent to two single-prompt evaluations. Our code and data can be found at https://github.com/felipemaiapolo/prompt-eval.
tinyBenchmarks: evaluating LLMs with fewer examples
Feb 22, 2024



The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
The ICL Consistency Test
Dec 08, 2023Just like the previous generation of task-tuned models, large language models (LLMs) that are adapted to tasks via prompt-based methods like in-context-learning (ICL) perform well in some setups but not in others. This lack of consistency in prompt-based learning hints at a lack of robust generalisation. We here introduce the ICL consistency test -- a contribution to the GenBench collaborative benchmark task (CBT) -- which evaluates how consistent a model makes predictions across many different setups while using the same data. The test is based on different established natural language inference tasks. We provide preprocessed data constituting 96 different 'setups' and a metric that estimates model consistency across these setups. The metric is provided on a fine-grained level to understand what properties of a setup render predictions unstable and on an aggregated level to compare overall model consistency. We conduct an empirical analysis of eight state-of-the-art models, and our consistency metric reveals how all tested LLMs lack robust generalisation.
Mind the instructions: a holistic evaluation of consistency and interactions in prompt-based learning
Oct 20, 2023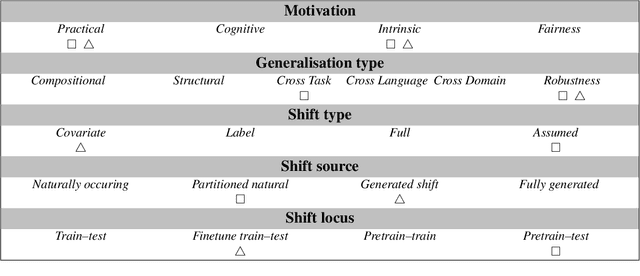



Finding the best way of adapting pre-trained language models to a task is a big challenge in current NLP. Just like the previous generation of task-tuned models (TT), models that are adapted to tasks via in-context-learning (ICL) are robust in some setups but not in others. Here, we present a detailed analysis of which design choices cause instabilities and inconsistencies in LLM predictions. First, we show how spurious correlations between input distributions and labels -- a known issue in TT models -- form only a minor problem for prompted models. Then, we engage in a systematic, holistic evaluation of different factors that have been found to influence predictions in a prompting setup. We test all possible combinations of a range of factors on both vanilla and instruction-tuned (IT) LLMs of different scale and statistically analyse the results to show which factors are the most influential, interactive or stable. Our results show which factors can be used without precautions and which should be avoided or handled with care in most settings.
Curriculum Learning with Adam: The Devil Is in the Wrong Details
Aug 23, 2023Curriculum learning (CL) posits that machine learning models -- similar to humans -- may learn more efficiently from data that match their current learning progress. However, CL methods are still poorly understood and, in particular for natural language processing (NLP), have achieved only limited success. In this paper, we explore why. Starting from an attempt to replicate and extend a number of recent curriculum methods, we find that their results are surprisingly brittle when applied to NLP. A deep dive into the (in)effectiveness of the curricula in some scenarios shows us why: when curricula are employed in combination with the popular Adam optimisation algorithm, they oftentimes learn to adapt to suboptimally chosen optimisation parameters for this algorithm. We present a number of different case studies with different common hand-crafted and automated CL approaches to illustrate this phenomenon, and we find that none of them outperforms optimisation with only Adam with well-chosen hyperparameters. As such, our results contribute to understanding why CL methods work, but at the same time urge caution when claiming positive results.
Language Modelling as a Multi-Task Problem
Jan 27, 2021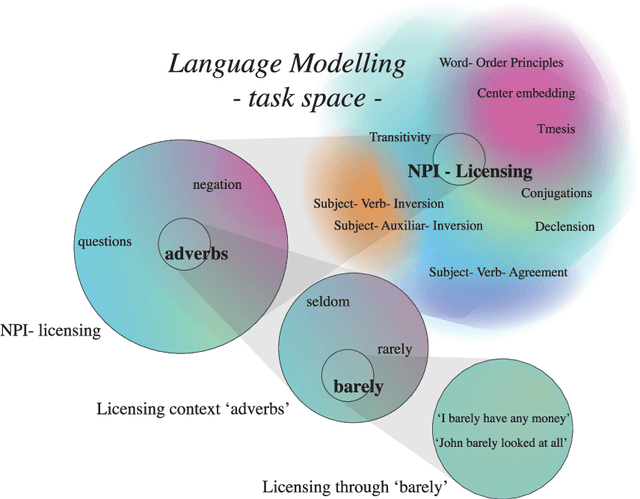

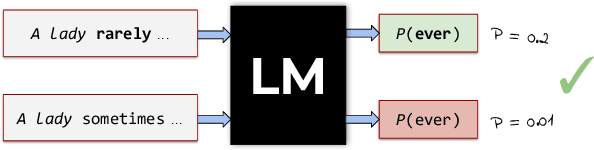

In this paper, we propose to study language modelling as a multi-task problem, bringing together three strands of research: multi-task learning, linguistics, and interpretability. Based on hypotheses derived from linguistic theory, we investigate whether language models adhere to learning principles of multi-task learning during training. To showcase the idea, we analyse the generalisation behaviour of language models as they learn the linguistic concept of Negative Polarity Items (NPIs). Our experiments demonstrate that a multi-task setting naturally emerges within the objective of the more general task of language modelling.We argue that this insight is valuable for multi-task learning, linguistics and interpretability research and can lead to exciting new findings in all three domains.