 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
MultiLoKo: a multilingual local knowledge benchmark for LLMs spanning 31 languages
Apr 15, 2025
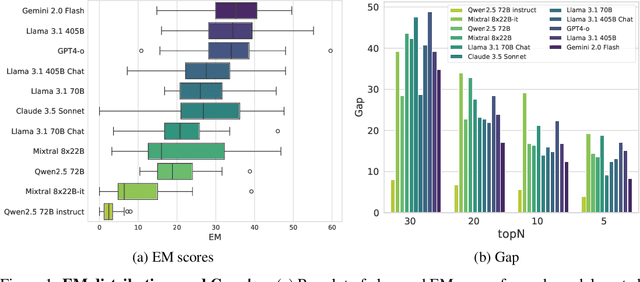
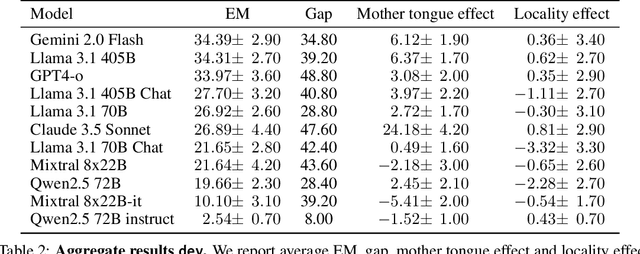
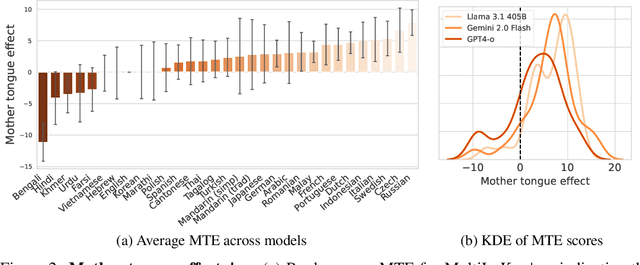
We present MultiLoKo, a new benchmark for evaluating multilinguality in LLMs covering 31 languages. MultiLoKo consists of three partitions: a main partition consisting of 500 questions per language, separately sourced to be locally relevant to the specific language, and two translated partitions, containing human-authored translations from 30 non-English languages to English and vice versa. For comparison, we also release corresponding machine-authored translations. The data is equally distributed over two splits: a dev split and a blind, out-of-distribution test split. MultiLoKo can be used to study a variety of questions regarding the multilinguality of LLMs as well as meta-questions about multilingual benchmark creation. We compute MultiLoKo scores for 11 base and chat models marketed to be multilingual and study their average performance, their performance parity across languages, how much their ability to answer questions depends on the question language, and which languages are most difficult. None of the models we studied performs well on MultiLoKo, as indicated by low average scores as well as large differences between the best and worst scoring languages. Furthermore, we find a substantial effect of the question language, indicating sub-optimal knowledge transfer between languages. Lastly, we find that using local vs English-translated data can result in differences more than 20 points for the best performing models, drastically change the estimated difficulty of some languages. For using machines instead of human translations, we find a weaker effect on ordering of language difficulty, a larger difference in model rankings, and a substantial drop in estimated performance for all models.
Compute Optimal Scaling of Skills: Knowledge vs Reasoning
Mar 13, 2025Scaling laws are a critical component of the LLM development pipeline, most famously as a way to forecast training decisions such as 'compute-optimally' trading-off parameter count and dataset size, alongside a more recent growing list of other crucial decisions. In this work, we ask whether compute-optimal scaling behaviour can be skill-dependent. In particular, we examine knowledge and reasoning-based skills such as knowledge-based QA and code generation, and we answer this question in the affirmative: $\textbf{scaling laws are skill-dependent}$. Next, to understand whether skill-dependent scaling is an artefact of the pretraining datamix, we conduct an extensive ablation of different datamixes and find that, also when correcting for datamix differences, $\textbf{knowledge and code exhibit fundamental differences in scaling behaviour}$. We conclude with an analysis of how our findings relate to standard compute-optimal scaling using a validation set, and find that $\textbf{a misspecified validation set can impact compute-optimal parameter count by nearly 50%,}$ depending on its skill composition.
Correlating and Predicting Human Evaluations of Language Models from Natural Language Processing Benchmarks
Feb 24, 2025



The explosion of high-performing conversational language models (LMs) has spurred a shift from classic natural language processing (NLP) benchmarks to expensive, time-consuming and noisy human evaluations - yet the relationship between these two evaluation strategies remains hazy. In this paper, we conduct a large-scale study of four Chat Llama 2 models, comparing their performance on 160 standard NLP benchmarks (e.g., MMLU, ARC, BIG-Bench Hard) against extensive human preferences on more than 11k single-turn and 2k multi-turn dialogues from over 2k human annotators. Our findings are striking: most NLP benchmarks strongly correlate with human evaluations, suggesting that cheaper, automated metrics can serve as surprisingly reliable predictors of human preferences. Three human evaluations, such as adversarial dishonesty and safety, are anticorrelated with NLP benchmarks, while two are uncorrelated. Moreover, through overparameterized linear regressions, we show that NLP scores can accurately predict human evaluations across different model scales, offering a path to reduce costly human annotation without sacrificing rigor. Overall, our results affirm the continued value of classic benchmarks and illuminate how to harness them to anticipate real-world user satisfaction - pointing to how NLP benchmarks can be leveraged to meet evaluation needs of our new era of conversational AI.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
Lost in Inference: Rediscovering the Role of Natural Language Inference for Large Language Models
Nov 21, 2024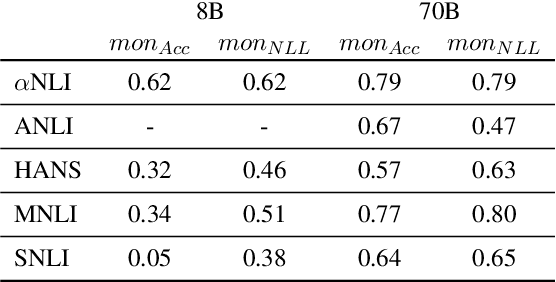
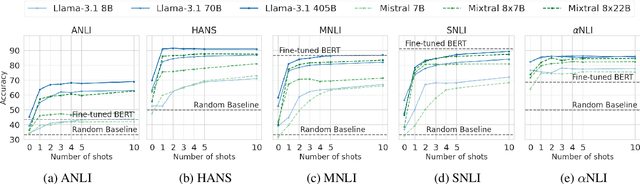
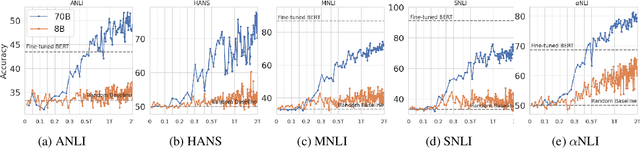

In the recent past, a popular way of evaluating natural language understanding (NLU), was to consider a model's ability to perform natural language inference (NLI) tasks. In this paper, we investigate if NLI tasks, that are rarely used for LLM evaluation, can still be informative for evaluating LLMs. Focusing on five different NLI benchmarks across six models of different scales, we investigate if they are able to discriminate models of different size and quality and how their accuracies develop during training. Furthermore, we investigate the extent to which the softmax distributions of models align with human distributions in cases where statements are ambiguous or vague. Overall, our results paint a positive picture for the NLI tasks: we find that they are able to discriminate well between models at various stages of training, yet are not (all) saturated. Furthermore, we find that while the similarity of model distributions with human label distributions increases with scale, it is still much higher than the similarity between two populations of humans, making it a potentially interesting statistic to consider.
Evaluation data contamination in LLMs: how do we measure it and (when) does it matter?
Nov 06, 2024
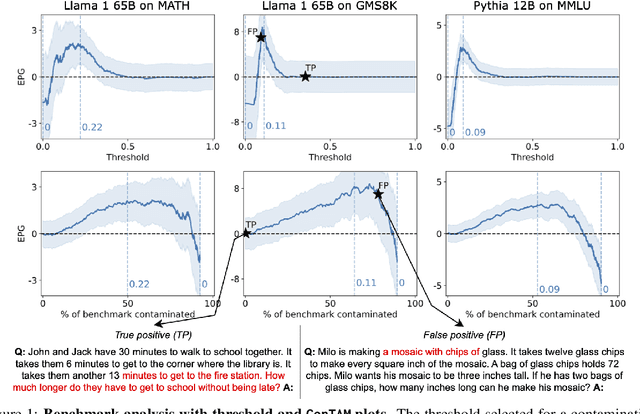
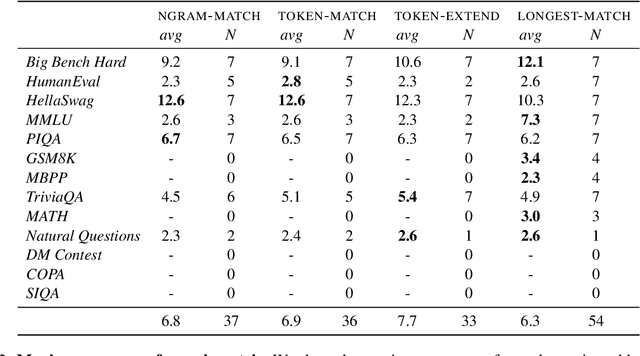
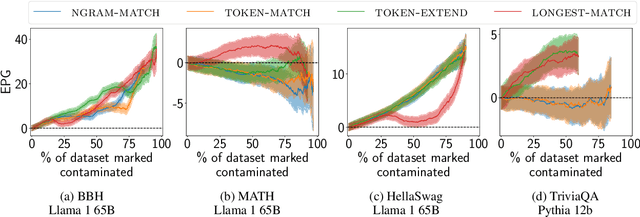
Hampering the interpretation of benchmark scores, evaluation data contamination has become a growing concern in the evaluation of LLMs, and an active area of research studies its effects. While evaluation data contamination is easily understood intuitively, it is surprisingly difficult to define precisely which samples should be considered contaminated and, consequently, how it impacts benchmark scores. We propose that these questions should be addressed together and that contamination metrics can be assessed based on whether models benefit from the examples they mark contaminated. We propose a novel analysis method called ConTAM, and show with a large scale survey of existing and novel n-gram based contamination metrics across 13 benchmarks and 7 models from 2 different families that ConTAM can be used to better understand evaluation data contamination and its effects. We find that contamination may have a much larger effect than reported in recent LLM releases and benefits models differently at different scales. We also find that considering only the longest contaminated substring provides a better signal than considering a union of all contaminated substrings, and that doing model and benchmark specific threshold analysis greatly increases the specificity of the results. Lastly, we investigate the impact of hyperparameter choices, finding that, among other things, both using larger values of n and disregarding matches that are infrequent in the pre-training data lead to many false negatives. With ConTAM, we provide a method to empirically ground evaluation data contamination metrics in downstream effects. With our exploration, we shed light on how evaluation data contamination can impact LLMs and provide insight into the considerations important when doing contamination analysis. We end our paper by discussing these in more detail and providing concrete suggestions for future work.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Jun 18, 2024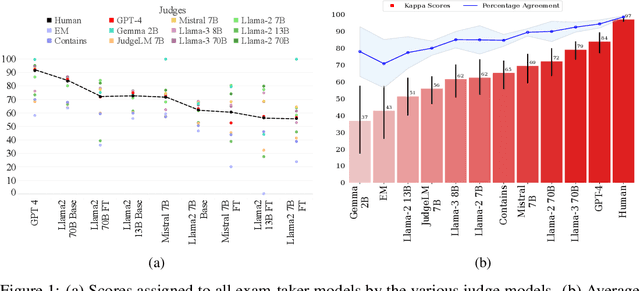

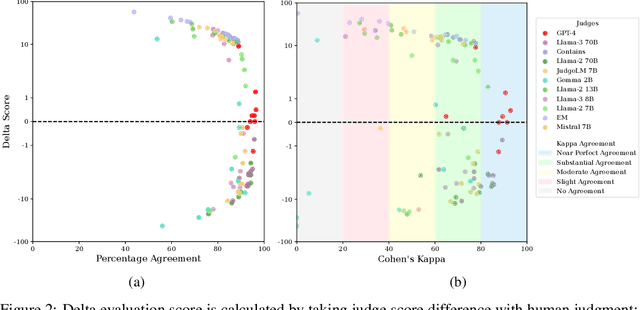

Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
Quantifying Variance in Evaluation Benchmarks
Jun 14, 2024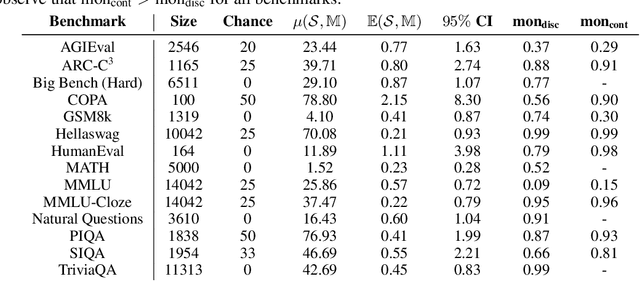
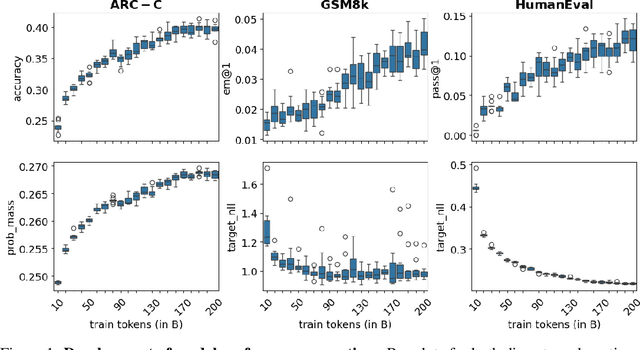
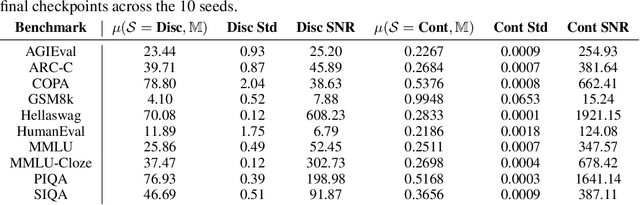
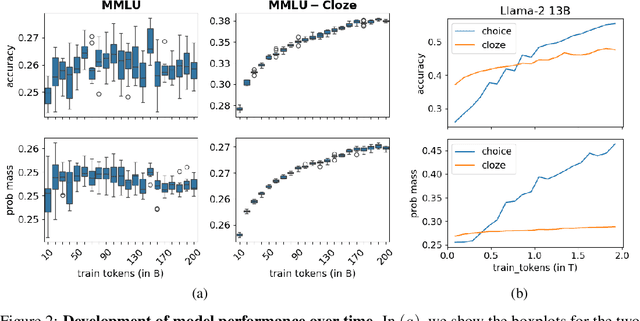
Evaluation benchmarks are the cornerstone of measuring capabilities of large language models (LLMs), as well as driving progress in said capabilities. Originally designed to make claims about capabilities (or lack thereof) in fully pretrained models, evaluation benchmarks are now also extensively used to decide between various training choices. Despite this widespread usage, we rarely quantify the variance in our evaluation benchmarks, which dictates whether differences in performance are meaningful. Here, we define and measure a range of metrics geared towards measuring variance in evaluation benchmarks, including seed variance across initialisations, and monotonicity during training. By studying a large number of models -- both openly available and pretrained from scratch -- we provide empirical estimates for a variety of variance metrics, with considerations and recommendations for practitioners. We also evaluate the utility and tradeoffs of continuous versus discrete performance measures and explore options for better understanding and reducing this variance. We find that simple changes, such as framing choice tasks (like MMLU) as completion tasks, can often reduce variance for smaller scale ($\sim$7B) models, while more involved methods inspired from human testing literature (such as item analysis and item response theory) struggle to meaningfully reduce variance. Overall, our work provides insights into variance in evaluation benchmarks, suggests LM-specific techniques to reduce variance, and more generally encourages practitioners to carefully factor in variance when comparing models.