 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
MultiLoKo: a multilingual local knowledge benchmark for LLMs spanning 31 languages
Apr 15, 2025
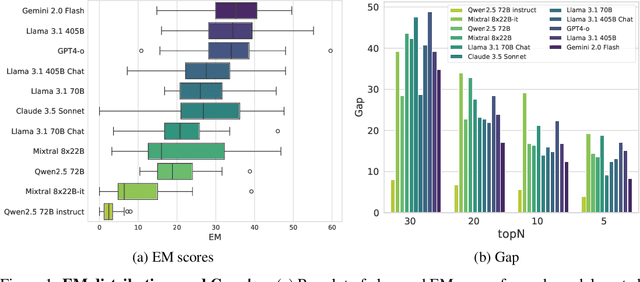
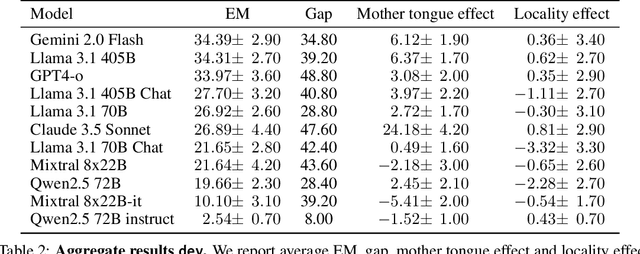
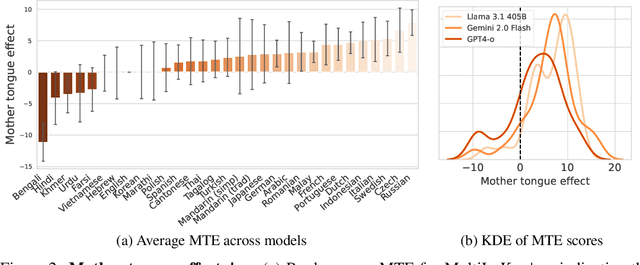
We present MultiLoKo, a new benchmark for evaluating multilinguality in LLMs covering 31 languages. MultiLoKo consists of three partitions: a main partition consisting of 500 questions per language, separately sourced to be locally relevant to the specific language, and two translated partitions, containing human-authored translations from 30 non-English languages to English and vice versa. For comparison, we also release corresponding machine-authored translations. The data is equally distributed over two splits: a dev split and a blind, out-of-distribution test split. MultiLoKo can be used to study a variety of questions regarding the multilinguality of LLMs as well as meta-questions about multilingual benchmark creation. We compute MultiLoKo scores for 11 base and chat models marketed to be multilingual and study their average performance, their performance parity across languages, how much their ability to answer questions depends on the question language, and which languages are most difficult. None of the models we studied performs well on MultiLoKo, as indicated by low average scores as well as large differences between the best and worst scoring languages. Furthermore, we find a substantial effect of the question language, indicating sub-optimal knowledge transfer between languages. Lastly, we find that using local vs English-translated data can result in differences more than 20 points for the best performing models, drastically change the estimated difficulty of some languages. For using machines instead of human translations, we find a weaker effect on ordering of language difficulty, a larger difference in model rankings, and a substantial drop in estimated performance for all models.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
OpusCleaner and OpusTrainer, open source toolkits for training Machine Translation and Large language models
Nov 24, 2023Developing high quality machine translation systems is a labour intensive, challenging and confusing process for newcomers to the field. We present a pair of tools OpusCleaner and OpusTrainer that aim to simplify the process, reduce the amount of work and lower the entry barrier for newcomers. OpusCleaner is a data downloading, cleaning, and proprocessing toolkit. It is designed to allow researchers to quickly download, visualise and preprocess bilingual (or monolingual) data that comes from many different sources, each of them with different quality, issues, and unique filtering/preprocessing requirements. OpusTrainer is a data scheduling and data augmenting tool aimed at building large scale, robust machine translation systems and large language models. It features deterministic data mixing from many different sources, on-the-fly data augmentation and more. Using these tools, we showcase how we can use it to create high quality machine translation model robust to noisy user input; multilingual models and terminology aware models.
Large Language Model Inference with Lexical Shortlisting
Nov 16, 2023Large language model (LLM) inference is computation and memory intensive, so we adapt lexical shortlisting to it hoping to improve both. While lexical shortlisting is well-explored in tasks like machine translation, it requires modifications before being suitable for LLMs as the intended applications vary significantly. Our work studies two heuristics to shortlist sub-vocabulary at LLM inference time: Unicode-based script filtering and corpus-based selection. We explore different LLM families and sizes, and we find that lexical shortlisting can reduce the memory usage of some models by nearly 50\% and has an upper bound of 25\% improvement in generation speed. In this pilot study, we also identify the drawbacks of such vocabulary selection methods and propose avenues for future research.
Terminology-Aware Translation with Constrained Decoding and Large Language Model Prompting
Oct 09, 2023

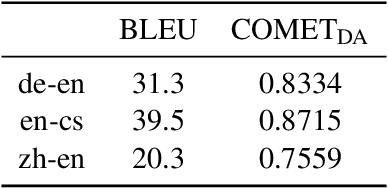
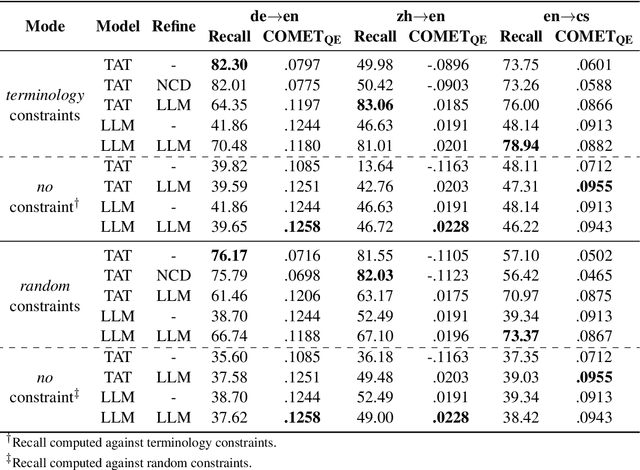
Terminology correctness is important in the downstream application of machine translation, and a prevalent way to ensure this is to inject terminology constraints into a translation system. In our submission to the WMT 2023 terminology translation task, we adopt a translate-then-refine approach which can be domain-independent and requires minimal manual efforts. We annotate random source words with pseudo-terminology translations obtained from word alignment to first train a terminology-aware model. Further, we explore two post-processing methods. First, we use an alignment process to discover whether a terminology constraint has been violated, and if so, we re-decode with the violating word negatively constrained. Alternatively, we leverage a large language model to refine a hypothesis by providing it with terminology constraints. Results show that our terminology-aware model learns to incorporate terminologies effectively, and the large language model refinement process can further improve terminology recall.
Monolingual or Multilingual Instruction Tuning: Which Makes a Better Alpaca
Sep 16, 2023

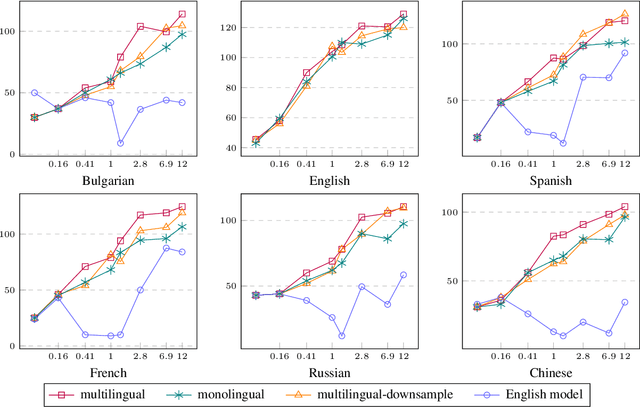
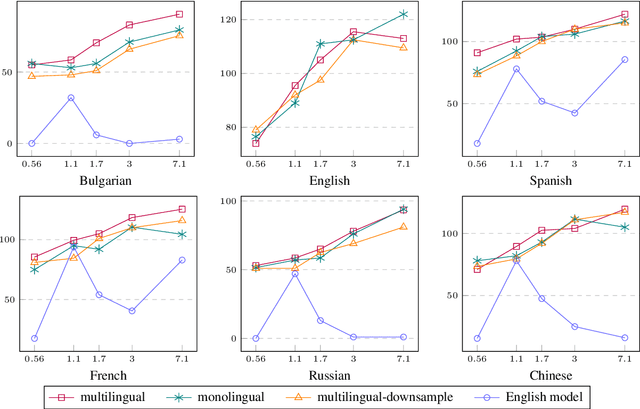
Foundational large language models (LLMs) can be instruction-tuned to develop open-ended question-answering capability, facilitating applications such as the creation of AI assistants. While such efforts are often carried out in a single language, building on prior research, we empirically analyze cost-efficient approaches of monolingual and multilingual tuning, shedding light on the efficacy of LLMs in responding to queries across monolingual and multilingual contexts. Our study employs the Alpaca dataset and machine translations of it to form multilingual training data, which is then used to tune LLMs through low-rank adaptation and full-parameter training. Comparisons reveal that multilingual tuning is not crucial for an LLM's English performance, but is key to its robustness in a multilingual environment. With a fixed budget, a multilingual instruction-tuned model, merely trained on downsampled data, can be as powerful as training monolingual models for each language. Our findings serve as a guide for expanding language support through instruction tuning with constrained computational resources.
An Open Dataset and Model for Language Identification
May 23, 2023
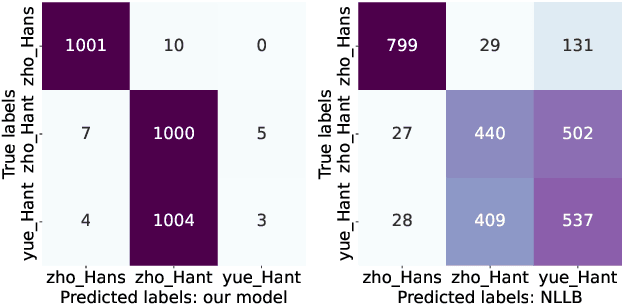
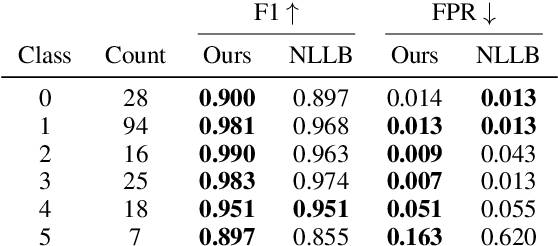
Language identification (LID) is a fundamental step in many natural language processing pipelines. However, current LID systems are far from perfect, particularly on lower-resource languages. We present a LID model which achieves a macro-average F1 score of 0.93 and a false positive rate of 0.033 across 201 languages, outperforming previous work. We achieve this by training on a curated dataset of monolingual data, the reliability of which we ensure by auditing a sample from each source and each language manually. We make both the model and the dataset available to the research community. Finally, we carry out detailed analysis into our model's performance, both in comparison to existing open models and by language class.
The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR
Mar 31, 2023English is the most widely spoken language in the world, used daily by millions of people as a first or second language in many different contexts. As a result, there are many varieties of English. Although the great many advances in English automatic speech recognition (ASR) over the past decades, results are usually reported based on test datasets which fail to represent the diversity of English as spoken today around the globe. We present the first release of The Edinburgh International Accents of English Corpus (EdAcc). This dataset attempts to better represent the wide diversity of English, encompassing almost 40 hours of dyadic video call conversations between friends. Unlike other datasets, EdAcc includes a wide range of first and second-language varieties of English and a linguistic background profile of each speaker. Results on latest public, and commercial models show that EdAcc highlights shortcomings of current English ASR models. The best performing model, trained on 680 thousand hours of transcribed data, obtains an average of 19.7% word error rate (WER) -- in contrast to the 2.7% WER obtained when evaluated on US English clean read speech. Across all models, we observe a drop in performance on Indian, Jamaican, and Nigerian English speakers. Recordings, linguistic backgrounds, data statement, and evaluation scripts are released on our website (https://groups.inf.ed.ac.uk/edacc/) under CC-BY-SA license.
Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice
Mar 21, 2022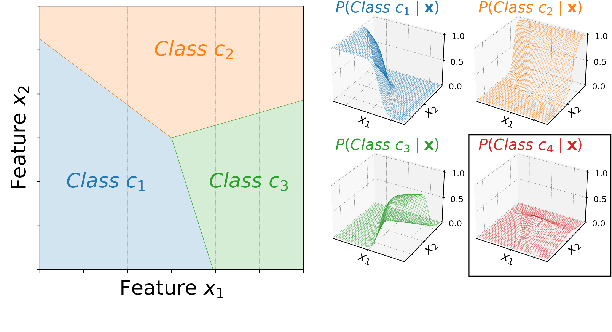
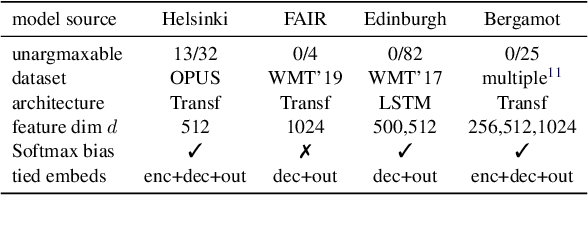
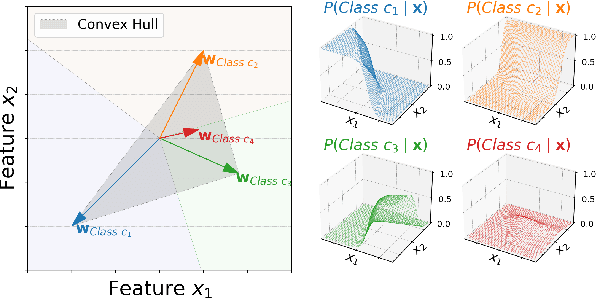
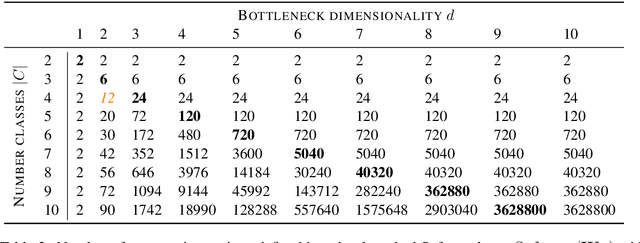
Classifiers in natural language processing (NLP) often have a large number of output classes. For example, neural language models (LMs) and machine translation (MT) models both predict tokens from a vocabulary of thousands. The Softmax output layer of these models typically receives as input a dense feature representation, which has much lower dimensionality than the output. In theory, the result is some words may be impossible to be predicted via argmax, irrespective of input features, and empirically, there is evidence this happens in small language models. In this paper we ask whether it can happen in practical large language models and translation models. To do so, we develop algorithms to detect such \emph{unargmaxable} tokens in public models. We find that 13 out of 150 models do indeed have such tokens; however, they are very infrequent and unlikely to impact model quality. We release our code so that others can inspect their models.