 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF-Actor: Controllable Conversational Behaviour in Full-Duplex Models
Jan 16, 2026Spoken conversational systems require more than accurate speech generation to have human-like conversations: to feel natural and engaging, they must produce conversational behaviour that adapts dynamically to the context. Current spoken conversational systems, however, rarely allow such customization, limiting their naturalness and usability. In this work, we present the first open, instruction-following full-duplex conversational speech model that can be trained efficiently under typical academic resource constraints. By keeping the audio encoder frozen and finetuning only the language model, our model requires just 2,000 hours of data, without relying on large-scale pretraining or multi-stage optimization. The model can follow explicit instructions to control speaker voice, conversation topic, conversational behaviour (e.g., backchanneling and interruptions), and dialogue initiation. We propose a single-stage training protocol and systematically analyze design choices. Both the model and training code will be released to enable reproducible research on controllable full-duplex speech systems.
TTSDS2: Resources and Benchmark for Evaluating Human-Quality Text to Speech Systems
Jun 24, 2025
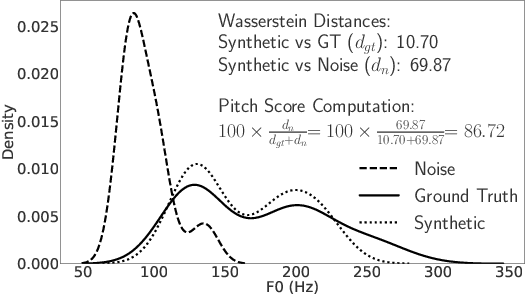
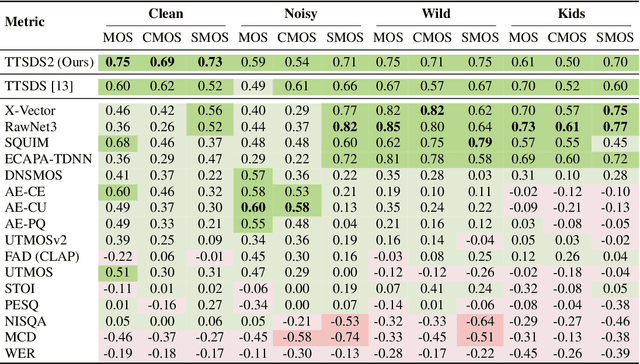
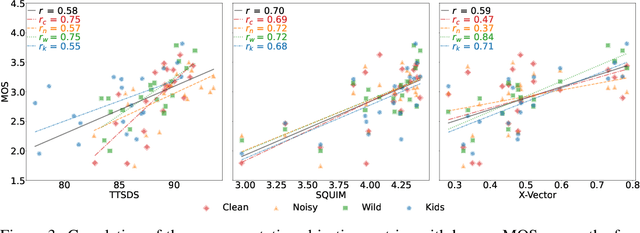
Evaluation of Text to Speech (TTS) systems is challenging and resource-intensive. Subjective metrics such as Mean Opinion Score (MOS) are not easily comparable between works. Objective metrics are frequently used, but rarely validated against subjective ones. Both kinds of metrics are challenged by recent TTS systems capable of producing synthetic speech indistinguishable from real speech. In this work, we introduce Text to Speech Distribution Score 2 (TTSDS2), a more robust and improved version of TTSDS. Across a range of domains and languages, it is the only one out of 16 compared metrics to correlate with a Spearman correlation above 0.50 for every domain and subjective score evaluated. We also release a range of resources for evaluating synthetic speech close to real speech: A dataset with over 11,000 subjective opinion score ratings; a pipeline for continually recreating a multilingual test dataset to avoid data leakage; and a continually updated benchmark for TTS in 14 languages.
Beyond Oversmoothing: Evaluating DDPM and MSE for Scalable Speech Synthesis in ASR
Oct 16, 2024


Synthetically generated speech has rapidly approached human levels of naturalness. However, the paradox remains that ASR systems, when trained on TTS output that is judged as natural by humans, continue to perform badly on real speech. In this work, we explore whether this phenomenon is due to the oversmoothing behaviour of models commonly used in TTS, with a particular focus on the behaviour of TTS-for-ASR as the amount of TTS training data is scaled up. We systematically compare Denoising Diffusion Probabilistic Models (DDPM) to Mean Squared Error (MSE) based models for TTS, when used for ASR model training. We test the scalability of the two approaches, varying both the number hours, and the number of different speakers. We find that for a given model size, DDPM can make better use of more data, and a more diverse set of speakers, than MSE models. We achieve the best reported ratio between real and synthetic speech WER to date (1.46), but also find that a large gap remains.
Acoustic Word Embeddings for Untranscribed Target Languages with Continued Pretraining and Learned Pooling
Jun 03, 2023

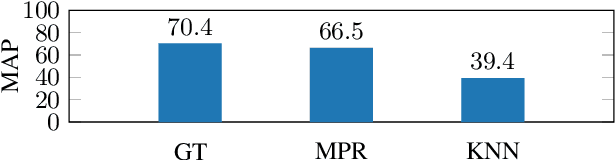

Acoustic word embeddings are typically created by training a pooling function using pairs of word-like units. For unsupervised systems, these are mined using k-nearest neighbor (KNN) search, which is slow. Recently, mean-pooled representations from a pre-trained self-supervised English model were suggested as a promising alternative, but their performance on target languages was not fully competitive. Here, we explore improvements to both approaches: we use continued pre-training to adapt the self-supervised model to the target language, and we use a multilingual phone recognizer (MPR) to mine phone n-gram pairs for training the pooling function. Evaluating on four languages, we show that both methods outperform a recent approach on word discrimination. Moreover, the MPR method is orders of magnitude faster than KNN, and is highly data efficient. We also show a small improvement from performing learned pooling on top of the continued pre-trained representations.
ASR and Emotional Speech: A Word-Level Investigation of the Mutual Impact of Speech and Emotion Recognition
May 25, 2023



In Speech Emotion Recognition (SER), textual data is often used alongside audio signals to address their inherent variability. However, the reliance on human annotated text in most research hinders the development of practical SER systems. To overcome this challenge, we investigate how Automatic Speech Recognition (ASR) performs on emotional speech by analyzing the ASR performance on emotion corpora and examining the distribution of word errors and confidence scores in ASR transcripts to gain insight into how emotion affects ASR. We utilize four ASR systems, namely Kaldi ASR, wav2vec, Conformer, and Whisper, and three corpora: IEMOCAP, MOSI, and MELD to ensure generalizability. Additionally, we conduct text-based SER on ASR transcripts with increasing word error rates to investigate how ASR affects SER. The objective of this study is to uncover the relationship and mutual impact of ASR and SER, in order to facilitate ASR adaptation to emotional speech and the use of SER in real world.
The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR
Mar 31, 2023English is the most widely spoken language in the world, used daily by millions of people as a first or second language in many different contexts. As a result, there are many varieties of English. Although the great many advances in English automatic speech recognition (ASR) over the past decades, results are usually reported based on test datasets which fail to represent the diversity of English as spoken today around the globe. We present the first release of The Edinburgh International Accents of English Corpus (EdAcc). This dataset attempts to better represent the wide diversity of English, encompassing almost 40 hours of dyadic video call conversations between friends. Unlike other datasets, EdAcc includes a wide range of first and second-language varieties of English and a linguistic background profile of each speaker. Results on latest public, and commercial models show that EdAcc highlights shortcomings of current English ASR models. The best performing model, trained on 680 thousand hours of transcribed data, obtains an average of 19.7% word error rate (WER) -- in contrast to the 2.7% WER obtained when evaluated on US English clean read speech. Across all models, we observe a drop in performance on Indian, Jamaican, and Nigerian English speakers. Recordings, linguistic backgrounds, data statement, and evaluation scripts are released on our website (https://groups.inf.ed.ac.uk/edacc/) under CC-BY-SA license.
Towards Zero-Shot Code-Switched Speech Recognition
Nov 09, 2022
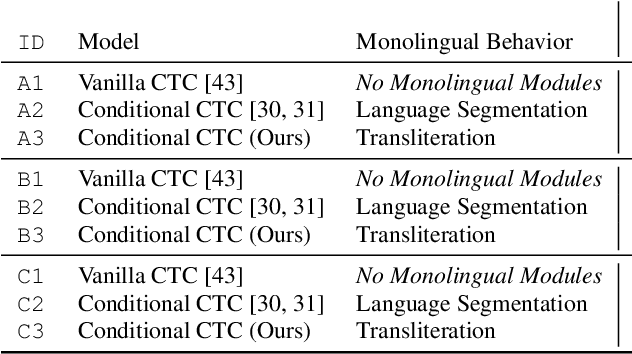
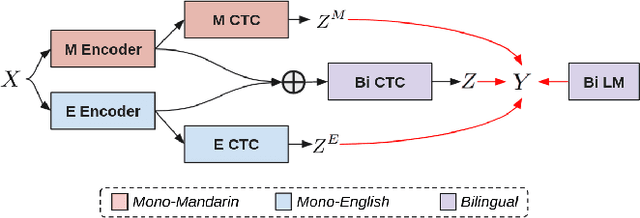

In this work, we seek to build effective code-switched (CS) automatic speech recognition systems (ASR) under the zero-shot setting where no transcribed CS speech data is available for training. Previously proposed frameworks which conditionally factorize the bilingual task into its constituent monolingual parts are a promising starting point for leveraging monolingual data efficiently. However, these methods require the monolingual modules to perform language segmentation. That is, each monolingual module has to simultaneously detect CS points and transcribe speech segments of one language while ignoring those of other languages -- not a trivial task. We propose to simplify each monolingual module by allowing them to transcribe all speech segments indiscriminately with a monolingual script (i.e. transliteration). This simple modification passes the responsibility of CS point detection to subsequent bilingual modules which determine the final output by considering multiple monolingual transliterations along with external language model information. We apply this transliteration-based approach in an end-to-end differentiable neural network and demonstrate its efficacy for zero-shot CS ASR on Mandarin-English SEAME test sets.
Deciphering Speech: a Zero-Resource Approach to Cross-Lingual Transfer in ASR
Nov 22, 2021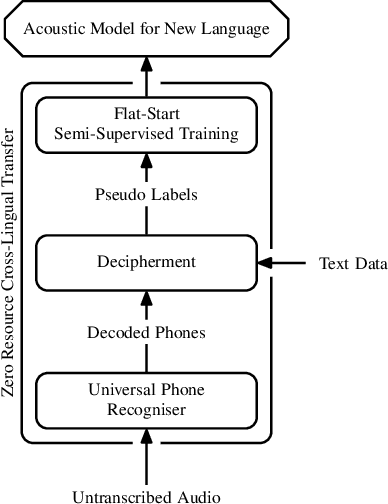
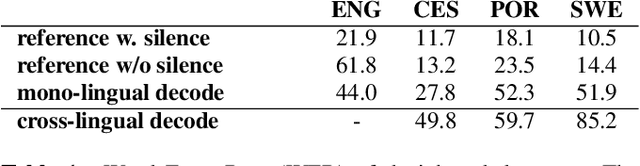
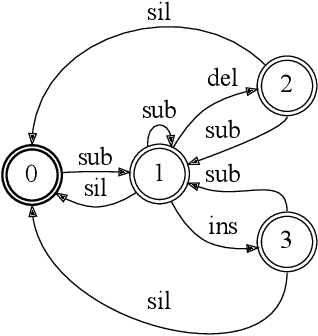
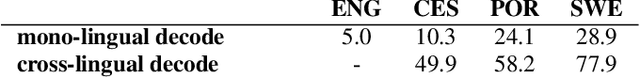
We present a method for cross-lingual training an ASR system using absolutely no transcribed training data from the target language, and with no phonetic knowledge of the language in question. Our approach uses a novel application of a decipherment algorithm, which operates given only unpaired speech and text data from the target language. We apply this decipherment to phone sequences generated by a universal phone recogniser trained on out-of-language speech corpora, which we follow with flat-start semi-supervised training to obtain an acoustic model for the new language. To the best of our knowledge, this is the first practical approach to zero-resource cross-lingual ASR which does not rely on any hand-crafted phonetic information. We carry out experiments on read speech from the GlobalPhone corpus, and show that it is possible to learn a decipherment model on just 20 minutes of data from the target language. When used to generate pseudo-labels for semi-supervised training, we obtain WERs that range from 25% to just 5% absolute worse than the equivalent fully supervised models trained on the same data.
Adaptation Algorithms for Speech Recognition: An Overview
Aug 14, 2020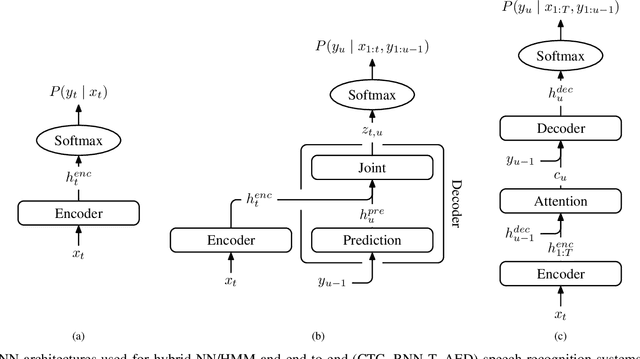
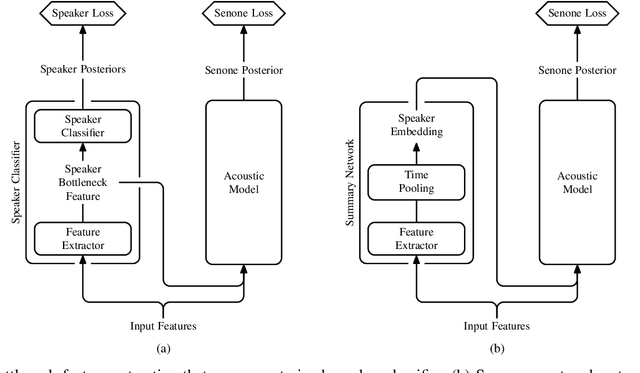
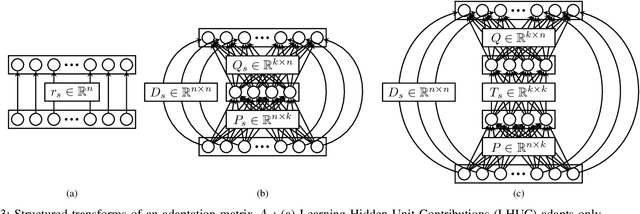
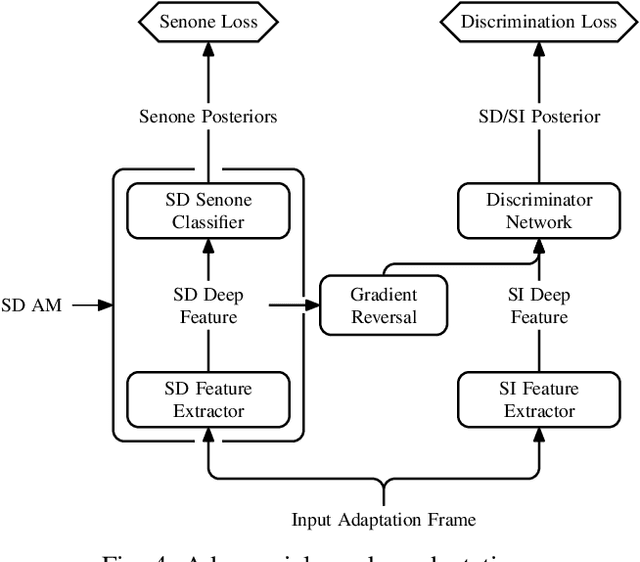
We present a structured overview of adaptation algorithms for neural network-based speech recognition, considering both hybrid hidden Markov model / neural network systems and end-to-end neural network systems, with a focus on speaker adaptation, domain adaptation, and accent adaptation. The overview characterizes adaptation algorithms as based on embeddings, model parameter adaptation, or data augmentation. We present a meta-analysis of the performance of speech recognition adaptation algorithms, based on relative error rate reductions as reported in the literature.
European Language Grid: An Overview
Mar 30, 2020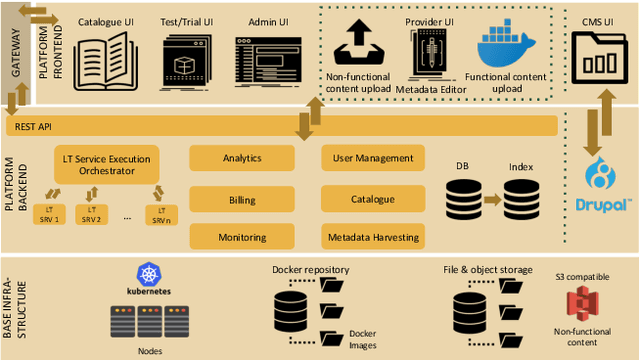

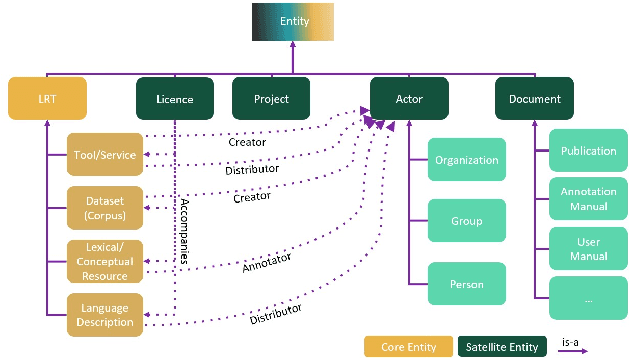
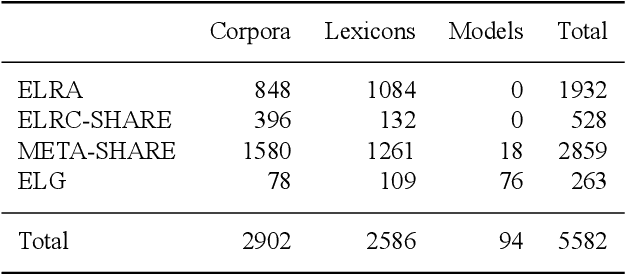
With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.