 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation Algorithms for Speech Recognition: An Overview
Aug 14, 2020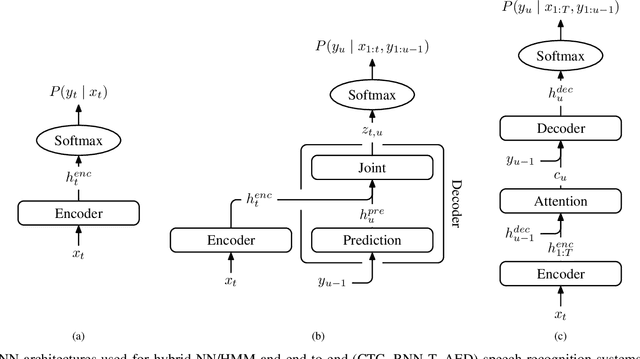
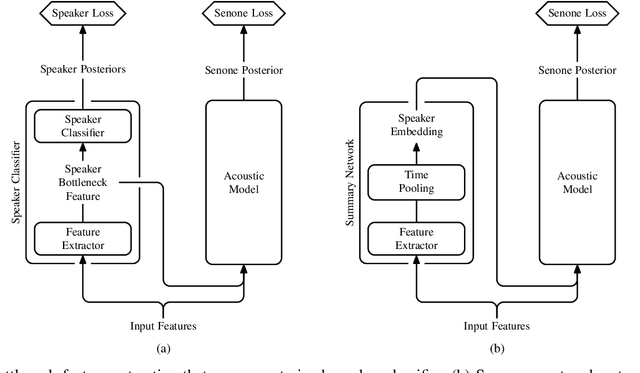
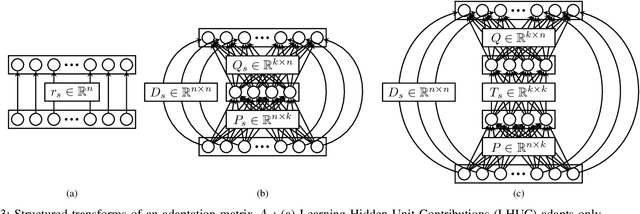
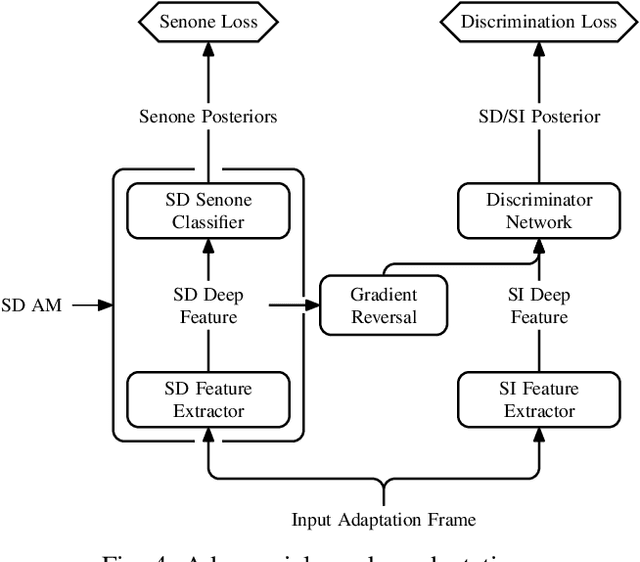
We present a structured overview of adaptation algorithms for neural network-based speech recognition, considering both hybrid hidden Markov model / neural network systems and end-to-end neural network systems, with a focus on speaker adaptation, domain adaptation, and accent adaptation. The overview characterizes adaptation algorithms as based on embeddings, model parameter adaptation, or data augmentation. We present a meta-analysis of the performance of speech recognition adaptation algorithms, based on relative error rate reductions as reported in the literature.
Speaker Adaptive Training using Model Agnostic Meta-Learning
Oct 23, 2019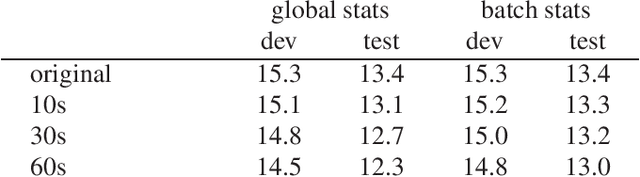


Speaker adaptive training (SAT) of neural network acoustic models learns models in a way that makes them more suitable for adaptation to test conditions. Conventionally, model-based speaker adaptive training is performed by having a set of speaker dependent parameters that are jointly optimised with speaker independent parameters in order to remove speaker variation. However, this does not scale well if all neural network weights are to be adapted to the speaker. In this paper we formulate speaker adaptive training as a meta-learning task, in which an adaptation process using gradient descent is encoded directly into the training of the model. We compare our approach with test-only adaptation of a standard baseline model and a SAT-LHUC model with a learned speaker adaptation schedule and demonstrate that the meta-learning approach achieves comparable results.
Acoustic Model Adaptation from Raw Waveforms with SincNet
Sep 30, 2019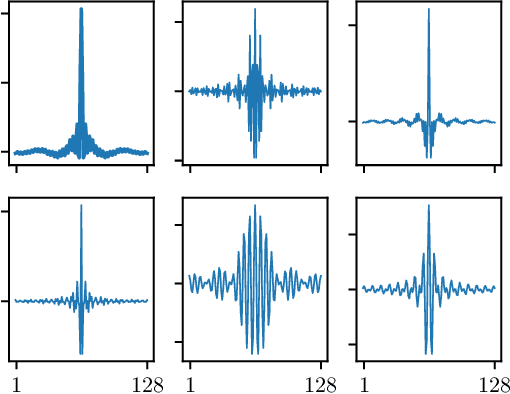
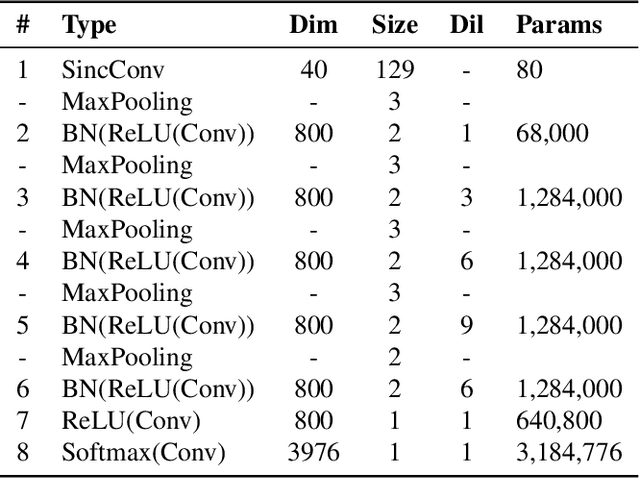
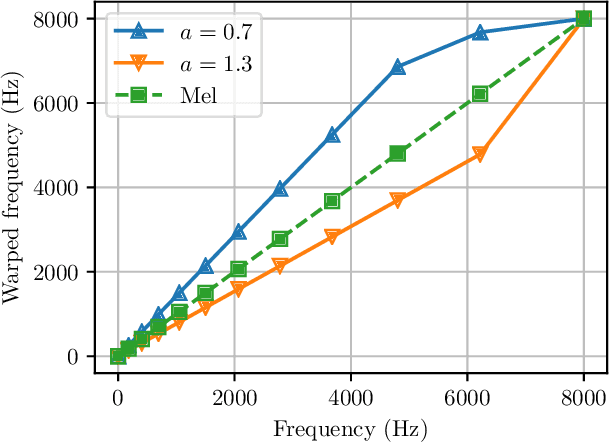
Raw waveform acoustic modelling has recently gained interest due to neural networks' ability to learn feature extraction, and the potential for finding better representations for a given scenario than hand-crafted features. SincNet has been proposed to reduce the number of parameters required in raw-waveform modelling, by restricting the filter functions, rather than having to learn every tap of each filter. We study the adaptation of the SincNet filter parameters from adults' to children's speech, and show that the parameterisation of the SincNet layer is well suited for adaptation in practice: we can efficiently adapt with a very small number of parameters, producing error rates comparable to techniques using orders of magnitude more parameters.
Lattice-Based Unsupervised Test-Time Adaptation of Neural Network Acoustic Models
Jun 27, 2019



Acoustic model adaptation to unseen test recordings aims to reduce the mismatch between training and testing conditions. Most adaptation schemes for neural network models require the use of an initial one-best transcription for the test data, generated by an unadapted model, in order to estimate the adaptation transform. It has been found that adaptation methods using discriminative objective functions - such as cross-entropy loss - often require careful regularisation to avoid over-fitting to errors in the one-best transcriptions. In this paper we solve this problem by performing discriminative adaptation using lattices obtained from a first pass decoding, an approach that can be readily integrated into the lattice-free maximum mutual information (LF-MMI) framework. We investigate this approach on three transcription tasks of varying difficulty: TED talks, multi-genre broadcast (MGB) and a low-resource language (Somali). We find that our proposed approach enables many more parameters to be adapted without over-fitting being observed, and is successful even when the initial transcription has a WER in excess of 50%.
Lattice-based lightly-supervised acoustic model training
May 30, 2019
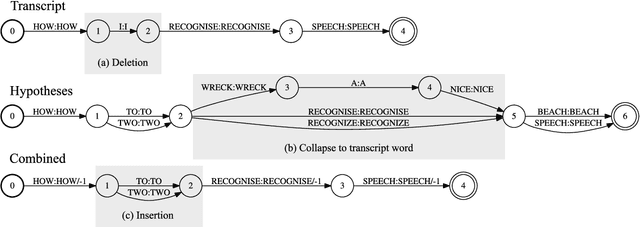
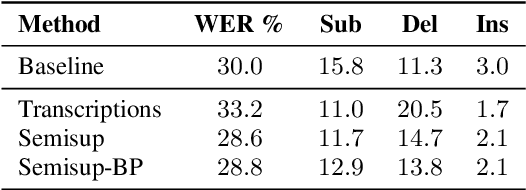
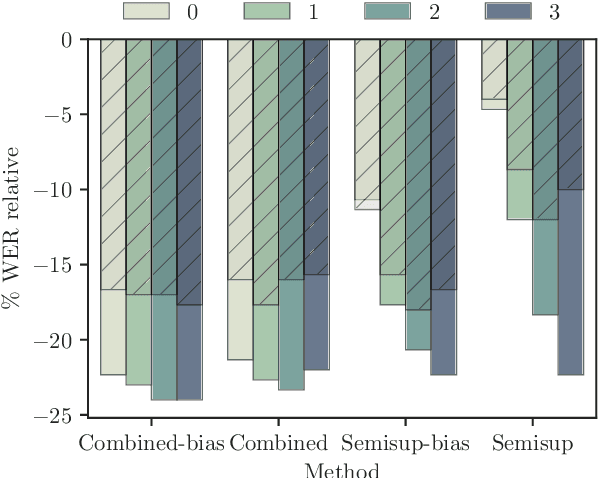
In the broadcast domain there is an abundance of related text data and partial transcriptions, such as closed captions and subtitles. This text data can be used for lightly supervised training, in which text matching the audio is selected using an existing speech recognition model. Current approaches to light supervision typically filter the data based on matching error rates between the transcriptions and biased decoding hypotheses. In contrast, semi-supervised training does not require matching text data, instead generating a hypothesis using a background language model. State-of-the-art semi-supervised training uses lattice-based supervision with the lattice-free MMI (LF-MMI) objective function. We propose a technique to combine inaccurate transcriptions with the lattices generated for semi-supervised training, thus preserving uncertainty in the lattice where appropriate. We demonstrate that this combined approach reduces the expected error rates over the lattices, and reduces the word error rate (WER) on a broadcast task.
Talking to myself: self-dialogues as data for conversational agents
Sep 19, 2018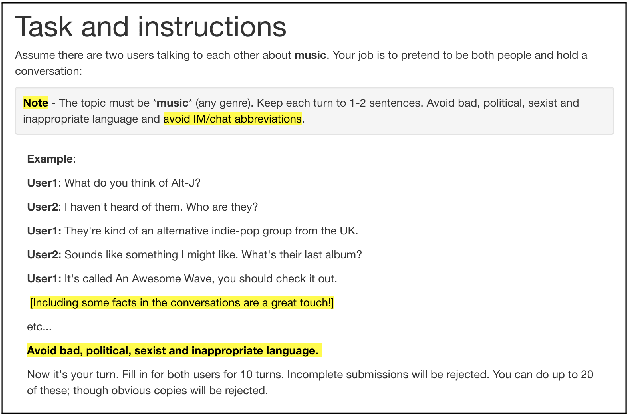
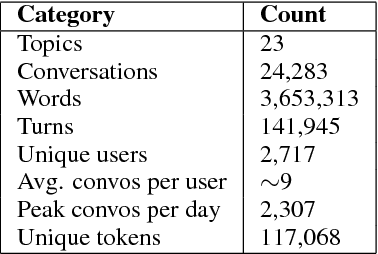
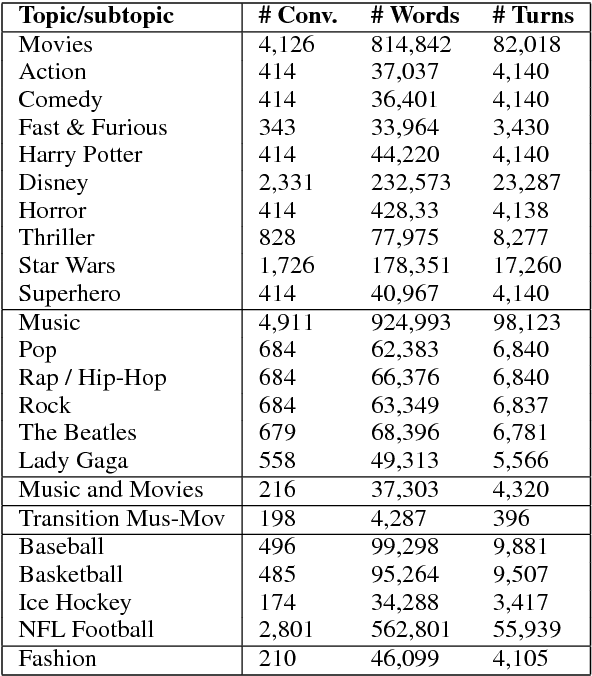
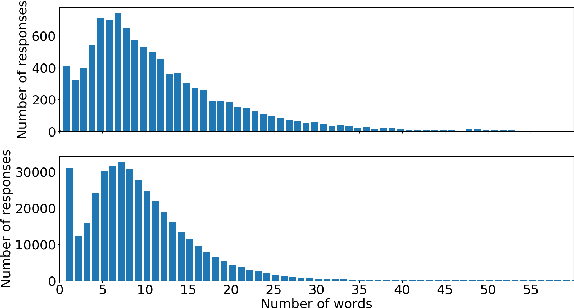
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
Learning to adapt: a meta-learning approach for speaker adaptation
Aug 30, 2018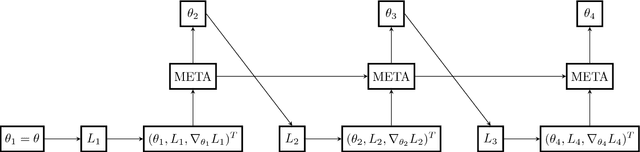
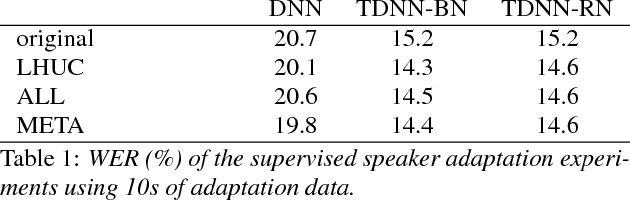
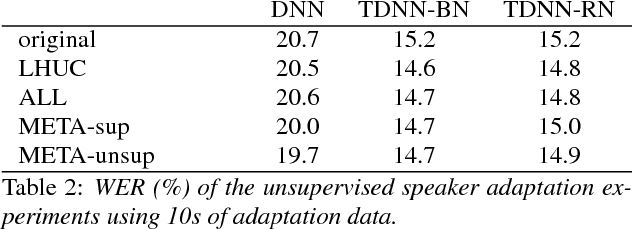
The performance of automatic speech recognition systems can be improved by adapting an acoustic model to compensate for the mismatch between training and testing conditions, for example by adapting to unseen speakers. The success of speaker adaptation methods relies on selecting weights that are suitable for adaptation and using good adaptation schedules to update these weights in order not to overfit to the adaptation data. In this paper we investigate a principled way of adapting all the weights of the acoustic model using a meta-learning. We show that the meta-learner can learn to perform supervised and unsupervised speaker adaptation and that it outperforms a strong baseline adapting LHUC parameters when adapting a DNN AM with 1.5M parameters. We also report initial experiments on adapting TDNN AMs, where the meta-learner achieves comparable performance with LHUC.
Edina: Building an Open Domain Socialbot with Self-dialogues
Sep 28, 2017
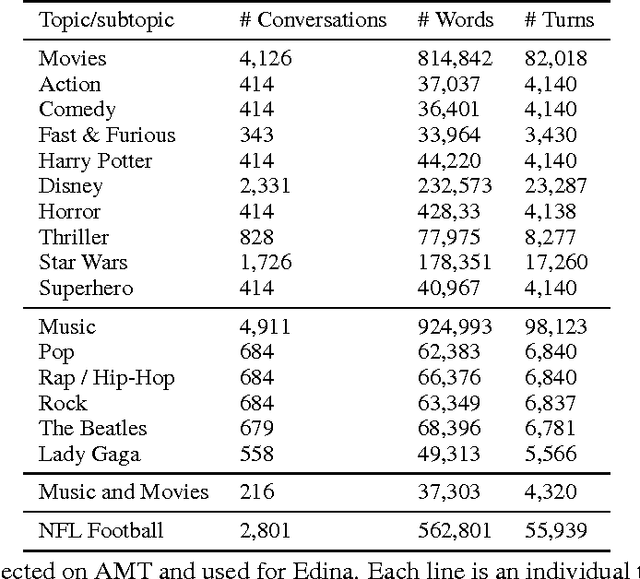
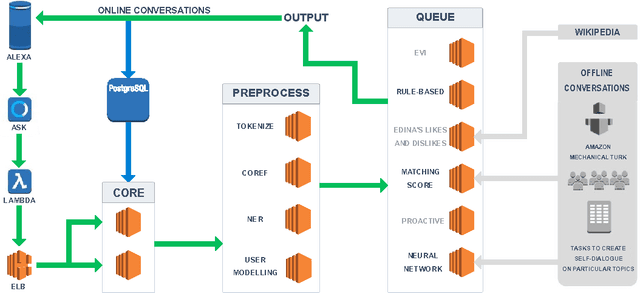

We present Edina, the University of Edinburgh's social bot for the Amazon Alexa Prize competition. Edina is a conversational agent whose responses utilize data harvested from Amazon Mechanical Turk (AMT) through an innovative new technique we call self-dialogues. These are conversations in which a single AMT Worker plays both participants in a dialogue. Such dialogues are surprisingly natural, efficient to collect and reflective of relevant and/or trending topics. These self-dialogues provide training data for a generative neural network as well as a basis for soft rules used by a matching score component. Each match of a soft rule against a user utterance is associated with a confidence score which we show is strongly indicative of reply quality, allowing this component to self-censor and be effectively integrated with other components. Edina's full architecture features a rule-based system backing off to a matching score, backing off to a generative neural network. Our hybrid data-driven methodology thus addresses both coverage limitations of a strictly rule-based approach and the lack of guarantees of a strictly machine-learning approach.