 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech LLMs are Contextual Reasoning Transcribers
Apr 01, 2026Despite extensions to speech inputs, effectively leveraging the rich knowledge and contextual understanding of large language models (LLMs) in automatic speech recognition (ASR) remains non-trivial, as the task primarily involves direct speech-to-text mapping. To address this, this paper proposes chain-of-thought ASR (CoT-ASR), which constructs a reasoning chain that enables LLMs to first analyze the input speech and generate contextual analysis, thereby fully exploiting their generative capabilities. With this contextual reasoning, CoT-ASR then performs more informed speech recognition and completes both reasoning and transcription in a single pass. Moreover, CoT-ASR naturally supports user-guided transcription: while designed to self-generate reasoning, it can also seamlessly incorporate user-provided context to guide transcription, further extending ASR functionality. To reduce the modality gap, this paper introduces a CTC-guided Modality Adapter, which uses CTC non-blank token probabilities to weight LLM embeddings, efficiently aligning speech encoder outputs with the LLM's textual latent space. Experiments show that, compared to standard LLM-based ASR, CoT-ASR achieves a relative reduction of 8.7% in word error rate (WER) and 16.9% in entity error rate (EER).
Prior Knowledge-enhanced Spatio-temporal Epidemic Forecasting
Feb 25, 2026Spatio-temporal epidemic forecasting is critical for public health management, yet existing methods often struggle with insensitivity to weak epidemic signals, over-simplified spatial relations, and unstable parameter estimation. To address these challenges, we propose the Spatio-Temporal priOr-aware Epidemic Predictor (STOEP), a novel hybrid framework that integrates implicit spatio-temporal priors and explicit expert priors. STOEP consists of three key components: (1) Case-aware Adjacency Learning (CAL), which dynamically adjusts mobility-based regional dependencies using historical infection patterns; (2) Space-informed Parameter Estimating (SPE), which employs learnable spatial priors to amplify weak epidemic signals; and (3) Filter-based Mechanistic Forecasting (FMF), which uses an expert-guided adaptive thresholding strategy to regularize epidemic parameters. Extensive experiments on real-world COVID-19 and influenza datasets demonstrate that STOEP outperforms the best baseline by 11.1% in RMSE. The system has been deployed at one provincial CDC in China to facilitate downstream applications.
The Interspeech 2026 Audio Reasoning Challenge: Evaluating Reasoning Process Quality for Audio Reasoning Models and Agents
Feb 15, 2026Recent Large Audio Language Models (LALMs) excel in understanding but often lack transparent reasoning. To address this "black-box" limitation, we organized the Audio Reasoning Challenge at Interspeech 2026, the first shared task dedicated to evaluating Chain-of-Thought (CoT) quality in the audio domain. The challenge introduced MMAR-Rubrics, a novel instance-level protocol assessing the factuality and logic of reasoning chains. Featured Single Model and Agent tracks, the competition attracting 156 teams from 18 countries and regions. Results show agent systems currently lead in reasoning quality, utilizing iterative tool orchestration and cross-modal analysis. Besides, single models are rapidly advancing via reinforcement learning and sophisticated data pipeline. We details the challenge design, methodology, and a comprehensive analysis of state-of-the-art systems, providing new insights for explainable audio intelligence.
Seeing Through the Chain: Mitigate Hallucination in Multimodal Reasoning Models via CoT Compression and Contrastive Preference Optimization
Feb 03, 2026While multimodal reasoning models (MLRMs) have exhibited impressive capabilities, they remain prone to hallucinations, and effective solutions are still underexplored. In this paper, we experimentally analyze the hallucination cause and propose C3PO, a training-based mitigation framework comprising \textbf{C}hain-of-Thought \textbf{C}ompression and \textbf{C}ontrastive \textbf{P}reference \textbf{O}ptimization. Firstly, we identify that introducing reasoning mechanisms exacerbates models' reliance on language priors while overlooking visual inputs, which can produce CoTs with reduced visual cues but redundant text tokens. To this end, we propose to selectively filter redundant thinking tokens for a more compact and signal-efficient CoT representation that preserves task-relevant information while suppressing noise. In addition, we observe that the quality of the reasoning trace largely determines whether hallucination emerges in subsequent responses. To leverage this insight, we introduce a reasoning-enhanced preference tuning scheme that constructs training pairs using high-quality AI feedback. We further design a multimodal hallucination-inducing mechanism that elicits models' inherent hallucination patterns via carefully crafted inducers, yielding informative negative signals for contrastive correction. We provide theoretical justification for the effectiveness and demonstrate consistent hallucination reduction across diverse MLRMs and benchmarks.
RLBR: Reinforcement Learning with Biasing Rewards for Contextual Speech Large Language Models
Jan 19, 2026Speech large language models (LLMs) have driven significant progress in end-to-end speech understanding and recognition, yet they continue to struggle with accurately recognizing rare words and domain-specific terminology. This paper presents a novel fine-tuning method, Reinforcement Learning with Biasing Rewards (RLBR), which employs a specialized biasing words preferred reward to explicitly emphasize biasing words in the reward calculation. In addition, we introduce reference-aware mechanisms that extend the reinforcement learning algorithm with reference transcription to strengthen the potential trajectory exploration space. Experiments on the LibriSpeech corpus across various biasing list sizes demonstrate that RLBR delivers substantial performance improvements over a strong supervised fine-tuning (SFT) baseline and consistently outperforms several recently published methods. The proposed approach achieves excellent performance on the LibriSpeech test-clean and test-other sets, reaching Biasing Word Error Rates (BWERs) of 0.59% / 2.11%, 1.09% / 3.24%, and 1.36% / 4.04% for biasing list sizes of 100, 500, and 1000, respectively, without compromising the overall WERs.
Smooth Operator: Smooth Verifiable Reward Activates Spatial Reasoning Ability of Vision-Language Model
Jan 12, 2026Vision-Language Models (VLMs) face a critical bottleneck in achieving precise numerical prediction for 3D scene understanding. Traditional reinforcement learning (RL) approaches, primarily based on relative ranking, often suffer from severe reward sparsity and gradient instability, failing to effectively exploit the verifiable signals provided by 3D physical constraints. Notably, in standard GRPO frameworks, relative normalization causes "near-miss" samples (characterized by small but non-zero errors) to suffer from advantage collapse. This leads to a severe data utilization bottleneck where valuable boundary samples are discarded during optimization. To address this, we introduce the Smooth Numerical Reward Activation (SNRA) operator and the Absolute-Preserving GRPO (AP-GRPO) framework. SNRA employs a dynamically parameterized Sigmoid function to transform raw feedback into a dense, continuous reward continuum. Concurrently, AP-GRPO integrates absolute scalar gradients to mitigate the numerical information loss inherent in conventional relative-ranking mechanisms. By leveraging this approach, we constructed Numerical3D-50k, a dataset comprising 50,000 verifiable 3D subtasks. Empirical results indicate that AP-GRPO achieves performance parity with large-scale supervised methods while maintaining higher data efficiency, effectively activating latent 3D reasoning in VLMs without requiring architectural modifications.
Towards Responsible Evaluation for Text-to-Speech
Oct 08, 2025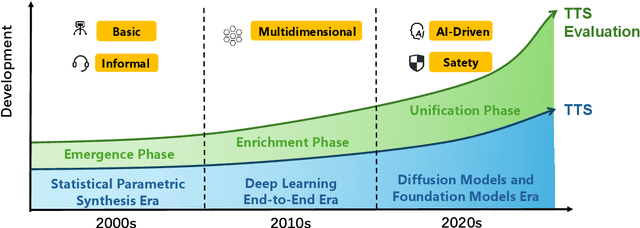


Recent advances in text-to-speech (TTS) technology have enabled systems to produce human-indistinguishable speech, bringing benefits across accessibility, content creation, and human-computer interaction. However, current evaluation practices are increasingly inadequate for capturing the full range of capabilities, limitations, and societal implications. This position paper introduces the concept of Responsible Evaluation and argues that it is essential and urgent for the next phase of TTS development, structured through three progressive levels: (1) ensuring the faithful and accurate reflection of a model's true capabilities, with more robust, discriminative, and comprehensive objective and subjective scoring methodologies; (2) enabling comparability, standardization, and transferability through standardized benchmarks, transparent reporting, and transferable evaluation metrics; and (3) assessing and mitigating ethical risks associated with forgery, misuse, privacy violations, and security vulnerabilities. Through this concept, we critically examine current evaluation practices, identify systemic shortcomings, and propose actionable recommendations. We hope this concept of Responsible Evaluation will foster more trustworthy and reliable TTS technology and guide its development toward ethically sound and societally beneficial applications.
Improving Practical Aspects of End-to-End Multi-Talker Speech Recognition for Online and Offline Scenarios
Jun 17, 2025We extend the frameworks of Serialized Output Training (SOT) to address practical needs of both streaming and offline automatic speech recognition (ASR) applications. Our approach focuses on balancing latency and accuracy, catering to real-time captioning and summarization requirements. We propose several key improvements: (1) Leveraging Continuous Speech Separation (CSS) single-channel front-end with end-to-end (E2E) systems for highly overlapping scenarios, challenging the conventional wisdom of E2E versus cascaded setups. The CSS framework improves the accuracy of the ASR system by separating overlapped speech from multiple speakers. (2) Implementing dual models -- Conformer Transducer for streaming and Sequence-to-Sequence for offline -- or alternatively, a two-pass model based on cascaded encoders. (3) Exploring segment-based SOT (segSOT) which is better suited for offline scenarios while also enhancing readability of multi-talker transcriptions.
StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
Jun 14, 2025Recent advances in zero-shot text-to-speech (TTS) synthesis have achieved high-quality speech generation for unseen speakers, but most systems remain unsuitable for real-time applications because of their offline design. Current streaming TTS paradigms often rely on multi-stage pipelines and discrete representations, leading to increased computational cost and suboptimal system performance. In this work, we propose StreamMel, a pioneering single-stage streaming TTS framework that models continuous mel-spectrograms. By interleaving text tokens with acoustic frames, StreamMel enables low-latency, autoregressive synthesis while preserving high speaker similarity and naturalness. Experiments on LibriSpeech demonstrate that StreamMel outperforms existing streaming TTS baselines in both quality and latency. It even achieves performance comparable to offline systems while supporting efficient real-time generation, showcasing broad prospects for integration with real-time speech large language models. Audio samples are available at: https://aka.ms/StreamMel.
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.