 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Jun 08, 2026Recent speech-aware large language models (Speech-LLMs) rely on a pre-trained speech encoder to convert audio into semantic-rich representations consumable by LLM. In this work, instead, we explore: can an LLM learn to read Mel spectrogram directly without a dedicated speech encoder? We propose Mel-LLM, an encoder-free Speech-LLM that feeds lightly pre-processed Mel spectrogram patches directly into the LLM through a linear projection, allowing the LLM to learn speech-text alignment purely through its own parameters. We conduct extensive experiments on both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. For ASR, we evaluate on the OpenASR leaderboard public sets and production-level scaling experiments, demonstrating that the encoder-free solution achieves competitive performance with only limited degradation compared to encoder-initialized counterparts. We find that when data is limited, initialization from a multimodal checkpoint (Phi-4-MM) is crucial for maintaining performance. We also present ablation studies revealing which LLM layers are less relevant to speech encoding. For TTS, we show preliminary results with a next-token VAE approach. While TTS performance is not yet optimal, these results establish the feasibility of a fully unified encoder-free architecture for autoregressive speech-text modeling.
Speech LLMs are Contextual Reasoning Transcribers
Apr 01, 2026Despite extensions to speech inputs, effectively leveraging the rich knowledge and contextual understanding of large language models (LLMs) in automatic speech recognition (ASR) remains non-trivial, as the task primarily involves direct speech-to-text mapping. To address this, this paper proposes chain-of-thought ASR (CoT-ASR), which constructs a reasoning chain that enables LLMs to first analyze the input speech and generate contextual analysis, thereby fully exploiting their generative capabilities. With this contextual reasoning, CoT-ASR then performs more informed speech recognition and completes both reasoning and transcription in a single pass. Moreover, CoT-ASR naturally supports user-guided transcription: while designed to self-generate reasoning, it can also seamlessly incorporate user-provided context to guide transcription, further extending ASR functionality. To reduce the modality gap, this paper introduces a CTC-guided Modality Adapter, which uses CTC non-blank token probabilities to weight LLM embeddings, efficiently aligning speech encoder outputs with the LLM's textual latent space. Experiments show that, compared to standard LLM-based ASR, CoT-ASR achieves a relative reduction of 8.7% in word error rate (WER) and 16.9% in entity error rate (EER).
RLBR: Reinforcement Learning with Biasing Rewards for Contextual Speech Large Language Models
Jan 19, 2026Speech large language models (LLMs) have driven significant progress in end-to-end speech understanding and recognition, yet they continue to struggle with accurately recognizing rare words and domain-specific terminology. This paper presents a novel fine-tuning method, Reinforcement Learning with Biasing Rewards (RLBR), which employs a specialized biasing words preferred reward to explicitly emphasize biasing words in the reward calculation. In addition, we introduce reference-aware mechanisms that extend the reinforcement learning algorithm with reference transcription to strengthen the potential trajectory exploration space. Experiments on the LibriSpeech corpus across various biasing list sizes demonstrate that RLBR delivers substantial performance improvements over a strong supervised fine-tuning (SFT) baseline and consistently outperforms several recently published methods. The proposed approach achieves excellent performance on the LibriSpeech test-clean and test-other sets, reaching Biasing Word Error Rates (BWERs) of 0.59% / 2.11%, 1.09% / 3.24%, and 1.36% / 4.04% for biasing list sizes of 100, 500, and 1000, respectively, without compromising the overall WERs.
Lightweight Prompt Biasing for Contextualized End-to-End ASR Systems
Jun 06, 2025End-to-End Automatic Speech Recognition (ASR) has advanced significantly yet still struggles with rare and domain-specific entities. This paper introduces a simple yet efficient prompt-based biasing technique for contextualized ASR, enhancing recognition accuracy by leverage a unified multitask learning framework. The approach comprises two key components: a prompt biasing model which is trained to determine when to focus on entities in prompt, and a entity filtering mechanism which efficiently filters out irrelevant entities. Our method significantly enhances ASR accuracy on entities, achieving a relative 30.7% and 18.0% reduction in Entity Word Error Rate compared to the baseline model with shallow fusion on in-house domain dataset with small and large entity lists, respectively. The primary advantage of this method lies in its efficiency and simplicity without any structure change, making it lightweight and highly efficient.
Towards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025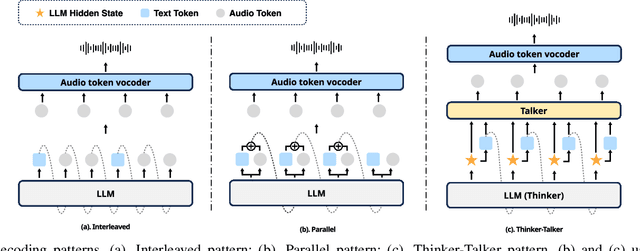
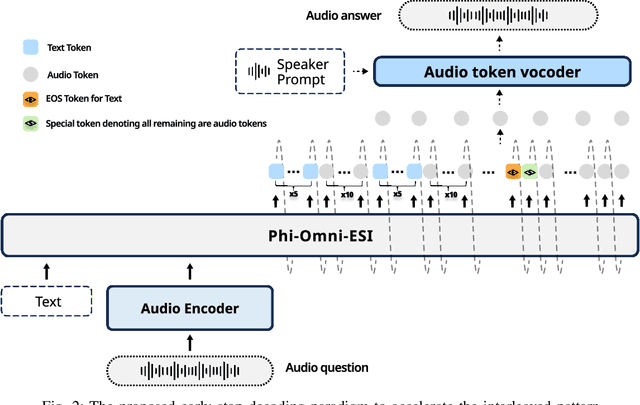


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
TransparentGS: Fast Inverse Rendering of Transparent Objects with Gaussians
May 01, 2025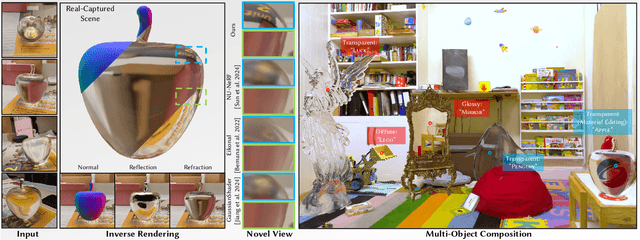
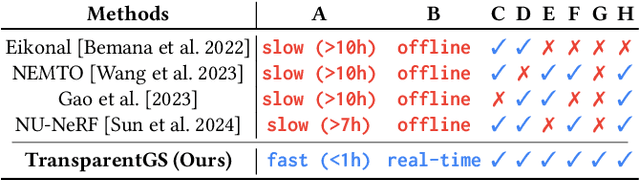
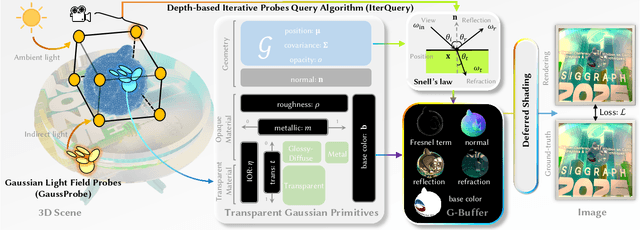

The emergence of neural and Gaussian-based radiance field methods has led to considerable advancements in novel view synthesis and 3D object reconstruction. Nonetheless, specular reflection and refraction continue to pose significant challenges due to the instability and incorrect overfitting of radiance fields to high-frequency light variations. Currently, even 3D Gaussian Splatting (3D-GS), as a powerful and efficient tool, falls short in recovering transparent objects with nearby contents due to the existence of apparent secondary ray effects. To address this issue, we propose TransparentGS, a fast inverse rendering pipeline for transparent objects based on 3D-GS. The main contributions are three-fold. Firstly, an efficient representation of transparent objects, transparent Gaussian primitives, is designed to enable specular refraction through a deferred refraction strategy. Secondly, we leverage Gaussian light field probes (GaussProbe) to encode both ambient light and nearby contents in a unified framework. Thirdly, a depth-based iterative probes query (IterQuery) algorithm is proposed to reduce the parallax errors in our probe-based framework. Experiments demonstrate the speed and accuracy of our approach in recovering transparent objects from complex environments, as well as several applications in computer graphics and vision.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
AlignFormer: Modality Matching Can Achieve Better Zero-shot Instruction-Following Speech-LLM
Dec 02, 2024Integrating speech into LLM (speech-LLM) has gaining increased attention recently. The mainstream solution is to connect a well-trained speech encoder and LLM with a neural adapter. However, the length mismatch between the speech and text sequences are not well handled, leading to imperfect modality matching between the speech and text. In this work, we propose a novel neural adapter, AlignFormer, to reduce the length gap between the two modalities. AlignFormer consists of CTC and dynamic-window QFormer layers, where the CTC alignment provides the dynamic window information for qformer layers. The LLM backbone is frozen in training to preserve its text capability, especially the instruction following capability. When training with only the ASR data, the proposed AlignFormer unlocks the instruction following capability for speech-LLM and the model can perform zero-shot speech translation (ST) and speech question answering (SQA) tasks. In fact, speech-LLM with AlignFormer can theoretically perform any tasks that the LLM backbone can deal with in the speech version. To evaluate the effectiveness of the instruction-following speech-LLM, we propose to use instruction following rate (IFR) and offer a systematic perspective for the IFR evaluation. In addition, we find that the audio position in training would affect the instruction following capability of speech-LLM and conduct an in-depth study on it. Our findings show that audio-first training achieves higher IFR than instruction-first training. The AlignFormer can achieve a near 100% IFR with audio-first training and game-changing improvements from zero to non-zero IFR on some evaluation data with instruction-first training. We believe that this study is a big step towards the perfect speech and text modality matching in the LLM embedding space.
Masked Angle-Aware Autoencoder for Remote Sensing Images
Aug 04, 2024To overcome the inherent domain gap between remote sensing (RS) images and natural images, some self-supervised representation learning methods have made promising progress. However, they have overlooked the diverse angles present in RS objects. This paper proposes the Masked Angle-Aware Autoencoder (MA3E) to perceive and learn angles during pre-training. We design a \textit{scaling center crop} operation to create the rotated crop with random orientation on each original image, introducing the explicit angle variation. MA3E inputs this composite image while reconstruct the original image, aiming to effectively learn rotation-invariant representations by restoring the angle variation introduced on the rotated crop. To avoid biases caused by directly reconstructing the rotated crop, we propose an Optimal Transport (OT) loss that automatically assigns similar original image patches to each rotated crop patch for reconstruction. MA3E demonstrates more competitive performance than existing pre-training methods on seven different RS image datasets in three downstream tasks.
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering for HDR View Synthesis
Jun 10, 2024Volumetric rendering based methods, like NeRF, excel in HDR view synthesis from RAWimages, especially for nighttime scenes. While, they suffer from long training times and cannot perform real-time rendering due to dense sampling requirements. The advent of 3D Gaussian Splatting (3DGS) enables real-time rendering and faster training. However, implementing RAW image-based view synthesis directly using 3DGS is challenging due to its inherent drawbacks: 1) in nighttime scenes, extremely low SNR leads to poor structure-from-motion (SfM) estimation in distant views; 2) the limited representation capacity of spherical harmonics (SH) function is unsuitable for RAW linear color space; and 3) inaccurate scene structure hampers downstream tasks such as refocusing. To address these issues, we propose LE3D (Lighting Every darkness with 3DGS). Our method proposes Cone Scatter Initialization to enrich the estimation of SfM, and replaces SH with a Color MLP to represent the RAW linear color space. Additionally, we introduce depth distortion and near-far regularizations to improve the accuracy of scene structure for downstream tasks. These designs enable LE3D to perform real-time novel view synthesis, HDR rendering, refocusing, and tone-mapping changes. Compared to previous volumetric rendering based methods, LE3D reduces training time to 1% and improves rendering speed by up to 4,000 times for 2K resolution images in terms of FPS. Code and viewer can be found in https://github.com/Srameo/LE3D .