 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatten The Complex: Joint B-Rep Generation via Compositional $k$-Cell Particles
Jan 25, 2026Boundary Representation (B-Rep) is the widely adopted standard in Computer-Aided Design (CAD) and manufacturing. However, generative modeling of B-Reps remains a formidable challenge due to their inherent heterogeneity as geometric cell complexes, which entangles topology with geometry across cells of varying orders (i.e., $k$-cells such as vertices, edges, faces). Previous methods typically rely on cascaded sequences to handle this hierarchy, which fails to fully exploit the geometric relationships between cells, such as adjacency and sharing, limiting context awareness and error recovery. To fill this gap, we introduce a novel paradigm that reformulates B-Reps into sets of compositional $k$-cell particles. Our approach encodes each topological entity as a composition of particles, where adjacent cells share identical latents at their interfaces, thereby promoting geometric coupling along shared boundaries. By decoupling the rigid hierarchy, our representation unifies vertices, edges, and faces, enabling the joint generation of topology and geometry with global context awareness. We synthesize these particle sets using a multi-modal flow matching framework to handle unconditional generation as well as precise conditional tasks, such as 3D reconstruction from single-view or point cloud. Furthermore, the explicit and localized nature of our representation naturally extends to downstream tasks like local in-painting and enables the direct synthesis of non-manifold structures (e.g., wireframes). Extensive experiments demonstrate that our method produces high-fidelity CAD models with superior validity and editability compared to state-of-the-art methods.
LoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025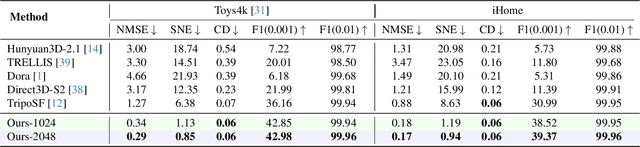
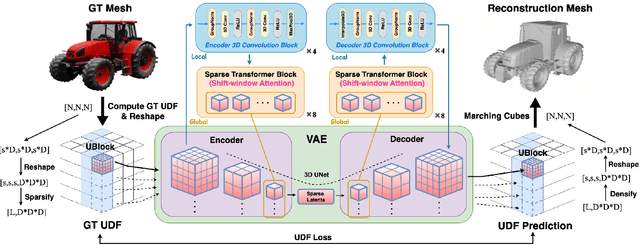
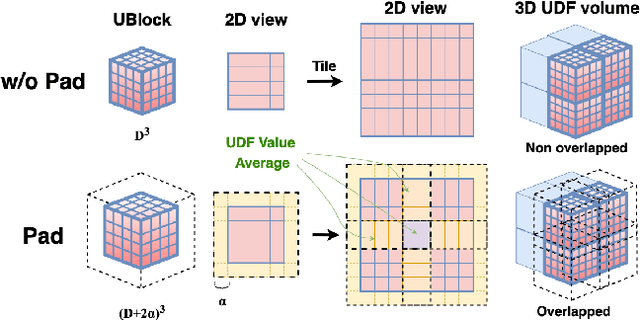
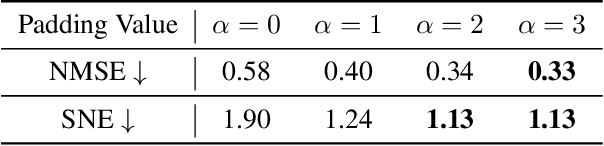
Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
GaRe: Relightable 3D Gaussian Splatting for Outdoor Scenes from Unconstrained Photo Collections
Jul 28, 2025



We propose a 3D Gaussian splatting-based framework for outdoor relighting that leverages intrinsic image decomposition to precisely integrate sunlight, sky radiance, and indirect lighting from unconstrained photo collections. Unlike prior methods that compress the per-image global illumination into a single latent vector, our approach enables simultaneously diverse shading manipulation and the generation of dynamic shadow effects. This is achieved through three key innovations: (1) a residual-based sun visibility extraction method to accurately separate direct sunlight effects, (2) a region-based supervision framework with a structural consistency loss for physically interpretable and coherent illumination decomposition, and (3) a ray-tracing-based technique for realistic shadow simulation. Extensive experiments demonstrate that our framework synthesizes novel views with competitive fidelity against state-of-the-art relighting solutions and produces more natural and multifaceted illumination and shadow effects.
Test-Time-Matching: Decouple Personality, Memory, and Linguistic Style in LLM-based Role-Playing Language Agent
Jul 23, 2025



The rapid advancement of large language models (LLMs) has enabled role-playing language agents to demonstrate significant potential in various applications. However, relying solely on prompts and contextual inputs often proves insufficient for achieving deep immersion in specific roles, particularly well-known fictional or public figures. On the other hand, fine-tuning-based approaches face limitations due to the challenges associated with data collection and the computational resources required for training, thereby restricting their broader applicability. To address these issues, we propose Test-Time-Matching (TTM), a training-free role-playing framework through test-time scaling and context engineering. TTM uses LLM agents to automatically decouple a character's features into personality, memory, and linguistic style. Our framework involves a structured, three-stage generation pipeline that utilizes these features for controlled role-playing. It achieves high-fidelity role-playing performance, also enables seamless combinations across diverse linguistic styles and even variations in personality and memory. We evaluate our framework through human assessment, and the results demonstrate that our method achieves the outstanding performance in generating expressive and stylistically consistent character dialogues.
TransparentGS: Fast Inverse Rendering of Transparent Objects with Gaussians
May 01, 2025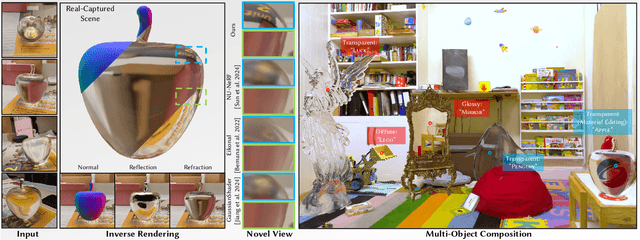
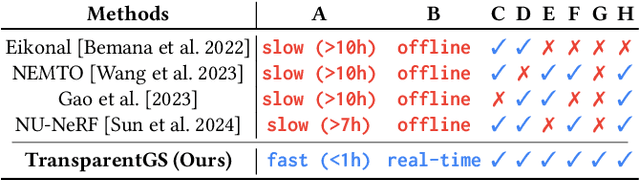
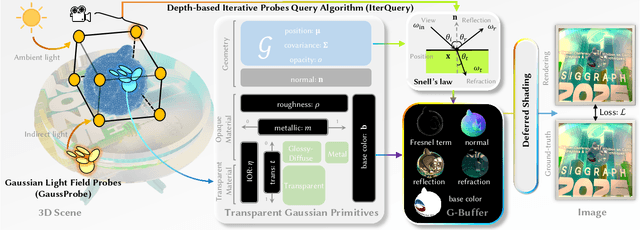

The emergence of neural and Gaussian-based radiance field methods has led to considerable advancements in novel view synthesis and 3D object reconstruction. Nonetheless, specular reflection and refraction continue to pose significant challenges due to the instability and incorrect overfitting of radiance fields to high-frequency light variations. Currently, even 3D Gaussian Splatting (3D-GS), as a powerful and efficient tool, falls short in recovering transparent objects with nearby contents due to the existence of apparent secondary ray effects. To address this issue, we propose TransparentGS, a fast inverse rendering pipeline for transparent objects based on 3D-GS. The main contributions are three-fold. Firstly, an efficient representation of transparent objects, transparent Gaussian primitives, is designed to enable specular refraction through a deferred refraction strategy. Secondly, we leverage Gaussian light field probes (GaussProbe) to encode both ambient light and nearby contents in a unified framework. Thirdly, a depth-based iterative probes query (IterQuery) algorithm is proposed to reduce the parallax errors in our probe-based framework. Experiments demonstrate the speed and accuracy of our approach in recovering transparent objects from complex environments, as well as several applications in computer graphics and vision.
Semantic Human Mesh Reconstruction with Textures
Mar 05, 2024The field of 3D detailed human mesh reconstruction has made significant progress in recent years. However, current methods still face challenges when used in industrial applications due to unstable results, low-quality meshes, and a lack of UV unwrapping and skinning weights. In this paper, we present SHERT, a novel pipeline that can reconstruct semantic human meshes with textures and high-precision details. SHERT applies semantic- and normal-based sampling between the detailed surface (eg mesh and SDF) and the corresponding SMPL-X model to obtain a partially sampled semantic mesh and then generates the complete semantic mesh by our specifically designed self-supervised completion and refinement networks. Using the complete semantic mesh as a basis, we employ a texture diffusion model to create human textures that are driven by both images and texts. Our reconstructed meshes have stable UV unwrapping, high-quality triangle meshes, and consistent semantic information. The given SMPL-X model provides semantic information and shape priors, allowing SHERT to perform well even with incorrect and incomplete inputs. The semantic information also makes it easy to substitute and animate different body parts such as the face, body, and hands. Quantitative and qualitative experiments demonstrate that SHERT is capable of producing high-fidelity and robust semantic meshes that outperform state-of-the-art methods.
360-GS: Layout-guided Panoramic Gaussian Splatting For Indoor Roaming
Feb 01, 2024



3D Gaussian Splatting (3D-GS) has recently attracted great attention with real-time and photo-realistic renderings. This technique typically takes perspective images as input and optimizes a set of 3D elliptical Gaussians by splatting them onto the image planes, resulting in 2D Gaussians. However, applying 3D-GS to panoramic inputs presents challenges in effectively modeling the projection onto the spherical surface of ${360^\circ}$ images using 2D Gaussians. In practical applications, input panoramas are often sparse, leading to unreliable initialization of 3D Gaussians and subsequent degradation of 3D-GS quality. In addition, due to the under-constrained geometry of texture-less planes (e.g., walls and floors), 3D-GS struggles to model these flat regions with elliptical Gaussians, resulting in significant floaters in novel views. To address these issues, we propose 360-GS, a novel $360^{\circ}$ Gaussian splatting for a limited set of panoramic inputs. Instead of splatting 3D Gaussians directly onto the spherical surface, 360-GS projects them onto the tangent plane of the unit sphere and then maps them to the spherical projections. This adaptation enables the representation of the projection using Gaussians. We guide the optimization of 360-GS by exploiting layout priors within panoramas, which are simple to obtain and contain strong structural information about the indoor scene. Our experimental results demonstrate that 360-GS allows panoramic rendering and outperforms state-of-the-art methods with fewer artifacts in novel view synthesis, thus providing immersive roaming in indoor scenarios.
Deep Point Cloud Simplification for High-quality Surface Reconstruction
Mar 17, 2022
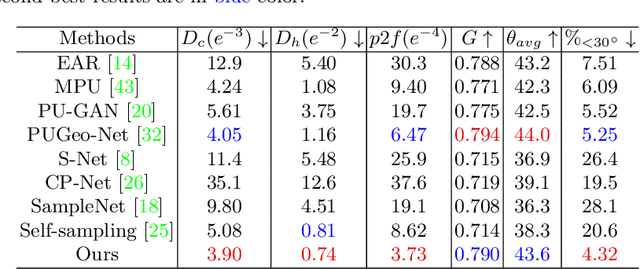


The growing size of point clouds enlarges consumptions of storage, transmission, and computation of 3D scenes. Raw data is redundant, noisy, and non-uniform. Therefore, simplifying point clouds for achieving compact, clean, and uniform points is becoming increasingly important for 3D vision and graphics tasks. Previous learning based methods aim to generate fewer points for scene understanding, regardless of the quality of surface reconstruction, leading to results with low reconstruction accuracy and bad point distribution. In this paper, we propose a novel point cloud simplification network (PCS-Net) dedicated to high-quality surface mesh reconstruction while maintaining geometric fidelity. We first learn a sampling matrix in a feature-aware simplification module to reduce the number of points. Then we propose a novel double-scale resampling module to refine the positions of the sampled points, to achieve a uniform distribution. To further retain important shape features, an adaptive sampling strategy with a novel saliency loss is designed. With our PCS-Net, the input non-uniform and noisy point cloud can be simplified in a feature-aware manner, i.e., points near salient features are consolidated but still with uniform distribution locally. Experiments demonstrate the effectiveness of our method and show that we outperform previous simplification or reconstruction-oriented upsampling methods.
DoubleEnsemble: A New Ensemble Method Based on Sample Reweighting and Feature Selection for Financial Data Analysis
Oct 03, 2020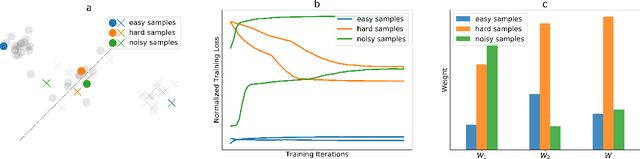
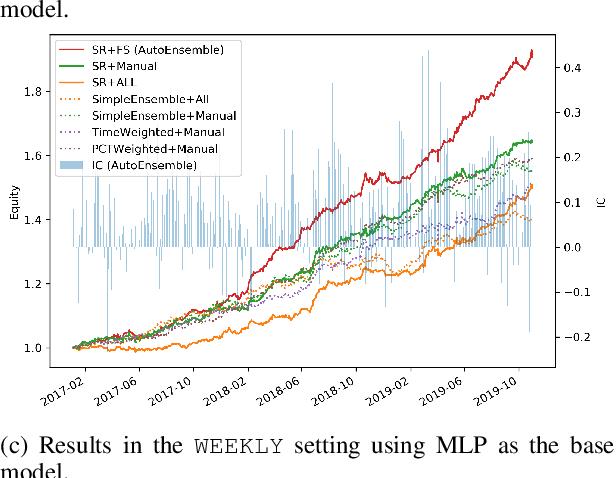
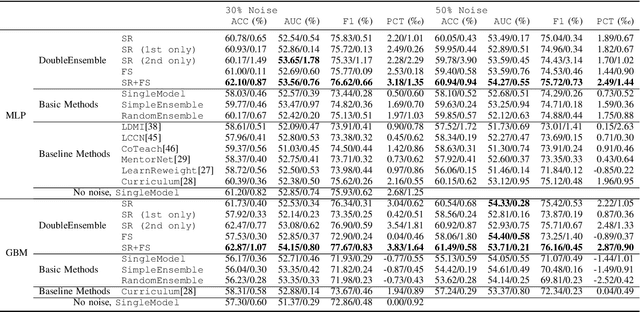
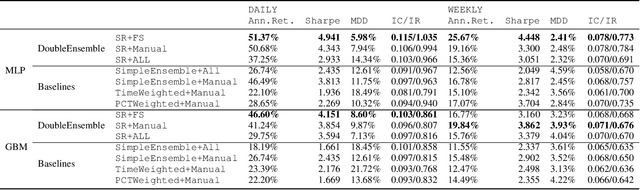
Modern machine learning models (such as deep neural networks and boosting decision tree models) have become increasingly popular in financial market prediction, due to their superior capacity to extract complex non-linear patterns. However, since financial datasets have very low signal-to-noise ratio and are non-stationary, complex models are often very prone to overfitting and suffer from instability issues. Moreover, as various machine learning and data mining tools become more widely used in quantitative trading, many trading firms have been producing an increasing number of features (aka factors). Therefore, how to automatically select effective features becomes an imminent problem. To address these issues, we propose DoubleEnsemble, an ensemble framework leveraging learning trajectory based sample reweighting and shuffling based feature selection. Specifically, we identify the key samples based on the training dynamics on each sample and elicit key features based on the ablation impact of each feature via shuffling. Our model is applicable to a wide range of base models, capable of extracting complex patterns, while mitigating the overfitting and instability issues for financial market prediction. We conduct extensive experiments, including price prediction for cryptocurrencies and stock trading, using both DNN and gradient boosting decision tree as base models. Our experiment results demonstrate that DoubleEnsemble achieves a superior performance compared with several baseline methods.
Policy Search by Target Distribution Learning for Continuous Control
May 27, 2019
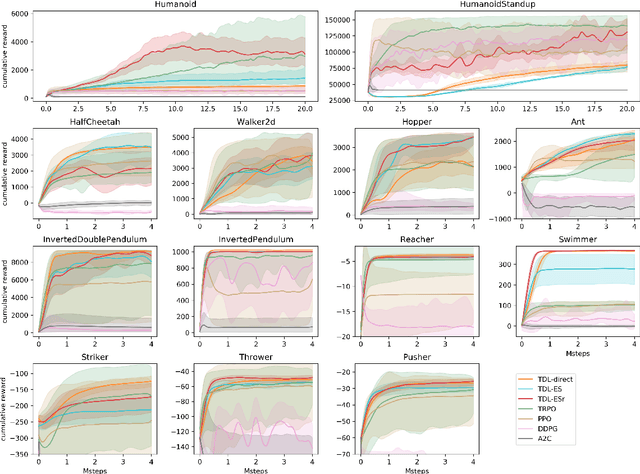
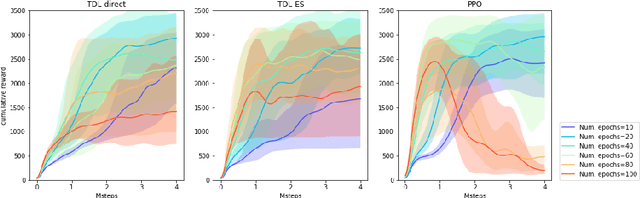
We observe that several existing policy gradient methods (such as vanilla policy gradient, PPO, A2C) may suffer from overly large gradients when the current policy is close to deterministic (even in some very simple environments), leading to an unstable training process. To address this issue, we propose a new method, called \emph{target distribution learning} (TDL), for policy improvement in reinforcement learning. TDL alternates between proposing a target distribution and training the policy network to approach the target distribution. TDL is more effective in constraining the KL divergence between updated policies, and hence leads to more stable policy improvements over iterations. Our experiments show that TDL algorithms perform comparably to (or better than) state-of-the-art algorithms for most continuous control tasks in the MuJoCo environment while being more stable in training.