 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDFuse: Multimodal EHR Data Fusion with Masked Lab-Test Modeling and Large Language Models
Jul 17, 2024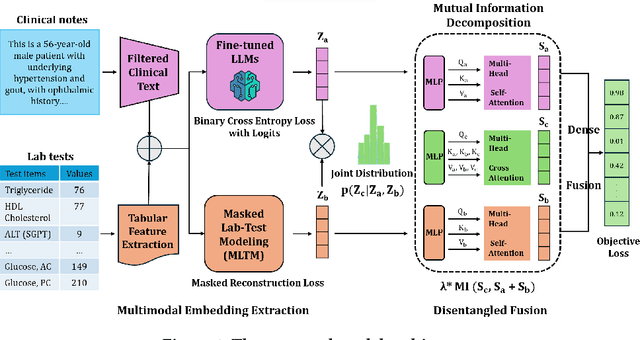
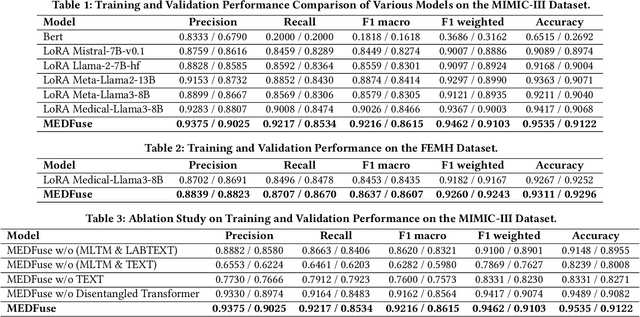
Electronic health records (EHRs) are multimodal by nature, consisting of structured tabular features like lab tests and unstructured clinical notes. In real-life clinical practice, doctors use complementary multimodal EHR data sources to get a clearer picture of patients' health and support clinical decision-making. However, most EHR predictive models do not reflect these procedures, as they either focus on a single modality or overlook the inter-modality interactions/redundancy. In this work, we propose MEDFuse, a Multimodal EHR Data Fusion framework that incorporates masked lab-test modeling and large language models (LLMs) to effectively integrate structured and unstructured medical data. MEDFuse leverages multimodal embeddings extracted from two sources: LLMs fine-tuned on free clinical text and masked tabular transformers trained on structured lab test results. We design a disentangled transformer module, optimized by a mutual information loss to 1) decouple modality-specific and modality-shared information and 2) extract useful joint representation from the noise and redundancy present in clinical notes. Through comprehensive validation on the public MIMIC-III dataset and the in-house FEMH dataset, MEDFuse demonstrates great potential in advancing clinical predictions, achieving over 90% F1 score in the 10-disease multi-label classification task.
Model-Agnostic Interpretation Framework in Machine Learning: A Comparative Study in NBA Sports
Jan 05, 2024The field of machine learning has seen tremendous progress in recent years, with deep learning models delivering exceptional performance across a range of tasks. However, these models often come at the cost of interpretability, as they operate as opaque "black boxes" that obscure the rationale behind their decisions. This lack of transparency can limit understanding of the models' underlying principles and impede their deployment in sensitive domains, such as healthcare or finance. To address this challenge, our research team has proposed an innovative framework designed to reconcile the trade-off between model performance and interpretability. Our approach is centered around modular operations on high-dimensional data, which enable end-to-end processing while preserving interpretability. By fusing diverse interpretability techniques and modularized data processing, our framework sheds light on the decision-making processes of complex models without compromising their performance. We have extensively tested our framework and validated its superior efficacy in achieving a harmonious balance between computational efficiency and interpretability. Our approach addresses a critical need in contemporary machine learning applications by providing unprecedented insights into the inner workings of complex models, fostering trust, transparency, and accountability in their deployment across diverse domains.
Financial Time-Series Forecasting: Towards Synergizing Performance And Interpretability Within a Hybrid Machine Learning Approach
Dec 31, 2023In the realm of cryptocurrency, the prediction of Bitcoin prices has garnered substantial attention due to its potential impact on financial markets and investment strategies. This paper propose a comparative study on hybrid machine learning algorithms and leverage on enhancing model interpretability. Specifically, linear regression(OLS, LASSO), long-short term memory(LSTM), decision tree regressors are introduced. Through the grounded experiments, we observe linear regressor achieves the best performance among candidate models. For the interpretability, we carry out a systematic overview on the preprocessing techniques of time-series statistics, including decomposition, auto-correlational function, exponential triple forecasting, which aim to excavate latent relations and complex patterns appeared in the financial time-series forecasting. We believe this work may derive more attention and inspire more researches in the realm of time-series analysis and its realistic applications.
ADA-YOLO: Dynamic Fusion of YOLOv8 and Adaptive Heads for Precise Image Detection and Diagnosis
Dec 14, 2023Object detection and localization are crucial tasks for biomedical image analysis, particularly in the field of hematology where the detection and recognition of blood cells are essential for diagnosis and treatment decisions. While attention-based methods have shown significant progress in object detection in various domains, their application in medical object detection has been limited due to the unique challenges posed by medical imaging datasets. To address this issue, we propose ADA-YOLO, a light-weight yet effective method for medical object detection that integrates attention-based mechanisms with the YOLOv8 architecture. Our proposed method leverages the dynamic feature localisation and parallel regression for computer vision tasks through \textit{adaptive head} module. Empirical experiments were conducted on the Blood Cell Count and Detection (BCCD) dataset to evaluate the effectiveness of ADA-YOLO. The results showed that ADA-YOLO outperforms the YOLOv8 model in mAP (mean average precision) on the BCCD dataset by using more than 3 times less space than YOLOv8. This indicates that our proposed method is effective. Moreover, the light-weight nature of our proposed method makes it suitable for deployment in resource-constrained environments such as mobile devices or edge computing systems. which could ultimately lead to improved diagnosis and treatment outcomes in the field of hematology.
Decision-making of Emergent Incident based on P-MADDPG
Mar 19, 2022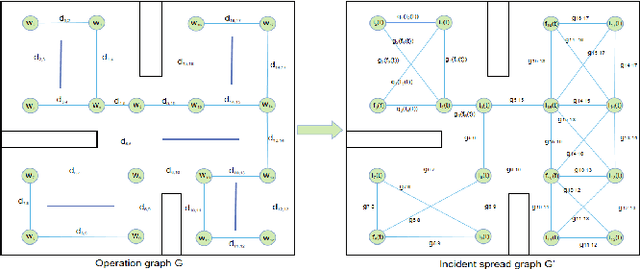
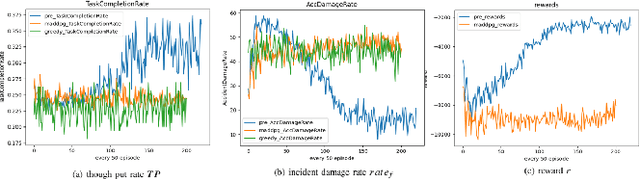
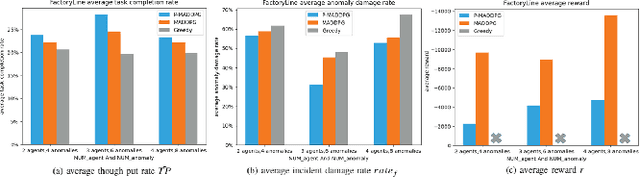

In recent years, human casualties and damage to resources caused by emergent incidents have become a serious problem worldwide. In this paper, we model the emergency decision-making problem and use Multi-agent System (MAS) to solve the problem that the decision speed cannot keep up with the spreading speed. MAS can play an important role in the automated execution of these tasks to reduce mission completion time. In this paper, we propose a P-MADDPG algorithm to solve the emergency decision-making problem of emergent incidents, which predicts the nodes where an incident may occur in the next time by GRU model and makes decisions before the incident occurs, thus solving the problem that the decision speed cannot keep up with the spreading speed. A simulation environment was established for realistic scenarios, and three scenarios were selected to test the performance of P-MADDPG in emergency decision-making problems for emergent incidents: unmanned storage, factory assembly line, and civil airport baggage transportation. Simulation results using the P-MADDPG algorithm are compared with the greedy algorithm and the MADDPG algorithm, and the final experimental results show that the P-MADDPG algorithm converges faster and better than the other algorithms in scenarios of different sizes. This shows that the P-MADDP algorithm is effective for emergency decision-making in emergent incident.
Deep Point Cloud Simplification for High-quality Surface Reconstruction
Mar 17, 2022
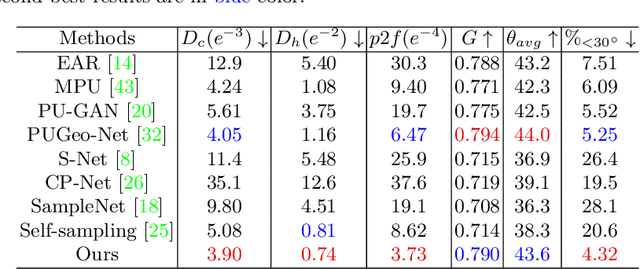


The growing size of point clouds enlarges consumptions of storage, transmission, and computation of 3D scenes. Raw data is redundant, noisy, and non-uniform. Therefore, simplifying point clouds for achieving compact, clean, and uniform points is becoming increasingly important for 3D vision and graphics tasks. Previous learning based methods aim to generate fewer points for scene understanding, regardless of the quality of surface reconstruction, leading to results with low reconstruction accuracy and bad point distribution. In this paper, we propose a novel point cloud simplification network (PCS-Net) dedicated to high-quality surface mesh reconstruction while maintaining geometric fidelity. We first learn a sampling matrix in a feature-aware simplification module to reduce the number of points. Then we propose a novel double-scale resampling module to refine the positions of the sampled points, to achieve a uniform distribution. To further retain important shape features, an adaptive sampling strategy with a novel saliency loss is designed. With our PCS-Net, the input non-uniform and noisy point cloud can be simplified in a feature-aware manner, i.e., points near salient features are consolidated but still with uniform distribution locally. Experiments demonstrate the effectiveness of our method and show that we outperform previous simplification or reconstruction-oriented upsampling methods.