 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap between Text, Audio, Image, and Any Sequence: A Novel Approach using Gloss-based Annotation
Oct 04, 2024



This paper presents an innovative approach called BGTAI to simplify multimodal understanding by utilizing gloss-based annotation as an intermediate step in aligning Text and Audio with Images. While the dynamic temporal factors in textual and audio inputs contain various predicate adjectives that influence the meaning of the entire sentence, images, on the other hand, present static scenes. By representing text and audio as gloss notations that omit complex semantic nuances, a better alignment with images can potentially be achieved. This study explores the feasibility of this idea, specifically, we first propose the first Langue2Gloss model and then integrate it into the multimodal model UniBriVL for joint training. To strengthen the adaptability of gloss with text/audio and overcome the efficiency and instability issues in multimodal training, we propose a DS-Net (Data-Pair Selection Network), an Result Filter module, and a novel SP-Loss function. Our approach outperforms previous multimodal models in the main experiments, demonstrating its efficacy in enhancing multimodal representations and improving compatibility among text, audio, visual, and any sequence modalities.
ADA-YOLO: Dynamic Fusion of YOLOv8 and Adaptive Heads for Precise Image Detection and Diagnosis
Dec 14, 2023Object detection and localization are crucial tasks for biomedical image analysis, particularly in the field of hematology where the detection and recognition of blood cells are essential for diagnosis and treatment decisions. While attention-based methods have shown significant progress in object detection in various domains, their application in medical object detection has been limited due to the unique challenges posed by medical imaging datasets. To address this issue, we propose ADA-YOLO, a light-weight yet effective method for medical object detection that integrates attention-based mechanisms with the YOLOv8 architecture. Our proposed method leverages the dynamic feature localisation and parallel regression for computer vision tasks through \textit{adaptive head} module. Empirical experiments were conducted on the Blood Cell Count and Detection (BCCD) dataset to evaluate the effectiveness of ADA-YOLO. The results showed that ADA-YOLO outperforms the YOLOv8 model in mAP (mean average precision) on the BCCD dataset by using more than 3 times less space than YOLOv8. This indicates that our proposed method is effective. Moreover, the light-weight nature of our proposed method makes it suitable for deployment in resource-constrained environments such as mobile devices or edge computing systems. which could ultimately lead to improved diagnosis and treatment outcomes in the field of hematology.
UniBriVL: Robust Universal Representation and Generation of Audio Driven Diffusion Models
Jul 29, 2023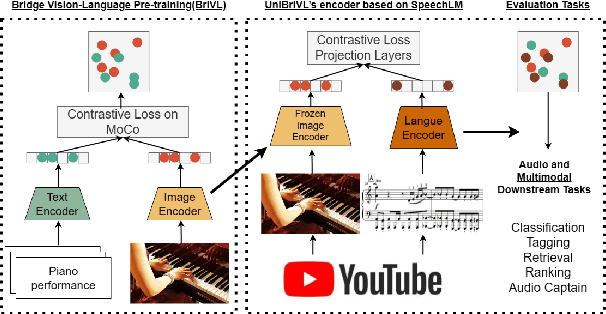



Multimodal large models have been recognized for their advantages in various performance and downstream tasks. The development of these models is crucial towards achieving general artificial intelligence in the future. In this paper, we propose a novel universal language representation learning method called UniBriVL, which is based on Bridging-Vision-and-Language (BriVL). Universal BriVL embeds audio, image, and text into a shared space, enabling the realization of various multimodal applications. Our approach addresses major challenges in robust language (both text and audio) representation learning and effectively captures the correlation between audio and image. Additionally, we demonstrate the qualitative evaluation of the generated images from UniBriVL, which serves to highlight the potential of our approach in creating images from audio. Overall, our experimental results demonstrate the efficacy of UniBriVL in downstream tasks and its ability to choose appropriate images from audio. The proposed approach has the potential for various applications such as speech recognition, music signal processing, and captioning systems.
New Audio Representations Image Gan Generation from BriVL
Mar 08, 2023Recently, researchers have gradually realized that in some cases, the self-supervised pre-training on large-scale Internet data is better than that of high-quality/manually labeled data sets, and multimodal/large models are better than single or bimodal/small models. In this paper, we propose a robust audio representation learning method WavBriVL based on Bridging-Vision-and-Language (BriVL). WavBriVL projects audio, image and text into a shared embedded space, so that multi-modal applications can be realized. We demonstrate the qualitative evaluation of the image generated from WavBriVL as a shared embedded space, with the main purposes of this paper: (1) Learning the correlation between audio and image; (2) Explore a new way of image generation, that is, use audio to generate pictures. Experimental results show that this method can effectively generate appropriate images from audio.