 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignVerse-2M: A Two-Million-Clip Pose-Native Universe of 55+ Sign Languages
May 06, 2026Existing large-scale sign language resources typically provide supervision only at the level of raw video-text alignment and are often produced in laboratory settings. While such resources are important for semantic understanding, they do not directly provide a unified interface for open-world recognition and translation, or for modern pose-driven sign language video generation frameworks: 1. RGB-based pretrained recognition models depend heavily on fixed backgrounds or clothing conditions during recording, and are less robust in open-world settings than style-agnostic pose-processing models. 2. Recent pose-guided image/video generation models mostly use a unified keypoint representation such as DWPose as their control interface. At present, the sign language field still lacks a data resource that can directly interface with this modern pose-native paradigm while also targeting real-world open scenarios. We present SignVerse-2M, a large-scale multilingual pose-native dataset for sign language pose modeling and evaluation. Built from publicly available multilingual sign language video resources, it applies DWPose in a unified preprocessing pipeline to convert raw videos into 2D pose sequences that can be used directly for modeling, resulting in a consolidated corpus of about two million clips covering more than 55 sign languages. Unlike many laboratory datasets, this resource preserves the recording conditions and speaker diversity of real-world videos while reducing appearance variation through a unified pose representation. Toward this goal, we further provide the data construction pipeline, task definitions, and a simple SignDW Transformer baseline, demonstrating the feasibility of this resource for multilingual pose-space modeling and its compatibility with modern pose-driven pipelines, while discussing the evaluation claims it can support as well as its current limitations.
AEGIS: From Clues to Verdicts -- Graph-Guided Deep Vulnerability Reasoning via Dialectics and Meta-Auditing
Mar 21, 2026Large Language Models (LLMs) are increasingly adopted for vulnerability detection, yet their reasoning remains fundamentally unsound. We identify a root cause shared by both major mitigation paradigms (agent-based debate and retrieval augmentation): reasoning in an ungrounded deliberative space that lacks a bounded, hypothesis-specific evidence base. Without such grounding, agents fabricate cross-function dependencies, and retrieval heuristics supply generic knowledge decoupled from the repository's data-flow topology. Consequently, the resulting conclusions are driven by rhetorical persuasiveness rather than verifiable facts. To ground this deliberation, we present AEGIS, a novel multi-agent framework that shifts detection from ungrounded speculation to forensic verification over a closed factual substrate. Guided by a "From Clue to Verdict" philosophy, AEGIS first identifies suspicious code anomalies (clues), then dynamically reconstructs per-variable dependency chains for each clue via on-demand slicing over a repository-level Code Property Graph. Within this closed evidence boundary, a Verifier Agent constructs competing dialectical arguments for and against exploitability, while an independent Audit Agent scrutinizes every claim against the trace, exercising veto power to prevent hallucinated verdicts. Evaluation on the rigorous PrimeVul dataset demonstrates that AEGIS establishes a new state-of-the-art, achieving 122 Pair-wise Correct Predictions. To our knowledge, this is the first approach to surpass 100 on this benchmark. It reduces the false positive rate by up to 54.40% compared to leading baselines, at an average cost of $0.09 per sample without any task-specific training.
Understanding Privacy Risks in Code Models Through Training Dynamics: A Causal Approach
Dec 09, 2025Large language models for code (LLM4Code) have greatly improved developer productivity but also raise privacy concerns due to their reliance on open-source repositories containing abundant personally identifiable information (PII). Prior work shows that commercial models can reproduce sensitive PII, yet existing studies largely treat PII as a single category and overlook the heterogeneous risks among different types. We investigate whether distinct PII types vary in their likelihood of being learned and leaked by LLM4Code, and whether this relationship is causal. Our methodology includes building a dataset with diverse PII types, fine-tuning representative models of different scales, computing training dynamics on real PII data, and formulating a structural causal model to estimate the causal effect of learnability on leakage. Results show that leakage risks differ substantially across PII types and correlate with their training dynamics: easy-to-learn instances such as IP addresses exhibit higher leakage, while harder types such as keys and passwords leak less frequently. Ambiguous types show mixed behaviors. This work provides the first causal evidence that leakage risks are type-dependent and offers guidance for developing type-aware and learnability-aware defenses for LLM4Code.
EVALOOP: Assessing LLM Robustness in Programming from a Self-consistency Perspective
May 18, 2025



Assessing the programming capabilities of Large Language Models (LLMs) is crucial for their effective use in software engineering. Current evaluations, however, predominantly measure the accuracy of generated code on static benchmarks, neglecting the critical aspect of model robustness during programming tasks. While adversarial attacks offer insights on model robustness, their effectiveness is limited and evaluation could be constrained. Current adversarial attack methods for robustness evaluation yield inconsistent results, struggling to provide a unified evaluation across different LLMs. We introduce EVALOOP, a novel assessment framework that evaluate the robustness from a self-consistency perspective, i.e., leveraging the natural duality inherent in popular software engineering tasks, e.g., code generation and code summarization. EVALOOP initiates a self-contained feedback loop: an LLM generates output (e.g., code) from an input (e.g., natural language specification), and then use the generated output as the input to produce a new output (e.g., summarizes that code into a new specification). EVALOOP repeats the process to assess the effectiveness of EVALOOP in each loop. This cyclical strategy intrinsically evaluates robustness without rely on any external attack setups, providing a unified metric to evaluate LLMs' robustness in programming. We evaluate 16 prominent LLMs (e.g., GPT-4.1, O4-mini) on EVALOOP and found that EVALOOP typically induces a 5.01%-19.31% absolute drop in pass@1 performance within ten loops. Intriguingly, robustness does not always align with initial performance (i.e., one-time query); for instance, GPT-3.5-Turbo, despite superior initial code generation compared to DeepSeek-V2, demonstrated lower robustness over repeated evaluation loop.
SignX: The Foundation Model for Sign Recognition
Apr 22, 2025The complexity of sign language data processing brings many challenges. The current approach to recognition of ASL signs aims to translate RGB sign language videos through pose information into English-based ID glosses, which serve to uniquely identify ASL signs. Note that there is no shared convention for assigning such glosses to ASL signs, so it is essential that the same glossing conventions are used for all of the data in the datasets that are employed. This paper proposes SignX, a foundation model framework for sign recognition. It is a concise yet powerful framework applicable to multiple human activity recognition scenarios. First, we developed a Pose2Gloss component based on an inverse diffusion model, which contains a multi-track pose fusion layer that unifies five of the most powerful pose information sources--SMPLer-X, DWPose, Mediapipe, PrimeDepth, and Sapiens Segmentation--into a single latent pose representation. Second, we trained a Video2Pose module based on ViT that can directly convert raw video into signer pose representation. Through this 2-stage training framework, we enable sign language recognition models to be compatible with existing pose formats, laying the foundation for the common pose estimation necessary for sign recognition. Experimental results show that SignX can recognize signs from sign language video, producing predicted gloss representations with greater accuracy than has been reported in prior work.
Bridging the Gap between Text, Audio, Image, and Any Sequence: A Novel Approach using Gloss-based Annotation
Oct 04, 2024



This paper presents an innovative approach called BGTAI to simplify multimodal understanding by utilizing gloss-based annotation as an intermediate step in aligning Text and Audio with Images. While the dynamic temporal factors in textual and audio inputs contain various predicate adjectives that influence the meaning of the entire sentence, images, on the other hand, present static scenes. By representing text and audio as gloss notations that omit complex semantic nuances, a better alignment with images can potentially be achieved. This study explores the feasibility of this idea, specifically, we first propose the first Langue2Gloss model and then integrate it into the multimodal model UniBriVL for joint training. To strengthen the adaptability of gloss with text/audio and overcome the efficiency and instability issues in multimodal training, we propose a DS-Net (Data-Pair Selection Network), an Result Filter module, and a novel SP-Loss function. Our approach outperforms previous multimodal models in the main experiments, demonstrating its efficacy in enhancing multimodal representations and improving compatibility among text, audio, visual, and any sequence modalities.
SignLLM: Sign Languages Production Large Language Models
May 17, 2024

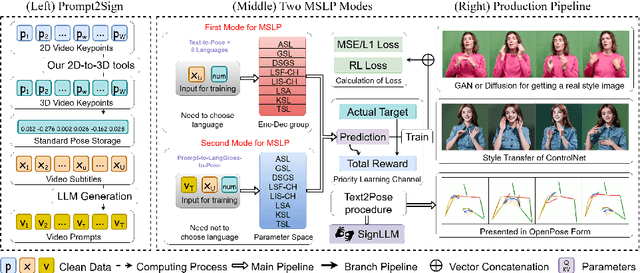

In this paper, we introduce the first comprehensive multilingual sign language dataset named Prompt2Sign, which builds from public data including American Sign Language (ASL) and seven others. Our dataset transforms a vast array of videos into a streamlined, model-friendly format, optimized for training with translation models like seq2seq and text2text. Building on this new dataset, we propose SignLLM, the first multilingual Sign Language Production (SLP) model, which includes two novel multilingual SLP modes that allow for the generation of sign language gestures from input text or prompt. Both of the modes can use a new loss and a module based on reinforcement learning, which accelerates the training by enhancing the model's capability to autonomously sample high-quality data. We present benchmark results of SignLLM, which demonstrate that our model achieves state-of-the-art performance on SLP tasks across eight sign languages.
Generative AI to Generate Test Data Generators
Jan 31, 2024Generating fake data is an essential dimension of modern software testing, as demonstrated by the number and significance of data faking libraries. Yet, developers of faking libraries cannot keep up with the wide range of data to be generated for different natural languages and domains. In this paper, we assess the ability of generative AI for generating test data in different domains. We design three types of prompts for Large Language Models (LLMs), which perform test data generation tasks at different levels of integrability: 1) raw test data generation, 2) synthesizing programs in a specific language that generate useful test data, and 3) producing programs that use state-of-the-art faker libraries. We evaluate our approach by prompting LLMs to generate test data for 11 domains. The results show that LLMs can successfully generate realistic test data generators in a wide range of domains at all three levels of integrability.
RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair
Dec 25, 2023



Automated Program Repair (APR) has evolved significantly with the advent of Large Language Models (LLMs). Fine-tuning LLMs for program repair is a recent avenue of research, with many dimensions which have not been explored. Existing work mostly fine-tunes LLMs with naive code representations and is fundamentally limited in its ability to fine-tune larger LLMs. To address this problem, we propose RepairLLaMA, a novel program repair approach that combines 1) code representations for APR and 2) the state-of-the-art parameter-efficient LLM fine-tuning technique called LoRA. This results in RepairLLaMA producing a highly effective `program repair adapter' for fixing bugs with language models. Our experiments demonstrate the validity of both concepts. First, fine-tuning adapters with program repair specific code representations enables the model to use meaningful repair signals. Second, parameter-efficient fine-tuning helps fine-tuning to converge and contributes to the effectiveness of the repair adapter to fix data-points outside the fine-tuning data distribution. Overall, RepairLLaMA correctly fixes 125 Defects4J v2 and 82 HumanEval-Java bugs, outperforming all baselines.
Supersonic: Learning to Generate Source Code Optimizations in C/C++
Oct 02, 2023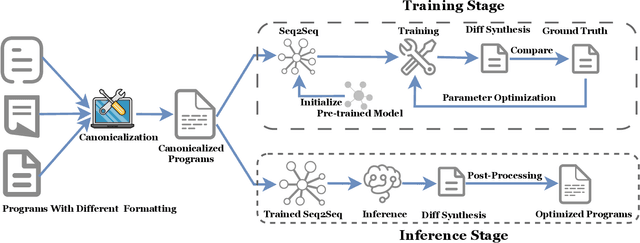


Software optimization refines programs for resource efficiency while preserving functionality. Traditionally, it is a process done by developers and compilers. This paper introduces a third option, automated optimization at the source code level. We present Supersonic, a neural approach targeting minor source code modifications for optimization. Using a seq2seq model, Supersonic is trained on C/C++ program pairs ($x_{t}$, $x_{t+1}$), where $x_{t+1}$ is an optimized version of $x_{t}$, and outputs a diff. Supersonic's performance is benchmarked against OpenAI's GPT-3.5-Turbo and GPT-4 on competitive programming tasks. The experiments show that Supersonic not only outperforms both models on the code optimization task but also minimizes the extent of the change with a model more than 600x smaller than GPT-3.5-Turbo and 3700x smaller than GPT-4.