 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Randomness in Agentic Evals
Feb 06, 2026Agentic systems are evaluated on benchmarks where agents interact with environments to solve tasks. Most papers report a pass@1 score computed from a single run per task, assuming this gives a reliable performance estimate. We test this assumption by collecting 60,000 agentic trajectories on SWE-Bench-Verified, spanning three models and two scaffolds. We find substantial variance: single-run pass@1 estimates vary by 2.2 to 6.0 percentage points depending on which run is selected, with standard deviations exceeding 1.5 percentage points even at temperature 0. This variance has critical implications: reported improvements of 2--3 percentage points may reflect evaluation noise rather than genuine algorithmic progress. Through token-level analysis, we show that trajectories diverge early, often within the first few percent of tokens, and that these small differences cascade into different solution strategies. To enable reliable evaluation of agentic systems, we recommend three concrete practices: (1) estimate pass@1 from multiple independent runs per task, especially when measuring small improvements, (2) use statistical power analysis to determine the number of runs needed to detect expected effect sizes, and (3) consider metrics like pass@k (optimistic bound) and pass^k (pessimistic bound) with k>1 to better characterize the full performance envelope. While these practices increase evaluation cost, they are essential for distinguishing genuine scientific progress from statistical noise.
Gradient-Based Program Repair: Fixing Bugs in Continuous Program Spaces
May 23, 2025Automatic program repair seeks to generate correct code from buggy programs, with most approaches searching the correct program in a discrete, symbolic space of source code tokens. This symbolic search is fundamentally limited by its inability to directly reason about program behavior. We introduce Gradient-Based Program Repair (GBPR), a new paradigm that reframes program repair as continuous optimization in a differentiable numerical program space. Our core insight is to compile symbolic programs into differentiable numerical representations, enabling search in the numerical program space directly guided by program behavior. To evaluate GBPR, we present RaspBugs, a new benchmark of 1,466 buggy symbolic RASP programs and their respective numerical representations. Our experiments demonstrate that GBPR can effectively repair buggy symbolic programs by gradient-based optimization in the numerical program space, with convincing repair trajectories. To our knowledge, we are the first to state program repair as continuous optimization in a numerical program space. Our work establishes a new direction for program repair research, bridging two rich worlds: continuous optimization and program behavior.
RepairBench: Leaderboard of Frontier Models for Program Repair
Sep 27, 2024


AI-driven program repair uses AI models to repair buggy software by producing patches. Rapid advancements in AI surely impact state-of-the-art performance of program repair. Yet, grasping this progress requires frequent and standardized evaluations. We propose RepairBench, a novel leaderboard for AI-driven program repair. The key characteristics of RepairBench are: 1) it is execution-based: all patches are compiled and executed against a test suite, 2) it assesses frontier models in a frequent and standardized way. RepairBench leverages two high-quality benchmarks, Defects4J and GitBug-Java, to evaluate frontier models against real-world program repair tasks. We publicly release the evaluation framework of RepairBench. We will update the leaderboard as new frontier models are released.
Generative AI to Generate Test Data Generators
Jan 31, 2024Generating fake data is an essential dimension of modern software testing, as demonstrated by the number and significance of data faking libraries. Yet, developers of faking libraries cannot keep up with the wide range of data to be generated for different natural languages and domains. In this paper, we assess the ability of generative AI for generating test data in different domains. We design three types of prompts for Large Language Models (LLMs), which perform test data generation tasks at different levels of integrability: 1) raw test data generation, 2) synthesizing programs in a specific language that generate useful test data, and 3) producing programs that use state-of-the-art faker libraries. We evaluate our approach by prompting LLMs to generate test data for 11 domains. The results show that LLMs can successfully generate realistic test data generators in a wide range of domains at all three levels of integrability.
RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair
Dec 25, 2023



Automated Program Repair (APR) has evolved significantly with the advent of Large Language Models (LLMs). Fine-tuning LLMs for program repair is a recent avenue of research, with many dimensions which have not been explored. Existing work mostly fine-tunes LLMs with naive code representations and is fundamentally limited in its ability to fine-tune larger LLMs. To address this problem, we propose RepairLLaMA, a novel program repair approach that combines 1) code representations for APR and 2) the state-of-the-art parameter-efficient LLM fine-tuning technique called LoRA. This results in RepairLLaMA producing a highly effective `program repair adapter' for fixing bugs with language models. Our experiments demonstrate the validity of both concepts. First, fine-tuning adapters with program repair specific code representations enables the model to use meaningful repair signals. Second, parameter-efficient fine-tuning helps fine-tuning to converge and contributes to the effectiveness of the repair adapter to fix data-points outside the fine-tuning data distribution. Overall, RepairLLaMA correctly fixes 125 Defects4J v2 and 82 HumanEval-Java bugs, outperforming all baselines.
Monocular Trail Detection and Tracking Aided by Visual SLAM for Small Unmanned Aerial Vehicles
Jun 21, 2018
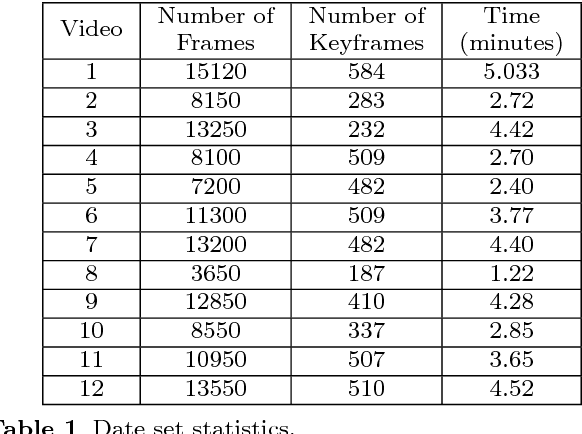
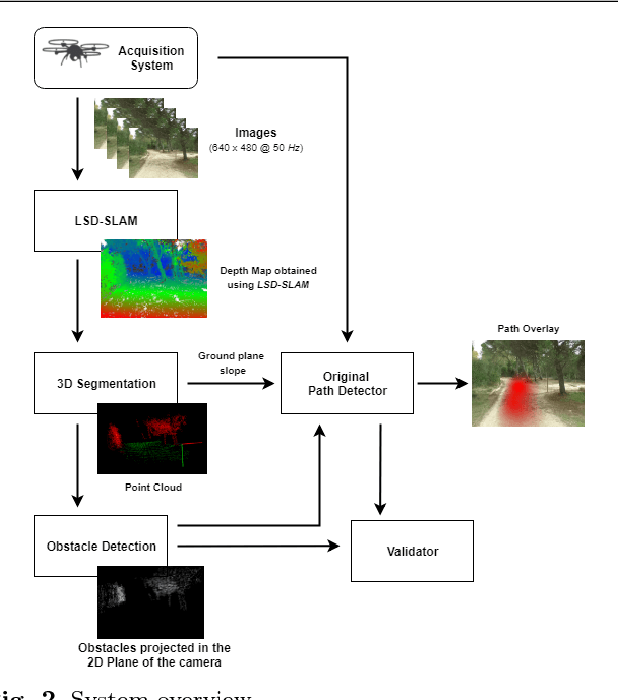
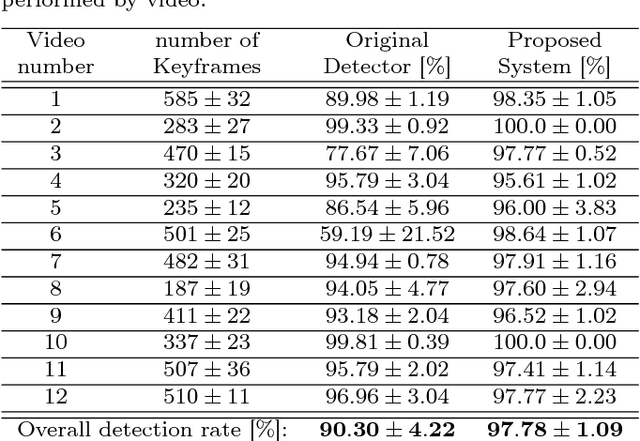
This paper presents a monocular vision system susceptible of being installed in unmanned small and medium-sized aerial vehicles built to perform missions in forest environments (e.g., search and rescue). The proposed system extends a previous monocular-based technique for trail detection and tracking so as to take into account volumetric data acquired from a Visual SLAM algorithm and, as a result, to increase its sturdiness upon challenging trails. The experimental results, obtained via a set of 12 videos recorded with a camera installed in a tele-operated, unmanned small-sized aerial vehicle, show the ability of the proposed system to overcome some of the difficulties of the original detector, attaining a success rate of $97.8\,\%$.