 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Rachel: Can an AI Become a Scholarly Author?
Nov 18, 2025
This paper documents Project Rachel, an action research study that created and tracked a complete AI academic identity named Rachel So. Through careful publication of AI-generated research papers, we investigate how the scholarly ecosystem responds to AI authorship. Rachel So published 10+ papers between March and October 2025, was cited, and received a peer review invitation. We discuss the implications of AI authorship on publishers, researchers, and the scientific system at large. This work contributes empirical action research data to the necessary debate about the future of scholarly communication with super human, hyper capable AI systems.
Gradient-Based Program Repair: Fixing Bugs in Continuous Program Spaces
May 23, 2025Automatic program repair seeks to generate correct code from buggy programs, with most approaches searching the correct program in a discrete, symbolic space of source code tokens. This symbolic search is fundamentally limited by its inability to directly reason about program behavior. We introduce Gradient-Based Program Repair (GBPR), a new paradigm that reframes program repair as continuous optimization in a differentiable numerical program space. Our core insight is to compile symbolic programs into differentiable numerical representations, enabling search in the numerical program space directly guided by program behavior. To evaluate GBPR, we present RaspBugs, a new benchmark of 1,466 buggy symbolic RASP programs and their respective numerical representations. Our experiments demonstrate that GBPR can effectively repair buggy symbolic programs by gradient-based optimization in the numerical program space, with convincing repair trajectories. To our knowledge, we are the first to state program repair as continuous optimization in a numerical program space. Our work establishes a new direction for program repair research, bridging two rich worlds: continuous optimization and program behavior.
RepairBench: Leaderboard of Frontier Models for Program Repair
Sep 27, 2024


AI-driven program repair uses AI models to repair buggy software by producing patches. Rapid advancements in AI surely impact state-of-the-art performance of program repair. Yet, grasping this progress requires frequent and standardized evaluations. We propose RepairBench, a novel leaderboard for AI-driven program repair. The key characteristics of RepairBench are: 1) it is execution-based: all patches are compiled and executed against a test suite, 2) it assesses frontier models in a frequent and standardized way. RepairBench leverages two high-quality benchmarks, Defects4J and GitBug-Java, to evaluate frontier models against real-world program repair tasks. We publicly release the evaluation framework of RepairBench. We will update the leaderboard as new frontier models are released.
DISL: Fueling Research with A Large Dataset of Solidity Smart Contracts
Mar 26, 2024


The DISL dataset features a collection of $514,506$ unique Solidity files that have been deployed to Ethereum mainnet. It caters to the need for a large and diverse dataset of real-world smart contracts. DISL serves as a resource for developing machine learning systems and for benchmarking software engineering tools designed for smart contracts. By aggregating every verified smart contract from Etherscan up to January 15, 2024, DISL surpasses existing datasets in size and recency.
Generative AI to Generate Test Data Generators
Jan 31, 2024Generating fake data is an essential dimension of modern software testing, as demonstrated by the number and significance of data faking libraries. Yet, developers of faking libraries cannot keep up with the wide range of data to be generated for different natural languages and domains. In this paper, we assess the ability of generative AI for generating test data in different domains. We design three types of prompts for Large Language Models (LLMs), which perform test data generation tasks at different levels of integrability: 1) raw test data generation, 2) synthesizing programs in a specific language that generate useful test data, and 3) producing programs that use state-of-the-art faker libraries. We evaluate our approach by prompting LLMs to generate test data for 11 domains. The results show that LLMs can successfully generate realistic test data generators in a wide range of domains at all three levels of integrability.
RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair
Dec 25, 2023



Automated Program Repair (APR) has evolved significantly with the advent of Large Language Models (LLMs). Fine-tuning LLMs for program repair is a recent avenue of research, with many dimensions which have not been explored. Existing work mostly fine-tunes LLMs with naive code representations and is fundamentally limited in its ability to fine-tune larger LLMs. To address this problem, we propose RepairLLaMA, a novel program repair approach that combines 1) code representations for APR and 2) the state-of-the-art parameter-efficient LLM fine-tuning technique called LoRA. This results in RepairLLaMA producing a highly effective `program repair adapter' for fixing bugs with language models. Our experiments demonstrate the validity of both concepts. First, fine-tuning adapters with program repair specific code representations enables the model to use meaningful repair signals. Second, parameter-efficient fine-tuning helps fine-tuning to converge and contributes to the effectiveness of the repair adapter to fix data-points outside the fine-tuning data distribution. Overall, RepairLLaMA correctly fixes 125 Defects4J v2 and 82 HumanEval-Java bugs, outperforming all baselines.
Supersonic: Learning to Generate Source Code Optimizations in C/C++
Oct 02, 2023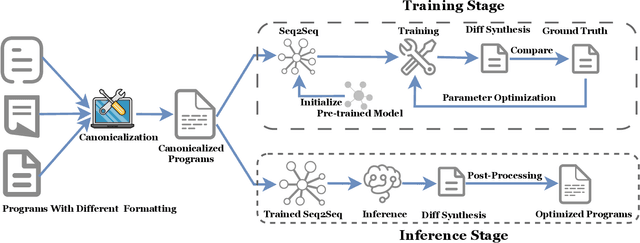


Software optimization refines programs for resource efficiency while preserving functionality. Traditionally, it is a process done by developers and compilers. This paper introduces a third option, automated optimization at the source code level. We present Supersonic, a neural approach targeting minor source code modifications for optimization. Using a seq2seq model, Supersonic is trained on C/C++ program pairs ($x_{t}$, $x_{t+1}$), where $x_{t+1}$ is an optimized version of $x_{t}$, and outputs a diff. Supersonic's performance is benchmarked against OpenAI's GPT-3.5-Turbo and GPT-4 on competitive programming tasks. The experiments show that Supersonic not only outperforms both models on the code optimization task but also minimizes the extent of the change with a model more than 600x smaller than GPT-3.5-Turbo and 3700x smaller than GPT-4.
Self-Supervised Learning to Prove Equivalence Between Programs via Semantics-Preserving Rewrite Rules
Sep 22, 2021

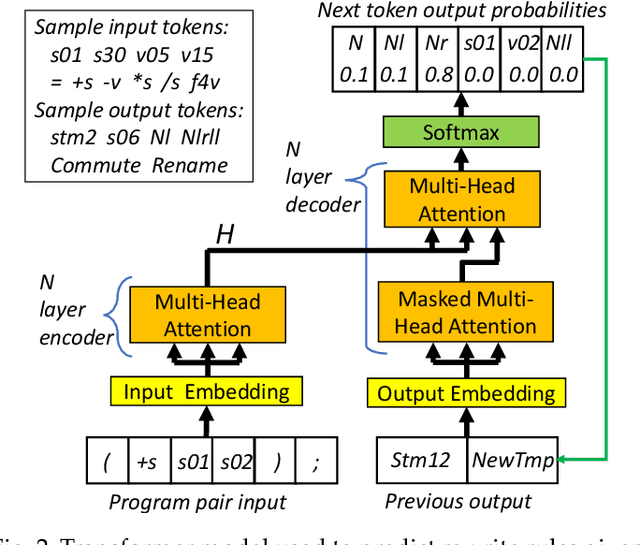
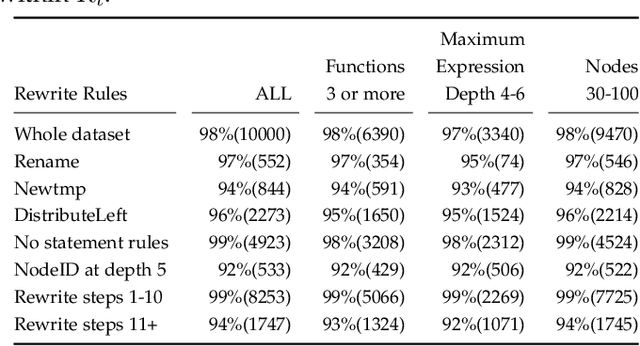
We target the problem of synthesizing proofs of semantic equivalence between two programs made of sequences of statements with complex symbolic expressions. We propose a neural network architecture based on the transformer to generate axiomatic proofs of equivalence between program pairs. We generate expressions which include scalars and vectors and support multi-typed rewrite rules to prove equivalence. For training the system, we develop an original training technique, which we call self-supervised sample selection. This incremental training improves the quality, generalizability and extensibility of the learned model. We study the effectiveness of the system to generate proofs of increasing length, and we demonstrate how transformer models learn to represent complex and verifiable symbolic reasoning. Our system, S4Eq, achieves 97% proof success on 10,000 pairs of programs while ensuring zero false positives by design.
Multimodal Representation for Neural Code Search
Jul 23, 2021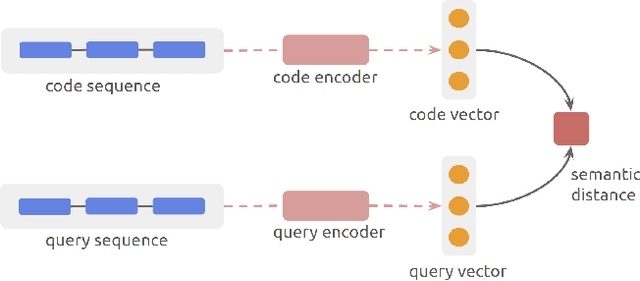
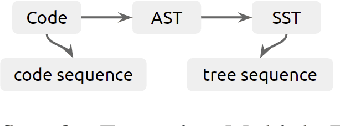
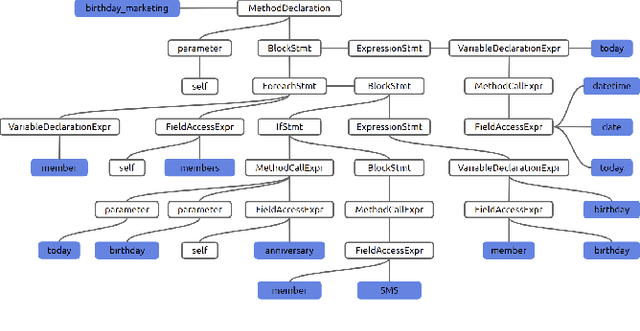
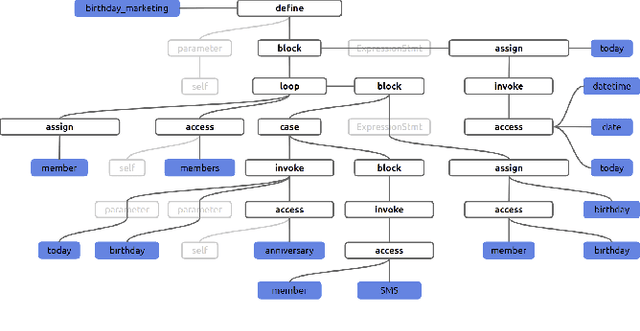
Semantic code search is about finding semantically relevant code snippets for a given natural language query. In the state-of-the-art approaches, the semantic similarity between code and query is quantified as the distance of their representation in the shared vector space. In this paper, to improve the vector space, we introduce tree-serialization methods on a simplified form of AST and build the multimodal representation for the code data. We conduct extensive experiments using a single corpus that is large-scale and multi-language: CodeSearchNet. Our results show that both our tree-serialized representations and multimodal learning model improve the performance of code search. Last, we define intuitive quantification metrics oriented to the completeness of semantic and syntactic information of the code data, to help understand the experimental findings.
Neural Transfer Learning for Repairing Security Vulnerabilities in C Code
Apr 16, 2021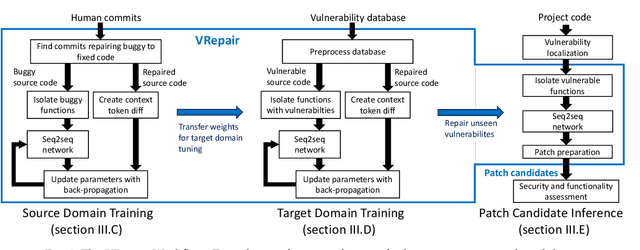


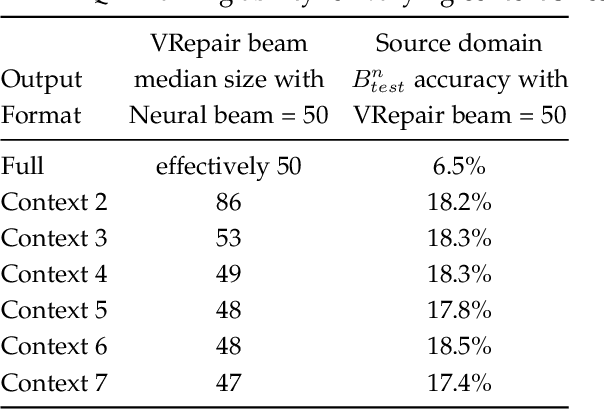
In this paper, we address the problem of automatic repair of software vulnerabilities with deep learning. The major problem with data-driven vulnerability repair is that the few existing datasets of known confirmed vulnerabilities consist of only a few thousand examples. However, training a deep learning model often requires hundreds of thousands of examples. In this work, we leverage the intuition that the bug fixing task and the vulnerability fixing task are related, and the knowledge learned from bug fixes can be transferred to fixing vulnerabilities. In the machine learning community, this technique is called transfer learning. In this paper, we propose an approach for repairing security vulnerabilities named VRepair which is based on transfer learning. VRepair is first trained on a large bug fix corpus, and is then tuned on a vulnerability fix dataset, which is an order of magnitudes smaller. In our experiments, we show that a model trained only on a bug fix corpus can already fix some vulnerabilities. Then, we demonstrate that transfer learning improves the ability to repair vulnerable C functions. In the end, we present evidence that transfer learning produces more stable and superior neural models for vulnerability repair.