 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy consumption of code small language models serving with runtime engines and execution providers
Dec 19, 2024Background. The rapid growth of Language Models (LMs), particularly in code generation, requires substantial computational resources, raising concerns about energy consumption and environmental impact. Optimizing LMs inference for energy efficiency is crucial, and Small Language Models (SLMs) offer a promising solution to reduce resource demands. Aim. Our goal is to analyze the impact of deep learning runtime engines and execution providers on energy consumption, execution time, and computing-resource utilization from the point of view of software engineers conducting inference in the context of code SLMs. Method. We conducted a technology-oriented, multi-stage experimental pipeline using twelve code generation SLMs to investigate energy consumption, execution time, and computing-resource utilization across the configurations. Results. Significant differences emerged across configurations. CUDA execution provider configurations outperformed CPU execution provider configurations in both energy consumption and execution time. Among the configurations, TORCH paired with CUDA demonstrated the greatest energy efficiency, achieving energy savings from 37.99% up to 89.16% compared to other serving configurations. Similarly, optimized runtime engines like ONNX with the CPU execution provider achieved from 8.98% up to 72.04% energy savings within CPU-based configurations. Also, TORCH paired with CUDA exhibited efficient computing-resource utilization. Conclusions. Serving configuration choice significantly impacts energy efficiency. While further research is needed, we recommend the above configurations best suited to software engineers' requirements for enhancing serving efficiency in energy and performance.
The Impact of Hyperparameters on Large Language Model Inference Performance: An Evaluation of vLLM and HuggingFace Pipelines
Aug 02, 2024The recent surge of open-source large language models (LLMs) enables developers to create AI-based solutions while maintaining control over aspects such as privacy and compliance, thereby providing governance and ownership of the model deployment process. To utilize these LLMs, inference engines are needed. These engines load the model's weights onto available resources, such as GPUs, and process queries to generate responses. The speed of inference, or performance, of the LLM, is critical for real-time applications, as it computes millions or billions of floating point operations per inference. Recently, advanced inference engines such as vLLM have emerged, incorporating novel mechanisms such as efficient memory management to achieve state-of-the-art performance. In this paper, we analyze the performance, particularly the throughput (tokens generated per unit of time), of 20 LLMs using two inference libraries: vLLM and HuggingFace's pipelines. We investigate how various hyperparameters, which developers must configure, influence inference performance. Our results reveal that throughput landscapes are irregular, with distinct peaks, highlighting the importance of hyperparameter optimization to achieve maximum performance. We also show that applying hyperparameter optimization when upgrading or downgrading the GPU model used for inference can improve throughput from HuggingFace pipelines by an average of 9.16% and 13.7%, respectively.
Identifying architectural design decisions for achieving green ML serving
Feb 12, 2024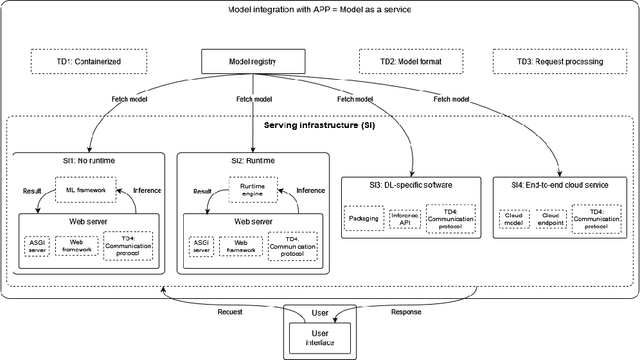
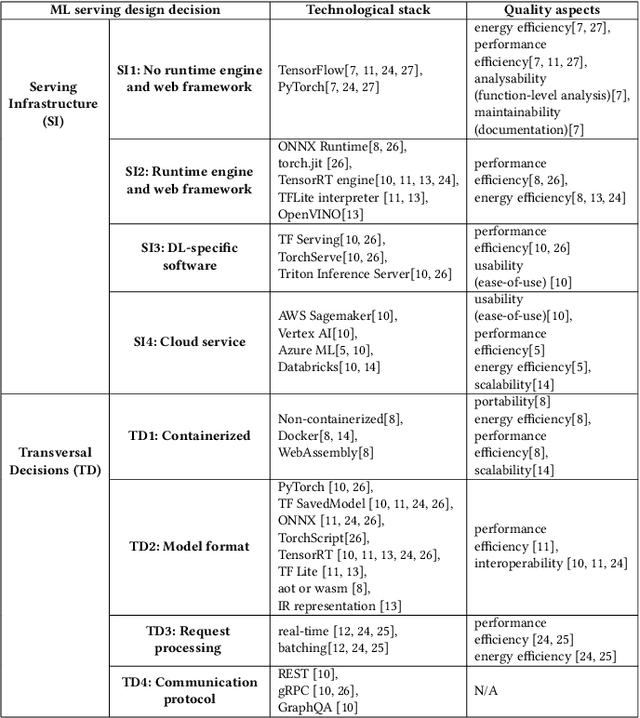
The growing use of large machine learning models highlights concerns about their increasing computational demands. While the energy consumption of their training phase has received attention, fewer works have considered the inference phase. For ML inference, the binding of ML models to the ML system for user access, known as ML serving, is a critical yet understudied step for achieving efficiency in ML applications. We examine the literature in ML architectural design decisions and Green AI, with a special focus on ML serving. The aim is to analyze ML serving architectural design decisions for the purpose of understanding and identifying them with respect to quality characteristics from the point of view of researchers and practitioners in the context of ML serving literature. Our results (i) identify ML serving architectural design decisions along with their corresponding components and associated technological stack, and (ii) provide an overview of the quality characteristics studied in the literature, including energy efficiency. This preliminary study is the first step in our goal to achieve green ML serving. Our analysis may aid ML researchers and practitioners in making green-aware architecture design decisions when serving their models.
Energy Efficiency of Training Neural Network Architectures: An Empirical Study
Feb 02, 2023



The evaluation of Deep Learning models has traditionally focused on criteria such as accuracy, F1 score, and related measures. The increasing availability of high computational power environments allows the creation of deeper and more complex models. However, the computations needed to train such models entail a large carbon footprint. In this work, we study the relations between DL model architectures and their environmental impact in terms of energy consumed and CO$_2$ emissions produced during training by means of an empirical study using Deep Convolutional Neural Networks. Concretely, we study: (i) the impact of the architecture and the location where the computations are hosted on the energy consumption and emissions produced; (ii) the trade-off between accuracy and energy efficiency; and (iii) the difference on the method of measurement of the energy consumed using software-based and hardware-based tools.
* Accepted in HICSS 2023. For its published version refer to the Proceedings of the 56th Hawaii International Conference on System Sciences; URI https://hdl.handle.net/10125/102727
Learning the Relation between Code Features and Code Transforms with Structured Prediction
Jul 22, 2019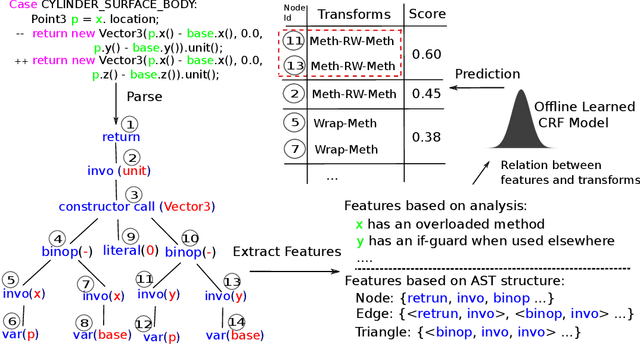
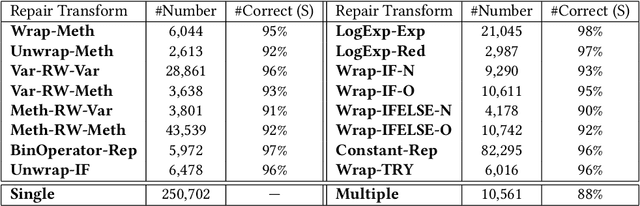
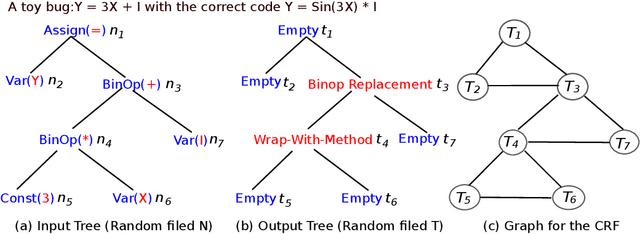
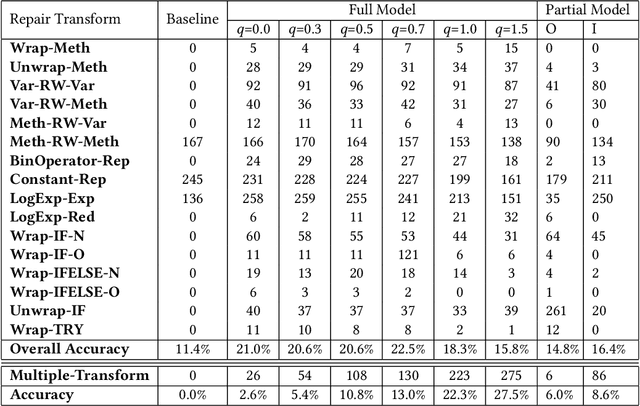
We present in this paper the first approach for structurally predicting code transforms at the level of AST nodes using conditional random fields. Our approach first learns offline a probabilistic model that captures how certain code transforms are applied to certain AST nodes, and then uses the learned model to predict transforms for new, unseen code snippets. We implement our approach in the context of repair transform prediction for Java programs. Our implementation contains a set of carefully designed code features, deals with the training data imbalance issue, and comprises transform constraints that are specific to code. We conduct a large-scale experimental evaluation based on a dataset of 4,590,679 bug fixing commits from real-world Java projects. The experimental results show that our approach predicts the code transforms with a success rate varying from 37.1% to 61.1% depending on the transforms.