 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Model Size Matter? A Comparison of Small and Large Language Models for Requirements Classification
Oct 24, 2025[Context and motivation] Large language models (LLMs) show notable results in natural language processing (NLP) tasks for requirements engineering (RE). However, their use is compromised by high computational cost, data sharing risks, and dependence on external services. In contrast, small language models (SLMs) offer a lightweight, locally deployable alternative. [Question/problem] It remains unclear how well SLMs perform compared to LLMs in RE tasks in terms of accuracy. [Results] Our preliminary study compares eight models, including three LLMs and five SLMs, on requirements classification tasks using the PROMISE, PROMISE Reclass, and SecReq datasets. Our results show that although LLMs achieve an average F1 score of 2% higher than SLMs, this difference is not statistically significant. SLMs almost reach LLMs performance across all datasets and even outperform them in recall on the PROMISE Reclass dataset, despite being up to 300 times smaller. We also found that dataset characteristics play a more significant role in performance than model size. [Contribution] Our study contributes with evidence that SLMs are a valid alternative to LLMs for requirements classification, offering advantages in privacy, cost, and local deployability.
What About Emotions? Guiding Fine-Grained Emotion Extraction from Mobile App Reviews
May 29, 2025Opinion mining plays a vital role in analysing user feedback and extracting insights from textual data. While most research focuses on sentiment polarity (e.g., positive, negative, neutral), fine-grained emotion classification in app reviews remains underexplored. This paper addresses this gap by identifying and addressing the challenges and limitations in fine-grained emotion analysis in the context of app reviews. Our study adapts Plutchik's emotion taxonomy to app reviews by developing a structured annotation framework and dataset. Through an iterative human annotation process, we define clear annotation guidelines and document key challenges in emotion classification. Additionally, we evaluate the feasibility of automating emotion annotation using large language models, assessing their cost-effectiveness and agreement with human-labelled data. Our findings reveal that while large language models significantly reduce manual effort and maintain substantial agreement with human annotators, full automation remains challenging due to the complexity of emotional interpretation. This work contributes to opinion mining by providing structured guidelines, an annotated dataset, and insights for developing automated pipelines to capture the complexity of emotions in app reviews.
Aggregating empirical evidence from data strategy studies: a case on model quantization
May 01, 2025



Background: As empirical software engineering evolves, more studies adopt data strategies$-$approaches that investigate digital artifacts such as models, source code, or system logs rather than relying on human subjects. Synthesizing results from such studies introduces new methodological challenges. Aims: This study assesses the effects of model quantization on correctness and resource efficiency in deep learning (DL) systems. Additionally, it explores the methodological implications of aggregating evidence from empirical studies that adopt data strategies. Method: We conducted a research synthesis of six primary studies that empirically evaluate model quantization. We applied the Structured Synthesis Method (SSM) to aggregate the findings, which combines qualitative and quantitative evidence through diagrammatic modeling. A total of 19 evidence models were extracted and aggregated. Results: The aggregated evidence indicates that model quantization weakly negatively affects correctness metrics while consistently improving resource efficiency metrics, including storage size, inference latency, and GPU energy consumption$-$a manageable trade-off for many DL deployment contexts. Evidence across quantization techniques remains fragmented, underscoring the need for more focused empirical studies per technique. Conclusions: Model quantization offers substantial efficiency benefits with minor trade-offs in correctness, making it a suitable optimization strategy for resource-constrained environments. This study also demonstrates the feasibility of using SSM to synthesize findings from data strategy-based research.
Addressing Quality Challenges in Deep Learning: The Role of MLOps and Domain Knowledge
Jan 14, 2025Deep learning (DL) systems present unique challenges in software engineering, especially concerning quality attributes like correctness and resource efficiency. While DL models achieve exceptional performance in specific tasks, engineering DL-based systems is still essential. The effort, cost, and potential diminishing returns of continual improvements must be carefully evaluated, as software engineers often face the critical decision of when to stop refining a system relative to its quality attributes. This experience paper explores the role of MLOps practices -- such as monitoring and experiment tracking -- in creating transparent and reproducible experimentation environments that enable teams to assess and justify the impact of design decisions on quality attributes. Furthermore, we report on experiences addressing the quality challenges by embedding domain knowledge into the design of a DL model and its integration within a larger system. The findings offer actionable insights into not only the benefits of domain knowledge and MLOps but also the strategic consideration of when to limit further optimizations in DL projects to maximize overall system quality and reliability.
Towards a Classification of Open-Source ML Models and Datasets for Software Engineering
Nov 14, 2024



Background: Open-Source Pre-Trained Models (PTMs) and datasets provide extensive resources for various Machine Learning (ML) tasks, yet these resources lack a classification tailored to Software Engineering (SE) needs. Aims: We apply an SE-oriented classification to PTMs and datasets on a popular open-source ML repository, Hugging Face (HF), and analyze the evolution of PTMs over time. Method: We conducted a repository mining study. We started with a systematically gathered database of PTMs and datasets from the HF API. Our selection was refined by analyzing model and dataset cards and metadata, such as tags, and confirming SE relevance using Gemini 1.5 Pro. All analyses are replicable, with a publicly accessible replication package. Results: The most common SE task among PTMs and datasets is code generation, with a primary focus on software development and limited attention to software management. Popular PTMs and datasets mainly target software development. Among ML tasks, text generation is the most common in SE PTMs and datasets. There has been a marked increase in PTMs for SE since 2023 Q2. Conclusions: This study underscores the need for broader task coverage to enhance the integration of ML within SE practices.
Leveraging Large Language Models for Mobile App Review Feature Extraction
Aug 02, 2024
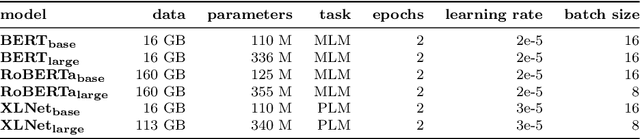

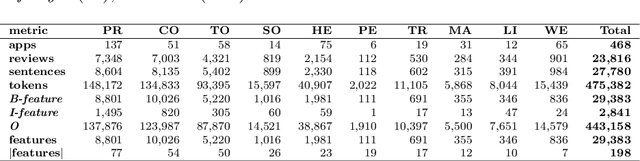
Mobile app review analysis presents unique challenges due to the low quality, subjective bias, and noisy content of user-generated documents. Extracting features from these reviews is essential for tasks such as feature prioritization and sentiment analysis, but it remains a challenging task. Meanwhile, encoder-only models based on the Transformer architecture have shown promising results for classification and information extraction tasks for multiple software engineering processes. This study explores the hypothesis that encoder-only large language models can enhance feature extraction from mobile app reviews. By leveraging crowdsourced annotations from an industrial context, we redefine feature extraction as a supervised token classification task. Our approach includes extending the pre-training of these models with a large corpus of user reviews to improve contextual understanding and employing instance selection techniques to optimize model fine-tuning. Empirical evaluations demonstrate that this method improves the precision and recall of extracted features and enhances performance efficiency. Key contributions include a novel approach to feature extraction, annotated datasets, extended pre-trained models, and an instance selection mechanism for cost-effective fine-tuning. This research provides practical methods and empirical evidence in applying large language models to natural language processing tasks within mobile app reviews, offering improved performance in feature extraction.
The More the Merrier? Navigating Accuracy vs. Energy Efficiency Design Trade-Offs in Ensemble Learning Systems
Jul 03, 2024Background: Machine learning (ML) model composition is a popular technique to mitigate shortcomings of a single ML model and to design more effective ML-enabled systems. While ensemble learning, i.e., forwarding the same request to several models and fusing their predictions, has been studied extensively for accuracy, we have insufficient knowledge about how to design energy-efficient ensembles. Objective: We therefore analyzed three types of design decisions for ensemble learning regarding a potential trade-off between accuracy and energy consumption: a) ensemble size, i.e., the number of models in the ensemble, b) fusion methods (majority voting vs. a meta-model), and c) partitioning methods (whole-dataset vs. subset-based training). Methods: By combining four popular ML algorithms for classification in different ensembles, we conducted a full factorial experiment with 11 ensembles x 4 datasets x 2 fusion methods x 2 partitioning methods (176 combinations). For each combination, we measured accuracy (F1-score) and energy consumption in J (for both training and inference). Results: While a larger ensemble size significantly increased energy consumption (size 2 ensembles consumed 37.49% less energy than size 3 ensembles, which in turn consumed 26.96% less energy than the size 4 ensembles), it did not significantly increase accuracy. Furthermore, majority voting outperformed meta-model fusion both in terms of accuracy (Cohen's d of 0.38) and energy consumption (Cohen's d of 0.92). Lastly, subset-based training led to significantly lower energy consumption (Cohen's d of 0.91), while training on the whole dataset did not increase accuracy significantly. Conclusions: From a Green AI perspective, we recommend designing ensembles of small size (2 or maximum 3 models), using subset-based training, majority voting, and energy-efficient ML algorithms like decision trees, Naive Bayes, or KNN.
Lessons Learned from Mining the Hugging Face Repository
Feb 11, 2024The rapidly evolving fields of Machine Learning (ML) and Artificial Intelligence have witnessed the emergence of platforms like Hugging Face (HF) as central hubs for model development and sharing. This experience report synthesizes insights from two comprehensive studies conducted on HF, focusing on carbon emissions and the evolutionary and maintenance aspects of ML models. Our objective is to provide a practical guide for future researchers embarking on mining software repository studies within the HF ecosystem to enhance the quality of these studies. We delve into the intricacies of the replication package used in our studies, highlighting the pivotal tools and methodologies that facilitated our analysis. Furthermore, we propose a nuanced stratified sampling strategy tailored for the diverse HF Hub dataset, ensuring a representative and comprehensive analytical approach. The report also introduces preliminary guidelines, transitioning from repository mining to cohort studies, to establish causality in repository mining studies, particularly within the ML model of HF context. This transition is inspired by existing frameworks and is adapted to suit the unique characteristics of the HF model ecosystem. Our report serves as a guiding framework for researchers, contributing to the responsible and sustainable advancement of ML, and fostering a deeper understanding of the broader implications of ML models.
Towards green AI-based software systems: an architecture-centric approach
Jul 19, 2023

Nowadays, AI-based systems have achieved outstanding results and have outperformed humans in different domains. However, the processes of training AI models and inferring from them require high computational resources, which pose a significant challenge in the current energy efficiency societal demand. To cope with this challenge, this research project paper describes the main vision, goals, and expected outcomes of the GAISSA project. The GAISSA project aims at providing data scientists and software engineers tool-supported, architecture-centric methods for the modelling and development of green AI-based systems. Although the project is in an initial stage, we describe the current research results, which illustrate the potential to achieve GAISSA objectives.
Do DL models and training environments have an impact on energy consumption?
Jul 18, 2023



Current research in the computer vision field mainly focuses on improving Deep Learning (DL) correctness and inference time performance. However, there is still little work on the huge carbon footprint that has training DL models. This study aims to analyze the impact of the model architecture and training environment when training greener computer vision models. We divide this goal into two research questions. First, we analyze the effects of model architecture on achieving greener models while keeping correctness at optimal levels. Second, we study the influence of the training environment on producing greener models. To investigate these relationships, we collect multiple metrics related to energy efficiency and model correctness during the models' training. Then, we outline the trade-offs between the measured energy efficiency and the models' correctness regarding model architecture, and their relationship with the training environment. We conduct this research in the context of a computer vision system for image classification. In conclusion, we show that selecting the proper model architecture and training environment can reduce energy consumption dramatically (up to 98.83%) at the cost of negligible decreases in correctness. Also, we find evidence that GPUs should scale with the models' computational complexity for better energy efficiency.