 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecturally Significant MLOps Guidelines for ML Model Integration and Deployment: a Gray Literature Review
Jun 03, 2026Context. Despite the growing adoption of Machine Learning Operations (MLOps), teams often approach MLOps projects in an ad hoc manner due to the lack of consolidated architectural guidance. The community would benefit from a reference that synthesizes knowledge to inform the architectural design of MLOps systems, especially regarding the integration and deployment of ML models. Objective. In response, our goal is to provide a comprehensive overview of architecturally significant guidelines for the integration and deployment of ML models in MLOps systems. Method. We conduct a gray literature review of 103 web sources to analyze state-of-practice knowledge on MLOps model integration and deployment. We then apply thematic analysis to synthesize these practices into recommended guidelines. Results. We contribute a collection of 25 architecturally significant MLOps guidelines for model integration and deployment, organized into five categories, and describe their impact on the overall system architecture. Conclusion. Our results serve as an overview of state-of-practice MLOps guidelines to support researchers and practitioners with the integration and deployment of ML models in their MLOps systems.
How Do Companies Manage the Environmental Sustainability of AI? An Interview Study About Green AI Efforts and Regulations
May 12, 2025With the ever-growing adoption of artificial intelligence (AI), AI-based software and its negative impact on the environment are no longer negligible, and studying and mitigating this impact has become a critical area of research. However, it is currently unclear which role environmental sustainability plays during AI adoption in industry and how AI regulations influence Green AI practices and decision-making in industry. We therefore aim to investigate the Green AI perception and management of industry practitioners. To this end, we conducted a total of 11 interviews with participants from 10 different organizations that adopted AI-based software. The interviews explored three main themes: AI adoption, current efforts in mitigating the negative environmental impact of AI, and the influence of the EU AI Act and the Corporate Sustainability Reporting Directive (CSRD). Our findings indicate that 9 of 11 participants prioritized business efficiency during AI adoption, with minimal consideration of environmental sustainability. Monitoring and mitigation of AI's environmental impact were very limited. Only one participant monitored negative environmental effects. Regarding applied mitigation practices, six participants reported no actions, with the others sporadically mentioning techniques like prompt engineering, relying on smaller models, or not overusing AI. Awareness and compliance with the EU AI Act are low, with only one participant reporting on its influence, while the CSRD drove sustainability reporting efforts primarily in larger companies. All in all, our findings reflect a lack of urgency and priority for sustainable AI among these companies. We suggest that current regulations are not very effective, which has implications for policymakers. Additionally, there is a need to raise industry awareness, but also to provide user-friendly techniques and tools for Green AI practices.
How Mature is Requirements Engineering for AI-based Systems? A Systematic Mapping Study on Practices, Challenges, and Future Research Directions
Sep 11, 2024
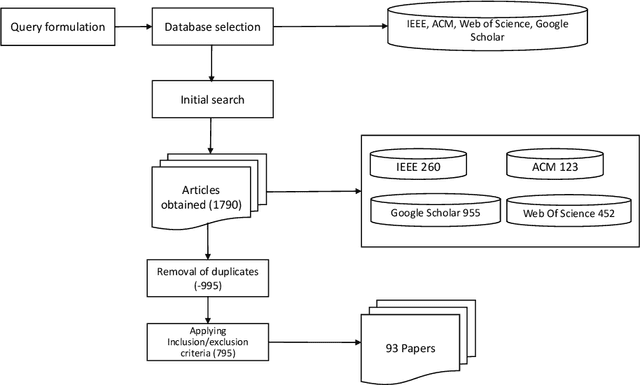


Artificial intelligence (AI) permeates all fields of life, which resulted in new challenges in requirements engineering for artificial intelligence (RE4AI), e.g., the difficulty in specifying and validating requirements for AI or considering new quality requirements due to emerging ethical implications. It is currently unclear if existing RE methods are sufficient or if new ones are needed to address these challenges. Therefore, our goal is to provide a comprehensive overview of RE4AI to researchers and practitioners. What has been achieved so far, i.e., what practices are available, and what research gaps and challenges still need to be addressed? To achieve this, we conducted a systematic mapping study combining query string search and extensive snowballing. The extracted data was aggregated, and results were synthesized using thematic analysis. Our selection process led to the inclusion of 126 primary studies. Existing RE4AI research focuses mainly on requirements analysis and elicitation, with most practices applied in these areas. Furthermore, we identified requirements specification, explainability, and the gap between machine learning engineers and end-users as the most prevalent challenges, along with a few others. Additionally, we proposed seven potential research directions to address these challenges. Practitioners can use our results to identify and select suitable RE methods for working on their AI-based systems, while researchers can build on the identified gaps and research directions to push the field forward.
The More the Merrier? Navigating Accuracy vs. Energy Efficiency Design Trade-Offs in Ensemble Learning Systems
Jul 03, 2024Background: Machine learning (ML) model composition is a popular technique to mitigate shortcomings of a single ML model and to design more effective ML-enabled systems. While ensemble learning, i.e., forwarding the same request to several models and fusing their predictions, has been studied extensively for accuracy, we have insufficient knowledge about how to design energy-efficient ensembles. Objective: We therefore analyzed three types of design decisions for ensemble learning regarding a potential trade-off between accuracy and energy consumption: a) ensemble size, i.e., the number of models in the ensemble, b) fusion methods (majority voting vs. a meta-model), and c) partitioning methods (whole-dataset vs. subset-based training). Methods: By combining four popular ML algorithms for classification in different ensembles, we conducted a full factorial experiment with 11 ensembles x 4 datasets x 2 fusion methods x 2 partitioning methods (176 combinations). For each combination, we measured accuracy (F1-score) and energy consumption in J (for both training and inference). Results: While a larger ensemble size significantly increased energy consumption (size 2 ensembles consumed 37.49% less energy than size 3 ensembles, which in turn consumed 26.96% less energy than the size 4 ensembles), it did not significantly increase accuracy. Furthermore, majority voting outperformed meta-model fusion both in terms of accuracy (Cohen's d of 0.38) and energy consumption (Cohen's d of 0.92). Lastly, subset-based training led to significantly lower energy consumption (Cohen's d of 0.91), while training on the whole dataset did not increase accuracy significantly. Conclusions: From a Green AI perspective, we recommend designing ensembles of small size (2 or maximum 3 models), using subset-based training, majority voting, and energy-efficient ML algorithms like decision trees, Naive Bayes, or KNN.
How to Sustainably Monitor ML-Enabled Systems? Accuracy and Energy Efficiency Tradeoffs in Concept Drift Detection
Apr 30, 2024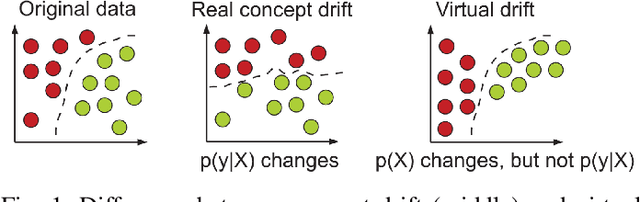
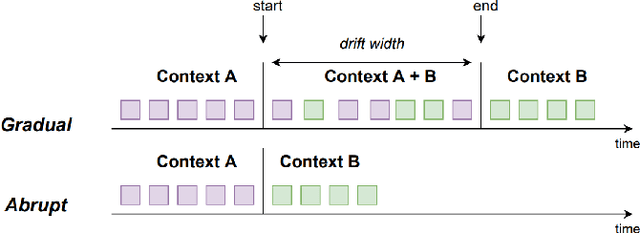
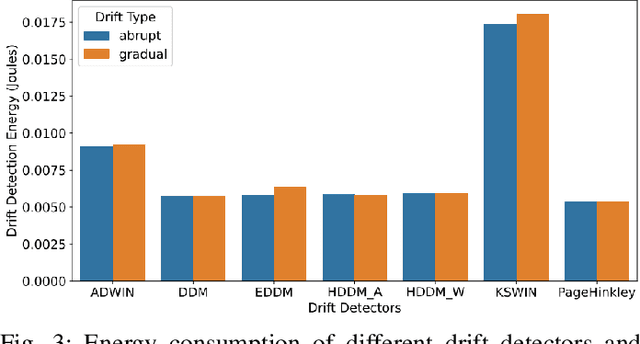
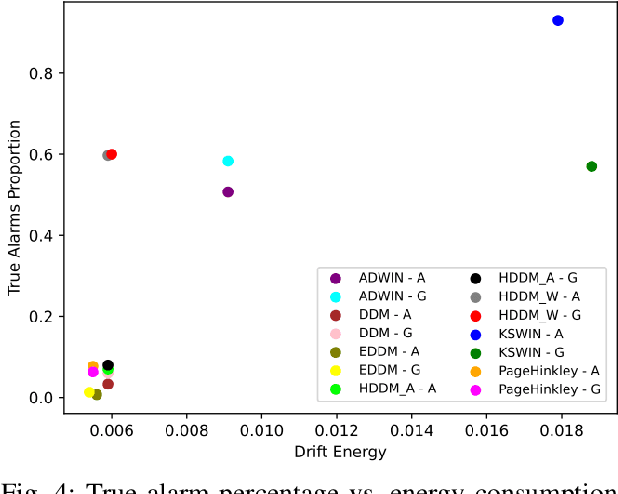
ML-enabled systems that are deployed in a production environment typically suffer from decaying model prediction quality through concept drift, i.e., a gradual change in the statistical characteristics of a certain real-world domain. To combat this, a simple solution is to periodically retrain ML models, which unfortunately can consume a lot of energy. One recommended tactic to improve energy efficiency is therefore to systematically monitor the level of concept drift and only retrain when it becomes unavoidable. Different methods are available to do this, but we know very little about their concrete impact on the tradeoff between accuracy and energy efficiency, as these methods also consume energy themselves. To address this, we therefore conducted a controlled experiment to study the accuracy vs. energy efficiency tradeoff of seven common methods for concept drift detection. We used five synthetic datasets, each in a version with abrupt and one with gradual drift, and trained six different ML models as base classifiers. Based on a full factorial design, we tested 420 combinations (7 drift detectors * 5 datasets * 2 types of drift * 6 base classifiers) and compared energy consumption and drift detection accuracy. Our results indicate that there are three types of detectors: a) detectors that sacrifice energy efficiency for detection accuracy (KSWIN), b) balanced detectors that consume low to medium energy with good accuracy (HDDM_W, ADWIN), and c) detectors that consume very little energy but are unusable in practice due to very poor accuracy (HDDM_A, PageHinkley, DDM, EDDM). By providing rich evidence for this energy efficiency tactic, our findings support ML practitioners in choosing the best suited method of concept drift detection for their ML-enabled systems.
Balancing Progress and Responsibility: A Synthesis of Sustainability Trade-Offs of AI-Based Systems
Apr 05, 2024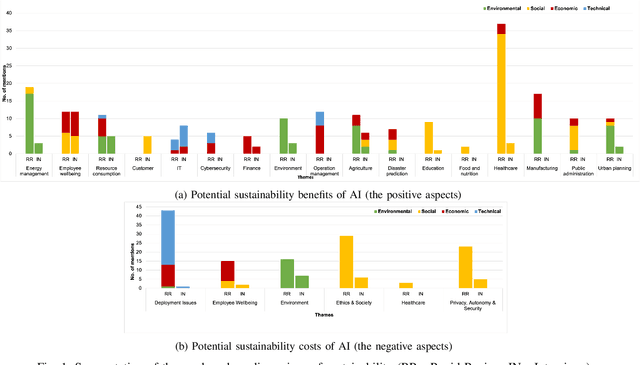
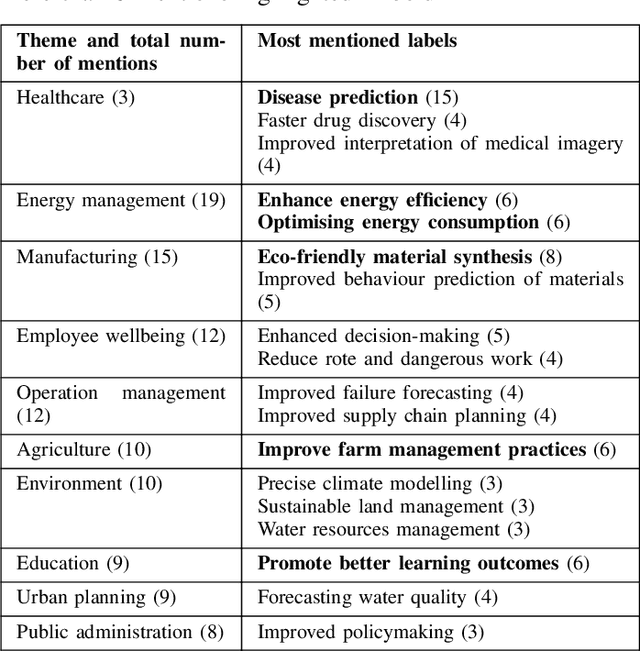
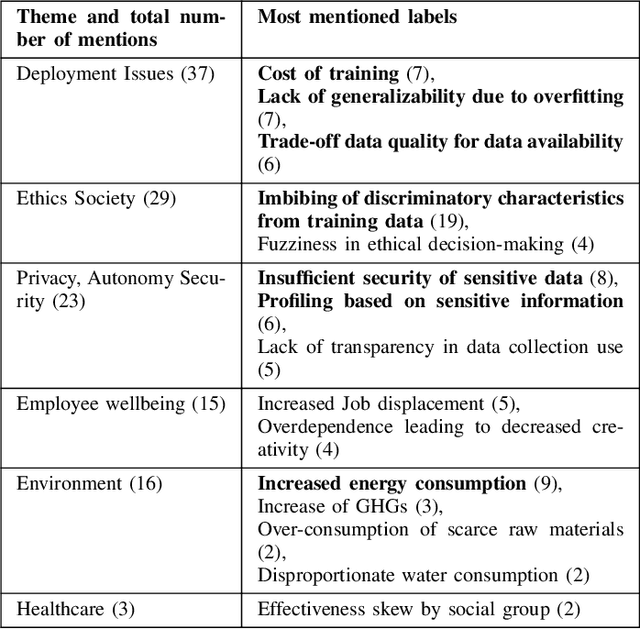
Recent advances in artificial intelligence (AI) capabilities have increased the eagerness of companies to integrate AI into software systems. While AI can be used to have a positive impact on several dimensions of sustainability, this is often overshadowed by its potential negative influence. While many studies have explored sustainability factors in isolation, there is insufficient holistic coverage of potential sustainability benefits or costs that practitioners need to consider during decision-making for AI adoption. We therefore aim to synthesize trade-offs related to sustainability in the context of integrating AI into software systems. We want to make the sustainability benefits and costs of integrating AI more transparent and accessible for practitioners. The study was conducted in collaboration with a Dutch financial organization. We first performed a rapid review that led to the inclusion of 151 research papers. Afterward, we conducted six semi-structured interviews to enrich the data with industry perspectives. The combined results showcase the potential sustainability benefits and costs of integrating AI. The labels synthesized from the review regarding potential sustainability benefits were clustered into 16 themes, with "energy management" being the most frequently mentioned one. 11 themes were identified in the interviews, with the top mentioned theme being "employee wellbeing". Regarding sustainability costs, the review discovered seven themes, with "deployment issues" being the most popular one, followed by "ethics & society". "Environmental issues" was the top theme from the interviews. Our results provide valuable insights to organizations and practitioners for understanding the potential sustainability implications of adopting AI.
A Synthesis of Green Architectural Tactics for ML-Enabled Systems
Dec 15, 2023The rapid adoption of artificial intelligence (AI) and machine learning (ML) has generated growing interest in understanding their environmental impact and the challenges associated with designing environmentally friendly ML-enabled systems. While Green AI research, i.e., research that tries to minimize the energy footprint of AI, is receiving increasing attention, very few concrete guidelines are available on how ML-enabled systems can be designed to be more environmentally sustainable. In this paper, we provide a catalog of 30 green architectural tactics for ML-enabled systems to fill this gap. An architectural tactic is a high-level design technique to improve software quality, in our case environmental sustainability. We derived the tactics from the analysis of 51 peer-reviewed publications that primarily explore Green AI, and validated them using a focus group approach with three experts. The 30 tactics we identified are aimed to serve as an initial reference guide for further exploration into Green AI from a software engineering perspective, and assist in designing sustainable ML-enabled systems. To enhance transparency and facilitate their widespread use and extension, we make the tactics available online in easily consumable formats. Wide-spread adoption of these tactics has the potential to substantially reduce the societal impact of ML-enabled systems regarding their energy and carbon footprint.
AI Techniques in the Microservices Life-Cycle: A Survey
May 25, 2023Microservices is a popular architectural style for the development of distributed software, with an emphasis on modularity, scalability, and flexibility. Indeed, in microservice systems, functionalities are provided by loosely coupled, small services, each focusing on a specific business capability. Building a system according to the microservices architectural style brings a number of challenges, mainly related to how the different microservices are deployed and coordinated and how they interact. In this paper, we provide a survey about how techniques in the area of Artificial Intelligence have been used to tackle these challenges.
Exploring the Carbon Footprint of Hugging Face's ML Models: A Repository Mining Study
May 18, 2023



The rise of machine learning (ML) systems has exacerbated their carbon footprint due to increased capabilities and model sizes. However, there is scarce knowledge on how the carbon footprint of ML models is actually measured, reported, and evaluated. In light of this, the paper aims to analyze the measurement of the carbon footprint of 1,417 ML models and associated datasets on Hugging Face, which is the most popular repository for pretrained ML models. The goal is to provide insights and recommendations on how to report and optimize the carbon efficiency of ML models. The study includes the first repository mining study on the Hugging Face Hub API on carbon emissions. This study seeks to answer two research questions: (1) how do ML model creators measure and report carbon emissions on Hugging Face Hub?, and (2) what aspects impact the carbon emissions of training ML models? The study yielded several key findings. These include a decreasing proportion of carbon emissions-reporting models, a slight decrease in reported carbon footprint on Hugging Face over the past 2 years, and a continued dominance of NLP as the main application domain. Furthermore, the study uncovers correlations between carbon emissions and various attributes such as model size, dataset size, and ML application domains. These results highlight the need for software measurements to improve energy reporting practices and promote carbon-efficient model development within the Hugging Face community. In response to this issue, two classifications are proposed: one for categorizing models based on their carbon emission reporting practices and another for their carbon efficiency. The aim of these classification proposals is to foster transparency and sustainable model development within the ML community.
A Case Study on AI Engineering Practices: Developing an Autonomous Stock Trading System
Mar 23, 2023
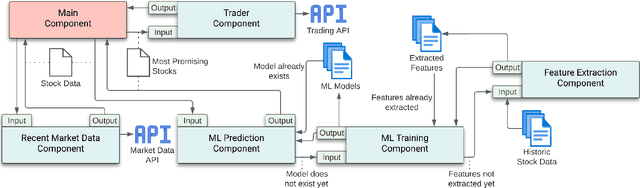


Today, many systems use artificial intelligence (AI) to solve complex problems. While this often increases system effectiveness, developing a production-ready AI-based system is a difficult task. Thus, solid AI engineering practices are required to ensure the quality of the resulting system and to improve the development process. While several practices have already been proposed for the development of AI-based systems, detailed practical experiences of applying these practices are rare. In this paper, we aim to address this gap by collecting such experiences during a case study, namely the development of an autonomous stock trading system that uses machine learning functionality to invest in stocks. We selected 10 AI engineering practices from the literature and systematically applied them during development, with the goal to collect evidence about their applicability and effectiveness. Using structured field notes, we documented our experiences. Furthermore, we also used field notes to document challenges that occurred during the development, and the solutions we applied to overcome them. Afterwards, we analyzed the collected field notes, and evaluated how each practice improved the development. Lastly, we compared our evidence with existing literature. Most applied practices improved our system, albeit to varying extent, and we were able to overcome all major challenges. The qualitative results provide detailed accounts about 10 AI engineering practices, as well as challenges and solutions associated with such a project. Our experiences therefore enrich the emerging body of evidence in this field, which may be especially helpful for practitioner teams new to AI engineering.