 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTen Years of Teaching Empirical Software Engineering in the context of Energy-efficient Software
Jul 08, 2024
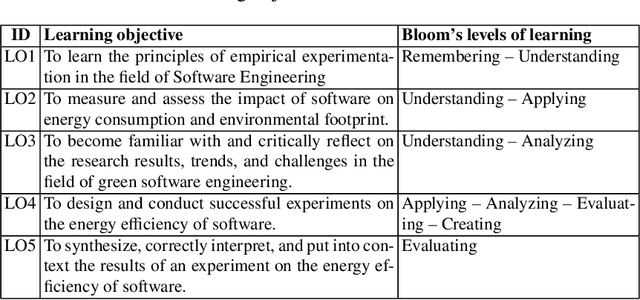
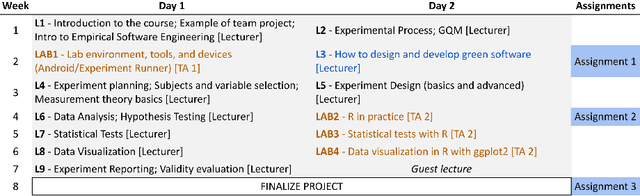
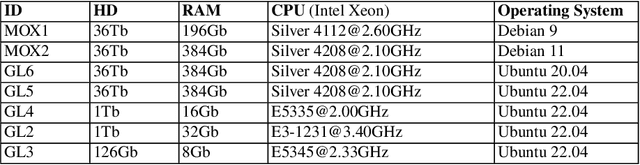
In this chapter we share our experience in running ten editions of the Green Lab course at the Vrije Universiteit Amsterdam, the Netherlands. The course is given in the Software Engineering and Green IT track of the Computer Science Master program of the VU. The course takes place every year over a 2-month period and teaches Computer Science students the fundamentals of Empirical Software Engineering in the context of energy-efficient software. The peculiarity of the course is its research orientation: at the beginning of the course the instructor presents a catalog of scientifically relevant goals, and each team of students signs up for one of them and works together for 2 months on their own experiment for achieving the goal. Each team goes over the classic steps of an empirical study, starting from a precise formulation of the goal and research questions to context definition, selection of experimental subjects and objects, definition of experimental variables, experiment execution, data analysis, and reporting. Over the years, the course became well-known within the Software Engineering community since it led to several scientific studies that have been published at various scientific conferences and journals. Also, students execute their experiments using \textit{open-source tools}, which are developed and maintained by researchers and other students within the program, thus creating a virtuous community of learners where students exchange ideas, help each other, and learn how to collaboratively contribute to open-source projects in a safe environment.
A Controlled Experiment on the Energy Efficiency of the Source Code Generated by Code Llama
May 06, 2024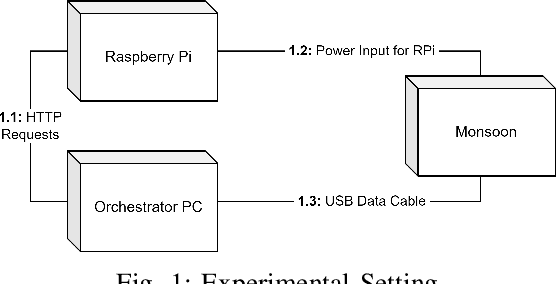
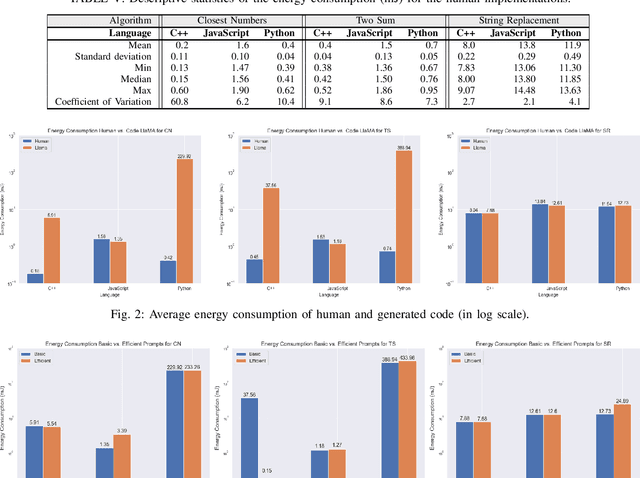
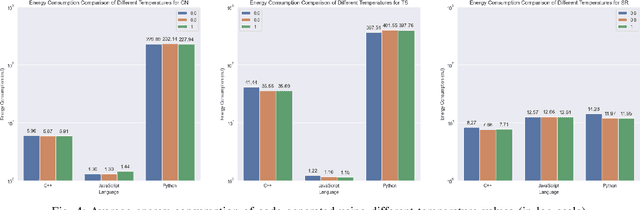
Context. Nowadays, 83% of software developers use Large Language Models (LLMs) to generate code. LLMs recently became essential to increase the productivity of software developers and decrease the time and cost of software development. Developers ranging from novices to experts use LLM tools not only to detect and patch bugs, but also to integrate generated code into their software. However, as of today there is no objective assessment of the energy efficiency of the source code generated by LLM tools. Released in August 2023, Code Llama is one of the most recent LLM tools. Goal. In this paper, we present an empirical study that assesses the energy efficiency of Code Llama with respect to human-written source code. Method. We design an experiment involving three human-written benchmarks implemented in C++, JavaScript, and Python. We ask Code Llama to generate the code of the benchmarks using different prompts and temperatures. Therefore, we execute both implementations and profile their energy efficiency. Results. Our study shows that the energy efficiency of code generated by Code Llama is heavily-dependent on the chosen programming language and the specific code problem at hand. Also, human implementations tend to be more energy efficient overall, with generated JavaScript code outperforming its human counterpart. Moreover, explicitly asking Code Llama to generate energy-efficient code results in an equal or worse energy efficiency, as well as using different temperatures seems not to affect the energy efficiency of generated code. Conclusions. According to our results, code generated using Code Llama does not guarantee energy efficiency, even when prompted to do so. Therefore, software developers should evaluate the energy efficiency of generated code before integrating it into the software system under development.
How to Sustainably Monitor ML-Enabled Systems? Accuracy and Energy Efficiency Tradeoffs in Concept Drift Detection
Apr 30, 2024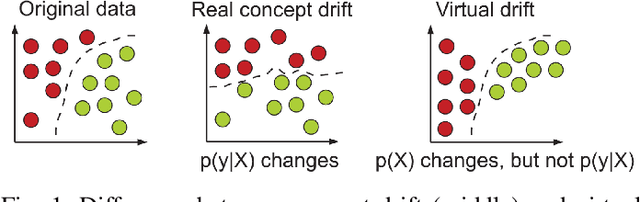
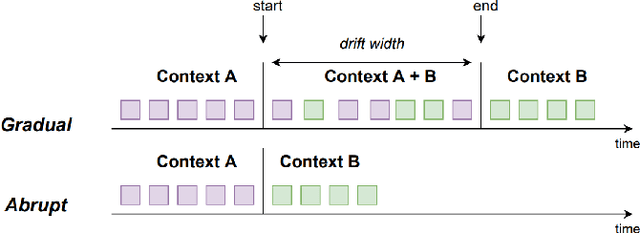
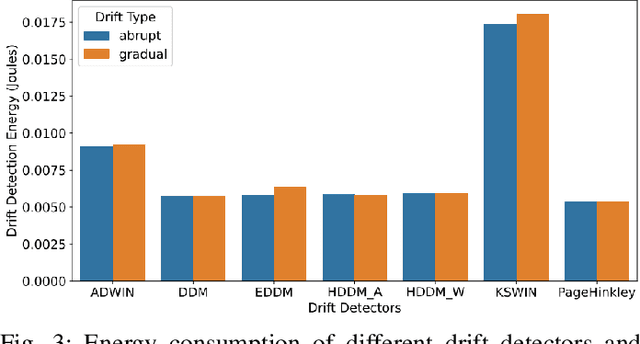
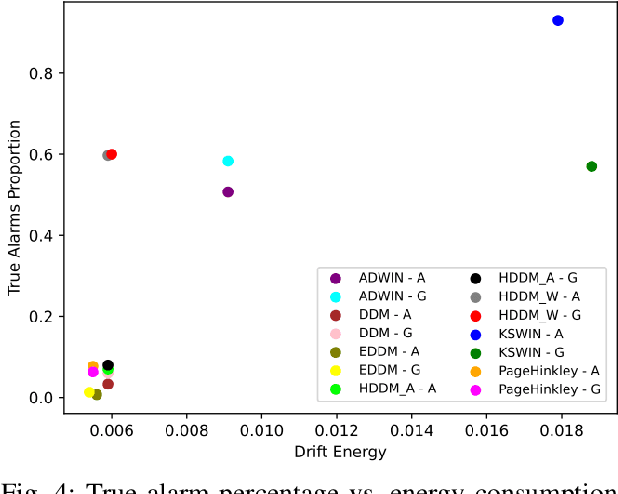
ML-enabled systems that are deployed in a production environment typically suffer from decaying model prediction quality through concept drift, i.e., a gradual change in the statistical characteristics of a certain real-world domain. To combat this, a simple solution is to periodically retrain ML models, which unfortunately can consume a lot of energy. One recommended tactic to improve energy efficiency is therefore to systematically monitor the level of concept drift and only retrain when it becomes unavoidable. Different methods are available to do this, but we know very little about their concrete impact on the tradeoff between accuracy and energy efficiency, as these methods also consume energy themselves. To address this, we therefore conducted a controlled experiment to study the accuracy vs. energy efficiency tradeoff of seven common methods for concept drift detection. We used five synthetic datasets, each in a version with abrupt and one with gradual drift, and trained six different ML models as base classifiers. Based on a full factorial design, we tested 420 combinations (7 drift detectors * 5 datasets * 2 types of drift * 6 base classifiers) and compared energy consumption and drift detection accuracy. Our results indicate that there are three types of detectors: a) detectors that sacrifice energy efficiency for detection accuracy (KSWIN), b) balanced detectors that consume low to medium energy with good accuracy (HDDM_W, ADWIN), and c) detectors that consume very little energy but are unusable in practice due to very poor accuracy (HDDM_A, PageHinkley, DDM, EDDM). By providing rich evidence for this energy efficiency tactic, our findings support ML practitioners in choosing the best suited method of concept drift detection for their ML-enabled systems.