 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe More the Merrier? Navigating Accuracy vs. Energy Efficiency Design Trade-Offs in Ensemble Learning Systems
Jul 03, 2024Background: Machine learning (ML) model composition is a popular technique to mitigate shortcomings of a single ML model and to design more effective ML-enabled systems. While ensemble learning, i.e., forwarding the same request to several models and fusing their predictions, has been studied extensively for accuracy, we have insufficient knowledge about how to design energy-efficient ensembles. Objective: We therefore analyzed three types of design decisions for ensemble learning regarding a potential trade-off between accuracy and energy consumption: a) ensemble size, i.e., the number of models in the ensemble, b) fusion methods (majority voting vs. a meta-model), and c) partitioning methods (whole-dataset vs. subset-based training). Methods: By combining four popular ML algorithms for classification in different ensembles, we conducted a full factorial experiment with 11 ensembles x 4 datasets x 2 fusion methods x 2 partitioning methods (176 combinations). For each combination, we measured accuracy (F1-score) and energy consumption in J (for both training and inference). Results: While a larger ensemble size significantly increased energy consumption (size 2 ensembles consumed 37.49% less energy than size 3 ensembles, which in turn consumed 26.96% less energy than the size 4 ensembles), it did not significantly increase accuracy. Furthermore, majority voting outperformed meta-model fusion both in terms of accuracy (Cohen's d of 0.38) and energy consumption (Cohen's d of 0.92). Lastly, subset-based training led to significantly lower energy consumption (Cohen's d of 0.91), while training on the whole dataset did not increase accuracy significantly. Conclusions: From a Green AI perspective, we recommend designing ensembles of small size (2 or maximum 3 models), using subset-based training, majority voting, and energy-efficient ML algorithms like decision trees, Naive Bayes, or KNN.
How to Sustainably Monitor ML-Enabled Systems? Accuracy and Energy Efficiency Tradeoffs in Concept Drift Detection
Apr 30, 2024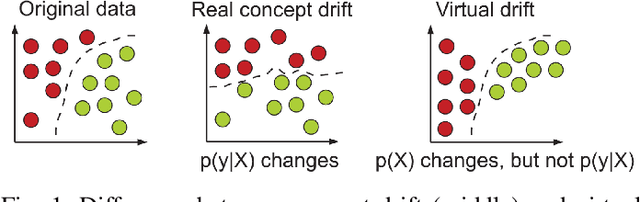
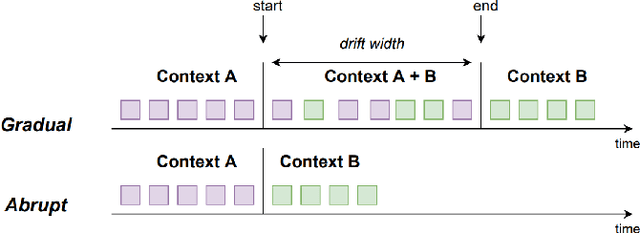
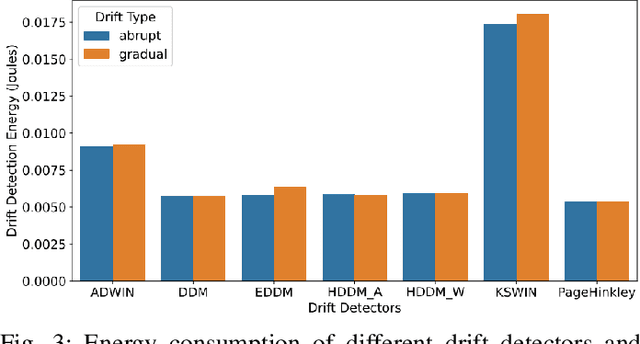
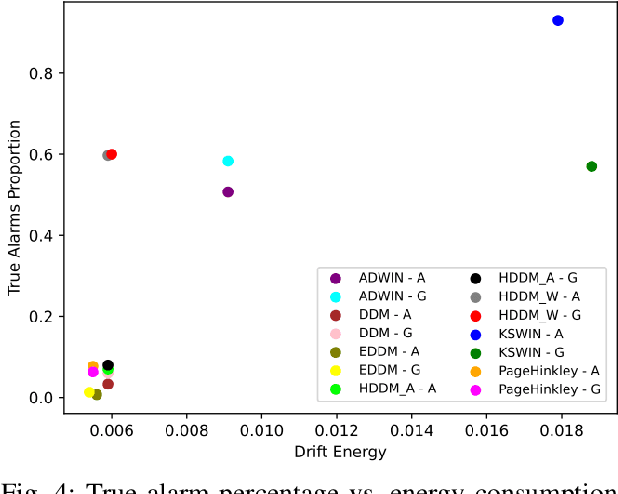
ML-enabled systems that are deployed in a production environment typically suffer from decaying model prediction quality through concept drift, i.e., a gradual change in the statistical characteristics of a certain real-world domain. To combat this, a simple solution is to periodically retrain ML models, which unfortunately can consume a lot of energy. One recommended tactic to improve energy efficiency is therefore to systematically monitor the level of concept drift and only retrain when it becomes unavoidable. Different methods are available to do this, but we know very little about their concrete impact on the tradeoff between accuracy and energy efficiency, as these methods also consume energy themselves. To address this, we therefore conducted a controlled experiment to study the accuracy vs. energy efficiency tradeoff of seven common methods for concept drift detection. We used five synthetic datasets, each in a version with abrupt and one with gradual drift, and trained six different ML models as base classifiers. Based on a full factorial design, we tested 420 combinations (7 drift detectors * 5 datasets * 2 types of drift * 6 base classifiers) and compared energy consumption and drift detection accuracy. Our results indicate that there are three types of detectors: a) detectors that sacrifice energy efficiency for detection accuracy (KSWIN), b) balanced detectors that consume low to medium energy with good accuracy (HDDM_W, ADWIN), and c) detectors that consume very little energy but are unusable in practice due to very poor accuracy (HDDM_A, PageHinkley, DDM, EDDM). By providing rich evidence for this energy efficiency tactic, our findings support ML practitioners in choosing the best suited method of concept drift detection for their ML-enabled systems.
A Synthesis of Green Architectural Tactics for ML-Enabled Systems
Dec 15, 2023The rapid adoption of artificial intelligence (AI) and machine learning (ML) has generated growing interest in understanding their environmental impact and the challenges associated with designing environmentally friendly ML-enabled systems. While Green AI research, i.e., research that tries to minimize the energy footprint of AI, is receiving increasing attention, very few concrete guidelines are available on how ML-enabled systems can be designed to be more environmentally sustainable. In this paper, we provide a catalog of 30 green architectural tactics for ML-enabled systems to fill this gap. An architectural tactic is a high-level design technique to improve software quality, in our case environmental sustainability. We derived the tactics from the analysis of 51 peer-reviewed publications that primarily explore Green AI, and validated them using a focus group approach with three experts. The 30 tactics we identified are aimed to serve as an initial reference guide for further exploration into Green AI from a software engineering perspective, and assist in designing sustainable ML-enabled systems. To enhance transparency and facilitate their widespread use and extension, we make the tactics available online in easily consumable formats. Wide-spread adoption of these tactics has the potential to substantially reduce the societal impact of ML-enabled systems regarding their energy and carbon footprint.
Designing Internet of Behaviors Systems
Jan 06, 2022



The Internet of Behaviors (IoB) puts human behavior at the core of engineering intelligent connected systems. IoB links the digital world to human behavior to establish human-driven design, development, and adaptation processes. This paper defines the novel concept by an IoB model based on a collective effort interacting with software engineers, human-computer interaction scientists, social scientists, and cognitive science communities. The model for IoB is created based on an exploratory study that synthesizes state-of-the-art analysis and experts interviews. The architecture of a real industry 4.0 manufacturing infrastructure helps to explain the IoB model and it's application. The conceptual model was used to successfully implement a socio-technical infrastructure for a crowd monitoring and queue management system for the Uffizi Galleries, Florence, Italy. The experiment, which started in the fall of 2016 and was operational in the fall of 2018, used a data-driven approach to feed the system with real-time sensory data. It also incorporated prediction models on visitors' mobility behavior. The system's main objective was to capture human behavior, model it, and build a mechanism that considers changes, adapts in real-time, and continuously learns from repetitive behaviors. In addition to the conceptual model and the real-life evaluation, this paper provides recommendations from experts and gives future directions for IoB to become a significant technological advancement in the coming few years.
Software Architecture for ML-based Systems: What Exists and What Lies Ahead
Mar 16, 2021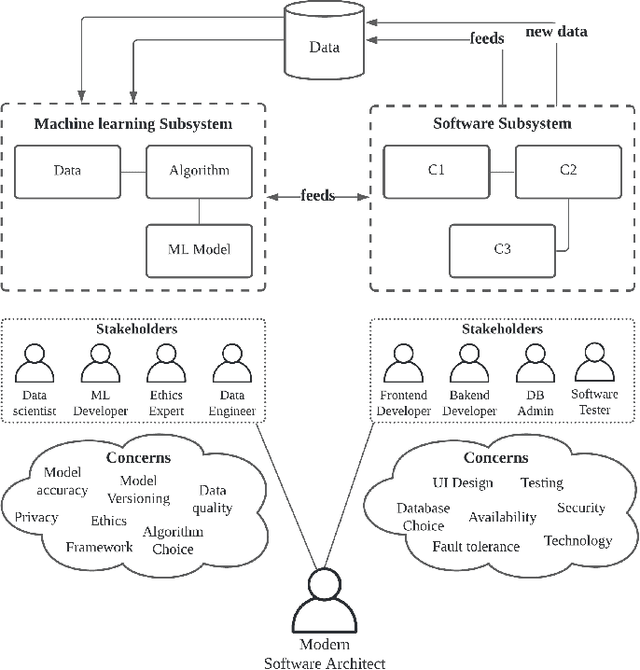
The increasing usage of machine learning (ML) coupled with the software architectural challenges of the modern era has resulted in two broad research areas: i) software architecture for ML-based systems, which focuses on developing architectural techniques for better developing ML-based software systems, and ii) ML for software architectures, which focuses on developing ML techniques to better architect traditional software systems. In this work, we focus on the former side of the spectrum with a goal to highlight the different architecting practices that exist in the current scenario for architecting ML-based software systems. We identify four key areas of software architecture that need the attention of both the ML and software practitioners to better define a standard set of practices for architecting ML-based software systems. We base these areas in light of our experience in architecting an ML-based software system for solving queuing challenges in one of the largest museums in Italy.