 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Model for Machine Learning Components
Feb 04, 2026Despite increased adoption and advances in machine learning (ML), there are studies showing that many ML prototypes do not reach the production stage and that testing is still largely limited to testing model properties, such as model performance, without considering requirements derived from the system it will be a part of, such as throughput, resource consumption, or robustness. This limited view of testing leads to failures in model integration, deployment, and operations. In traditional software development, quality models such as ISO 25010 provide a widely used structured framework to assess software quality, define quality requirements, and provide a common language for communication with stakeholders. A newer standard, ISO 25059, defines a more specific quality model for AI systems. However, a problem with this standard is that it combines system attributes with ML component attributes, which is not helpful for a model developer, as many system attributes cannot be assessed at the component level. In this paper, we present a quality model for ML components that serves as a guide for requirements elicitation and negotiation and provides a common vocabulary for ML component developers and system stakeholders to agree on and define system-derived requirements and focus their testing efforts accordingly. The quality model was validated through a survey in which the participants agreed with its relevance and value. The quality model has been successfully integrated into an open-source tool for ML component testing and evaluation demonstrating its practical application.
Using Quality Attribute Scenarios for ML Model Test Case Generation
Jun 12, 2024Testing of machine learning (ML) models is a known challenge identified by researchers and practitioners alike. Unfortunately, current practice for ML model testing prioritizes testing for model performance, while often neglecting the requirements and constraints of the ML-enabled system that integrates the model. This limited view of testing leads to failures during integration, deployment, and operations, contributing to the difficulties of moving models from development to production. This paper presents an approach based on quality attribute (QA) scenarios to elicit and define system- and model-relevant test cases for ML models. The QA-based approach described in this paper has been integrated into MLTE, a process and tool to support ML model test and evaluation. Feedback from users of MLTE highlights its effectiveness in testing beyond model performance and identifying failures early in the development process.
A Synthesis of Green Architectural Tactics for ML-Enabled Systems
Dec 15, 2023The rapid adoption of artificial intelligence (AI) and machine learning (ML) has generated growing interest in understanding their environmental impact and the challenges associated with designing environmentally friendly ML-enabled systems. While Green AI research, i.e., research that tries to minimize the energy footprint of AI, is receiving increasing attention, very few concrete guidelines are available on how ML-enabled systems can be designed to be more environmentally sustainable. In this paper, we provide a catalog of 30 green architectural tactics for ML-enabled systems to fill this gap. An architectural tactic is a high-level design technique to improve software quality, in our case environmental sustainability. We derived the tactics from the analysis of 51 peer-reviewed publications that primarily explore Green AI, and validated them using a focus group approach with three experts. The 30 tactics we identified are aimed to serve as an initial reference guide for further exploration into Green AI from a software engineering perspective, and assist in designing sustainable ML-enabled systems. To enhance transparency and facilitate their widespread use and extension, we make the tactics available online in easily consumable formats. Wide-spread adoption of these tactics has the potential to substantially reduce the societal impact of ML-enabled systems regarding their energy and carbon footprint.
Characterizing and Detecting Mismatch in Machine-Learning-Enabled Systems
Mar 25, 2021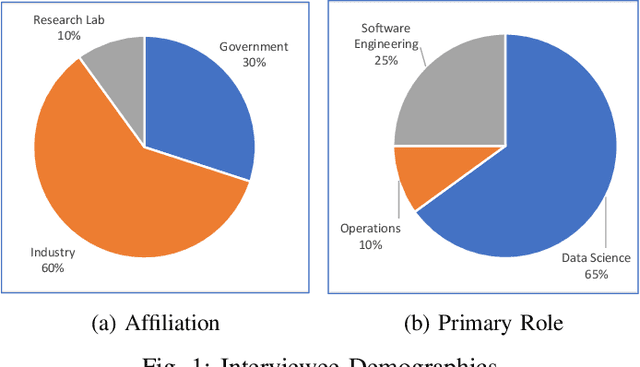
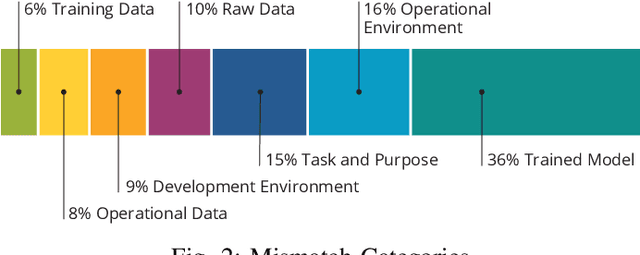
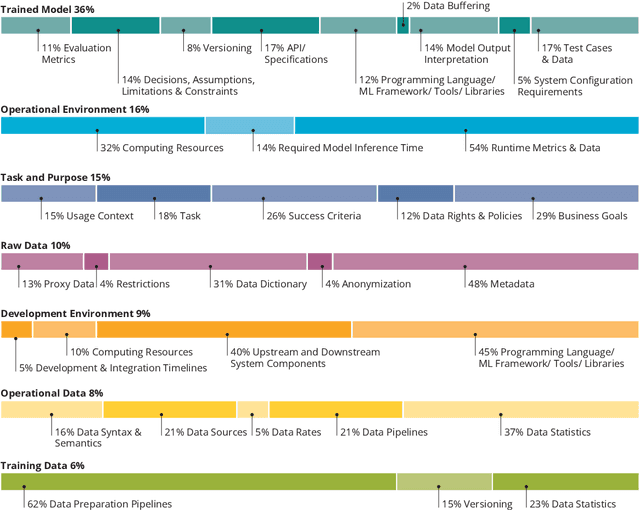
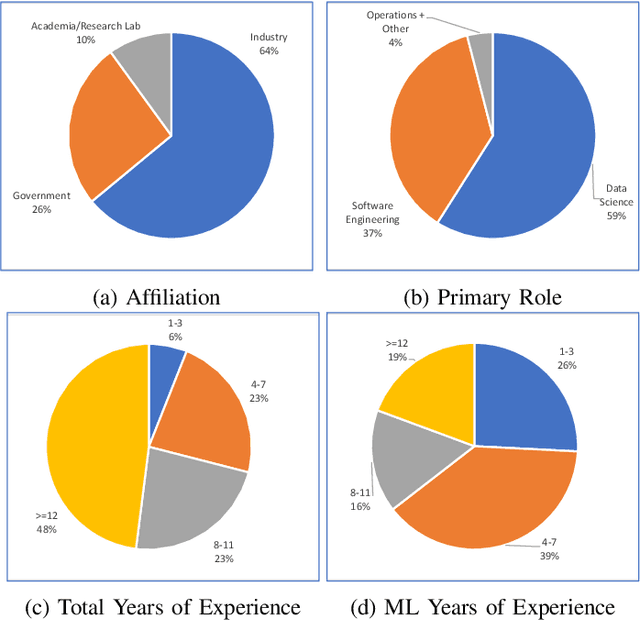
Increasing availability of machine learning (ML) frameworks and tools, as well as their promise to improve solutions to data-driven decision problems, has resulted in popularity of using ML techniques in software systems. However, end-to-end development of ML-enabled systems, as well as their seamless deployment and operations, remain a challenge. One reason is that development and deployment of ML-enabled systems involves three distinct workflows, perspectives, and roles, which include data science, software engineering, and operations. These three distinct perspectives, when misaligned due to incorrect assumptions, cause ML mismatches which can result in failed systems. We conducted an interview and survey study where we collected and validated common types of mismatches that occur in end-to-end development of ML-enabled systems. Our analysis shows that how each role prioritizes the importance of relevant mismatches varies, potentially contributing to these mismatched assumptions. In addition, the mismatch categories we identified can be specified as machine readable descriptors contributing to improved ML-enabled system development. In this paper, we report our findings and their implications for improving end-to-end ML-enabled system development.