 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Model for Machine Learning Components
Feb 04, 2026Despite increased adoption and advances in machine learning (ML), there are studies showing that many ML prototypes do not reach the production stage and that testing is still largely limited to testing model properties, such as model performance, without considering requirements derived from the system it will be a part of, such as throughput, resource consumption, or robustness. This limited view of testing leads to failures in model integration, deployment, and operations. In traditional software development, quality models such as ISO 25010 provide a widely used structured framework to assess software quality, define quality requirements, and provide a common language for communication with stakeholders. A newer standard, ISO 25059, defines a more specific quality model for AI systems. However, a problem with this standard is that it combines system attributes with ML component attributes, which is not helpful for a model developer, as many system attributes cannot be assessed at the component level. In this paper, we present a quality model for ML components that serves as a guide for requirements elicitation and negotiation and provides a common vocabulary for ML component developers and system stakeholders to agree on and define system-derived requirements and focus their testing efforts accordingly. The quality model was validated through a survey in which the participants agreed with its relevance and value. The quality model has been successfully integrated into an open-source tool for ML component testing and evaluation demonstrating its practical application.
What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing
Sep 14, 2024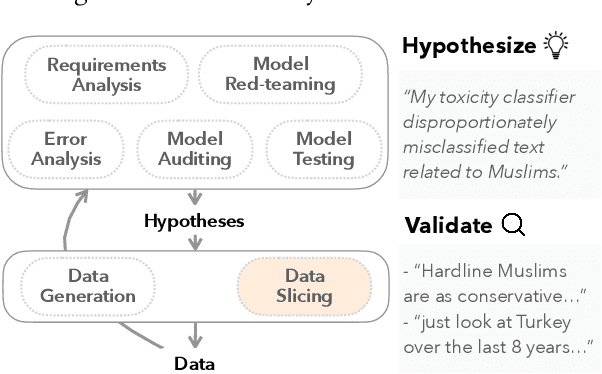
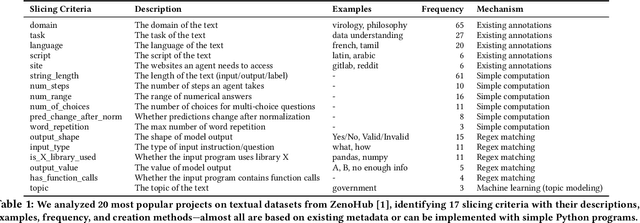

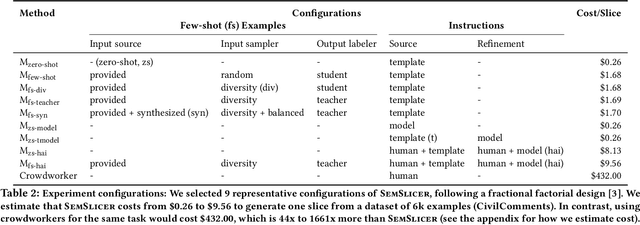
Machine learning models make mistakes, yet sometimes it is difficult to identify the systematic problems behind the mistakes. Practitioners engage in various activities, including error analysis, testing, auditing, and red-teaming, to form hypotheses of what can go (or has gone) wrong with their models. To validate these hypotheses, practitioners employ data slicing to identify relevant examples. However, traditional data slicing is limited by available features and programmatic slicing functions. In this work, we propose SemSlicer, a framework that supports semantic data slicing, which identifies a semantically coherent slice, without the need for existing features. SemSlicer uses Large Language Models to annotate datasets and generate slices from any user-defined slicing criteria. We show that SemSlicer generates accurate slices with low cost, allows flexible trade-offs between different design dimensions, reliably identifies under-performing data slices, and helps practitioners identify useful data slices that reflect systematic problems.
Using Quality Attribute Scenarios for ML Model Test Case Generation
Jun 12, 2024Testing of machine learning (ML) models is a known challenge identified by researchers and practitioners alike. Unfortunately, current practice for ML model testing prioritizes testing for model performance, while often neglecting the requirements and constraints of the ML-enabled system that integrates the model. This limited view of testing leads to failures during integration, deployment, and operations, contributing to the difficulties of moving models from development to production. This paper presents an approach based on quality attribute (QA) scenarios to elicit and define system- and model-relevant test cases for ML models. The QA-based approach described in this paper has been integrated into MLTE, a process and tool to support ML model test and evaluation. Feedback from users of MLTE highlights its effectiveness in testing beyond model performance and identifying failures early in the development process.
Beyond Testers' Biases: Guiding Model Testing with Knowledge Bases using LLMs
Oct 14, 2023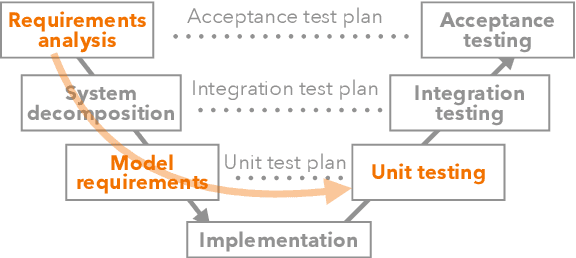
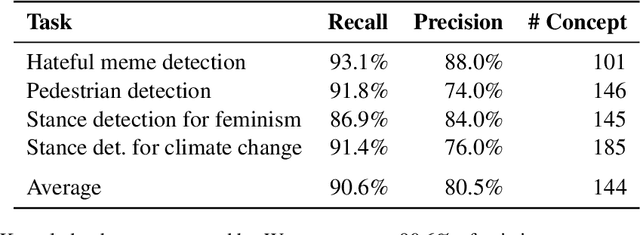
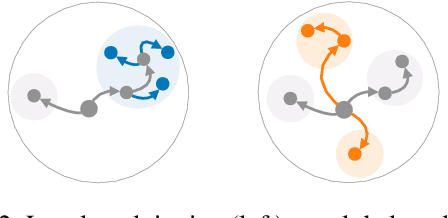

Current model testing work has mostly focused on creating test cases. Identifying what to test is a step that is largely ignored and poorly supported. We propose Weaver, an interactive tool that supports requirements elicitation for guiding model testing. Weaver uses large language models to generate knowledge bases and recommends concepts from them interactively, allowing testers to elicit requirements for further testing. Weaver provides rich external knowledge to testers and encourages testers to systematically explore diverse concepts beyond their own biases. In a user study, we show that both NLP experts and non-experts identified more, as well as more diverse concepts worth testing when using Weaver. Collectively, they found more than 200 failing test cases for stance detection with zero-shot ChatGPT. Our case studies further show that Weaver can help practitioners test models in real-world settings, where developers define more nuanced application scenarios (e.g., code understanding and transcript summarization) using LLMs.
MLTEing Models: Negotiating, Evaluating, and Documenting Model and System Qualities
Mar 03, 2023
Many organizations seek to ensure that machine learning (ML) and artificial intelligence (AI) systems work as intended in production but currently do not have a cohesive methodology in place to do so. To fill this gap, we propose MLTE (Machine Learning Test and Evaluation, colloquially referred to as "melt"), a framework and implementation to evaluate ML models and systems. The framework compiles state-of-the-art evaluation techniques into an organizational process for interdisciplinary teams, including model developers, software engineers, system owners, and other stakeholders. MLTE tooling supports this process by providing a domain-specific language that teams can use to express model requirements, an infrastructure to define, generate, and collect ML evaluation metrics, and the means to communicate results.
Capabilities for Better ML Engineering
Nov 11, 2022
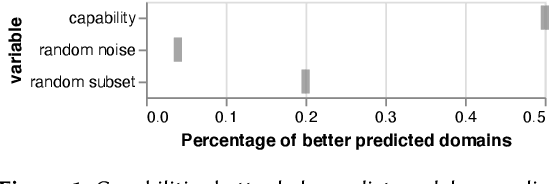
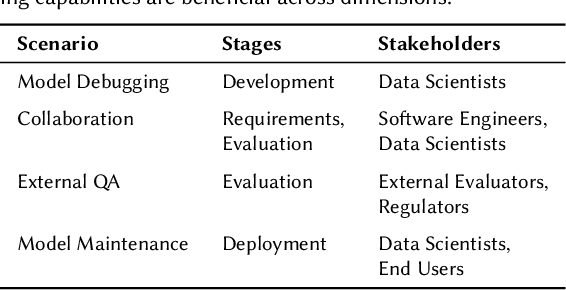
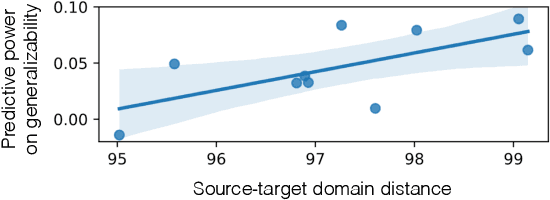
In spite of machine learning's rapid growth, its engineering support is scattered in many forms, and tends to favor certain engineering stages, stakeholders, and evaluation preferences. We envision a capability-based framework, which uses fine-grained specifications for ML model behaviors to unite existing efforts towards better ML engineering. We use concrete scenarios (model design, debugging, and maintenance) to articulate capabilities' broad applications across various different dimensions, and their impact on building safer, more generalizable and more trustworthy models that reflect human needs. Through preliminary experiments, we show capabilities' potential for reflecting model generalizability, which can provide guidance for ML engineering process. We discuss challenges and opportunities for capabilities' integration into ML engineering.
Characterizing and Detecting Mismatch in Machine-Learning-Enabled Systems
Mar 25, 2021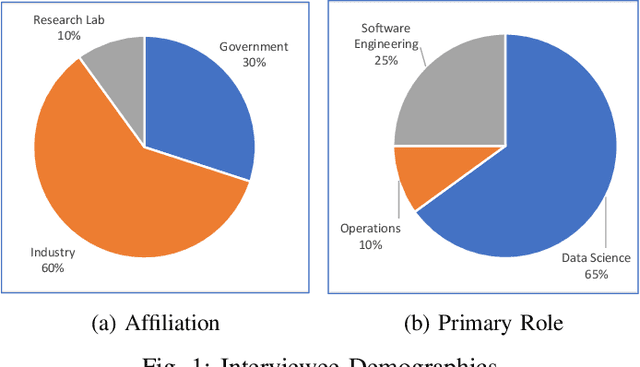
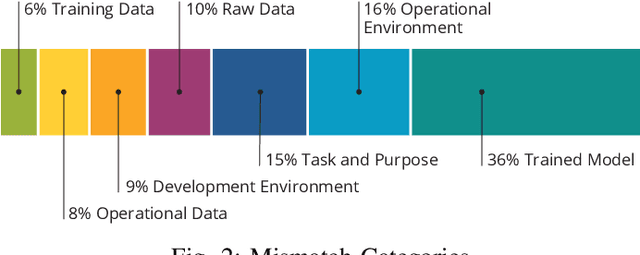
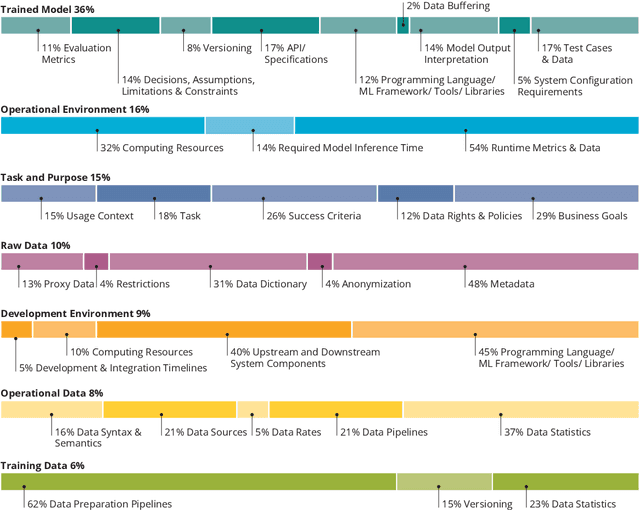
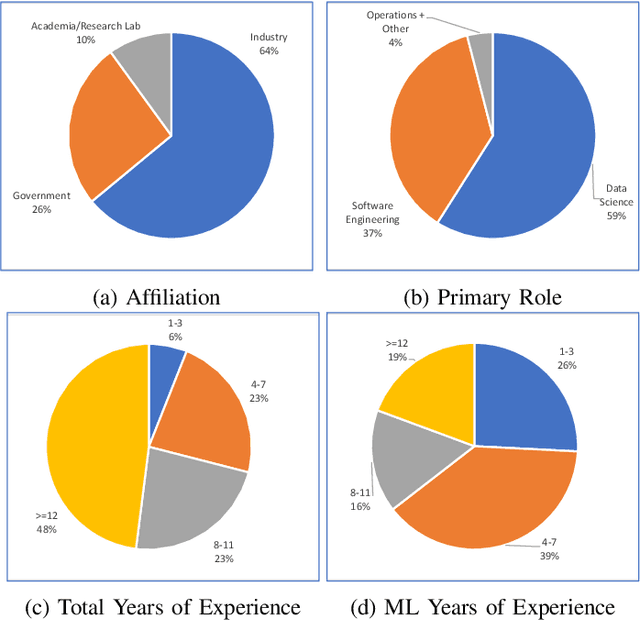
Increasing availability of machine learning (ML) frameworks and tools, as well as their promise to improve solutions to data-driven decision problems, has resulted in popularity of using ML techniques in software systems. However, end-to-end development of ML-enabled systems, as well as their seamless deployment and operations, remain a challenge. One reason is that development and deployment of ML-enabled systems involves three distinct workflows, perspectives, and roles, which include data science, software engineering, and operations. These three distinct perspectives, when misaligned due to incorrect assumptions, cause ML mismatches which can result in failed systems. We conducted an interview and survey study where we collected and validated common types of mismatches that occur in end-to-end development of ML-enabled systems. Our analysis shows that how each role prioritizes the importance of relevant mismatches varies, potentially contributing to these mismatched assumptions. In addition, the mismatch categories we identified can be specified as machine readable descriptors contributing to improved ML-enabled system development. In this paper, we report our findings and their implications for improving end-to-end ML-enabled system development.
Component Mismatches Are a Critical Bottleneck to Fielding AI-Enabled Systems in the Public Sector
Oct 14, 2019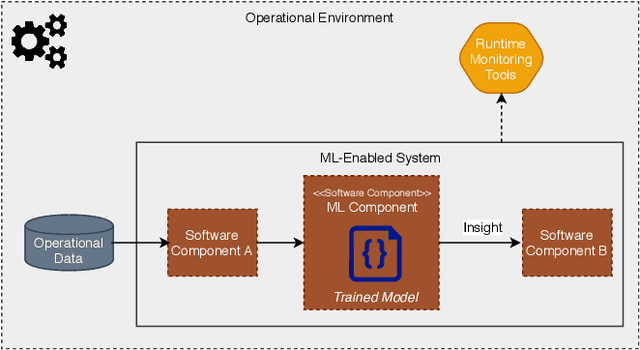
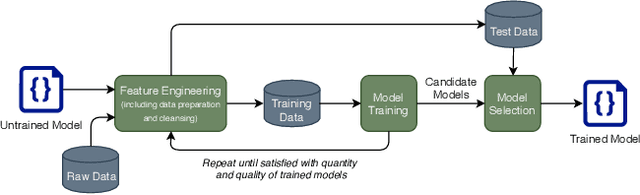
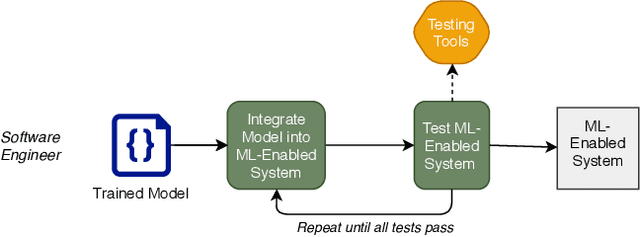
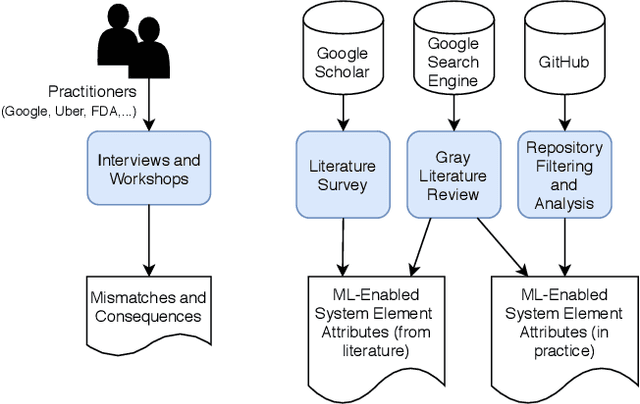
The use of machine learning or artificial intelligence (ML/AI) holds substantial potential toward improving many functions and needs of the public sector. In practice however, integrating ML/AI components into public sector applications is severely limited not only by the fragility of these components and their algorithms, but also because of mismatches between components of ML-enabled systems. For example, if an ML model is trained on data that is different from data in the operational environment, field performance of the ML component will be dramatically reduced. Separate from software engineering considerations, the expertise needed to field an ML/AI component within a system frequently comes from outside software engineering. As a result, assumptions and even descriptive language used by practitioners from these different disciplines can exacerbate other challenges to integrating ML/AI components into larger systems. We are investigating classes of mismatches in ML/AI systems integration, to identify the implicit assumptions made by practitioners in different fields (data scientists, software engineers, operations staff) and find ways to communicate the appropriate information explicitly. We will discuss a few categories of mismatch, and provide examples from each class. To enable ML/AI components to be fielded in a meaningful way, we will need to understand the mismatches that exist and develop practices to mitigate the impacts of these mismatches.