 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Testers' Biases: Guiding Model Testing with Knowledge Bases using LLMs
Paper and Code
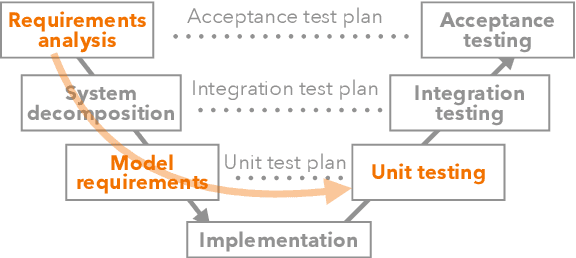
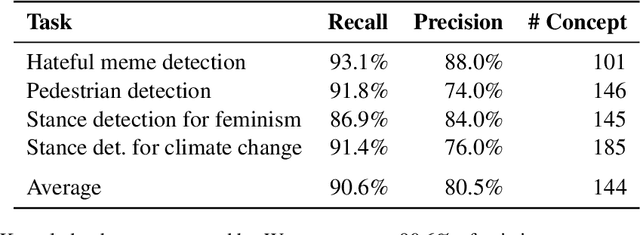
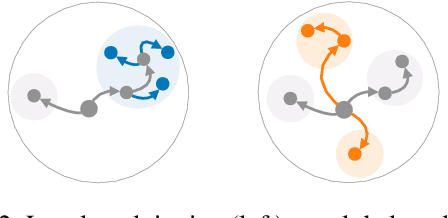

Current model testing work has mostly focused on creating test cases. Identifying what to test is a step that is largely ignored and poorly supported. We propose Weaver, an interactive tool that supports requirements elicitation for guiding model testing. Weaver uses large language models to generate knowledge bases and recommends concepts from them interactively, allowing testers to elicit requirements for further testing. Weaver provides rich external knowledge to testers and encourages testers to systematically explore diverse concepts beyond their own biases. In a user study, we show that both NLP experts and non-experts identified more, as well as more diverse concepts worth testing when using Weaver. Collectively, they found more than 200 failing test cases for stance detection with zero-shot ChatGPT. Our case studies further show that Weaver can help practitioners test models in real-world settings, where developers define more nuanced application scenarios (e.g., code understanding and transcript summarization) using LLMs.