 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Model for Machine Learning Components
Feb 04, 2026Despite increased adoption and advances in machine learning (ML), there are studies showing that many ML prototypes do not reach the production stage and that testing is still largely limited to testing model properties, such as model performance, without considering requirements derived from the system it will be a part of, such as throughput, resource consumption, or robustness. This limited view of testing leads to failures in model integration, deployment, and operations. In traditional software development, quality models such as ISO 25010 provide a widely used structured framework to assess software quality, define quality requirements, and provide a common language for communication with stakeholders. A newer standard, ISO 25059, defines a more specific quality model for AI systems. However, a problem with this standard is that it combines system attributes with ML component attributes, which is not helpful for a model developer, as many system attributes cannot be assessed at the component level. In this paper, we present a quality model for ML components that serves as a guide for requirements elicitation and negotiation and provides a common vocabulary for ML component developers and system stakeholders to agree on and define system-derived requirements and focus their testing efforts accordingly. The quality model was validated through a survey in which the participants agreed with its relevance and value. The quality model has been successfully integrated into an open-source tool for ML component testing and evaluation demonstrating its practical application.
Using Quality Attribute Scenarios for ML Model Test Case Generation
Jun 12, 2024Testing of machine learning (ML) models is a known challenge identified by researchers and practitioners alike. Unfortunately, current practice for ML model testing prioritizes testing for model performance, while often neglecting the requirements and constraints of the ML-enabled system that integrates the model. This limited view of testing leads to failures during integration, deployment, and operations, contributing to the difficulties of moving models from development to production. This paper presents an approach based on quality attribute (QA) scenarios to elicit and define system- and model-relevant test cases for ML models. The QA-based approach described in this paper has been integrated into MLTE, a process and tool to support ML model test and evaluation. Feedback from users of MLTE highlights its effectiveness in testing beyond model performance and identifying failures early in the development process.
Beyond Testers' Biases: Guiding Model Testing with Knowledge Bases using LLMs
Oct 14, 2023
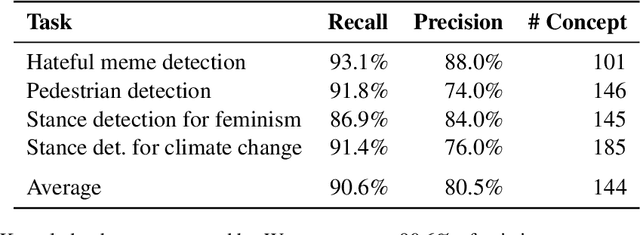

Current model testing work has mostly focused on creating test cases. Identifying what to test is a step that is largely ignored and poorly supported. We propose Weaver, an interactive tool that supports requirements elicitation for guiding model testing. Weaver uses large language models to generate knowledge bases and recommends concepts from them interactively, allowing testers to elicit requirements for further testing. Weaver provides rich external knowledge to testers and encourages testers to systematically explore diverse concepts beyond their own biases. In a user study, we show that both NLP experts and non-experts identified more, as well as more diverse concepts worth testing when using Weaver. Collectively, they found more than 200 failing test cases for stance detection with zero-shot ChatGPT. Our case studies further show that Weaver can help practitioners test models in real-world settings, where developers define more nuanced application scenarios (e.g., code understanding and transcript summarization) using LLMs.
Capabilities for Better ML Engineering
Nov 11, 2022
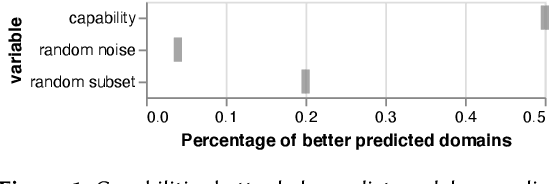
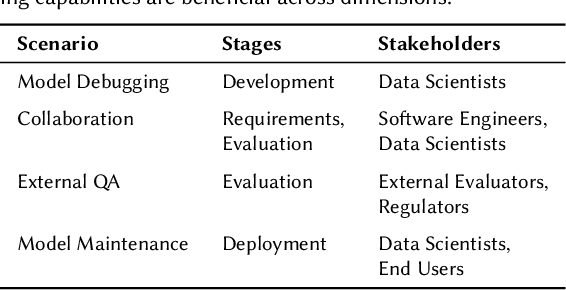
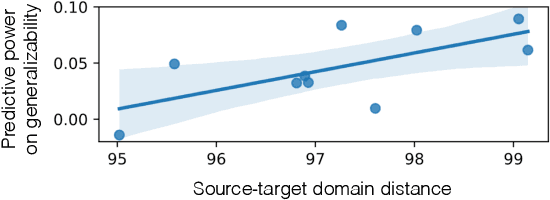
In spite of machine learning's rapid growth, its engineering support is scattered in many forms, and tends to favor certain engineering stages, stakeholders, and evaluation preferences. We envision a capability-based framework, which uses fine-grained specifications for ML model behaviors to unite existing efforts towards better ML engineering. We use concrete scenarios (model design, debugging, and maintenance) to articulate capabilities' broad applications across various different dimensions, and their impact on building safer, more generalizable and more trustworthy models that reflect human needs. Through preliminary experiments, we show capabilities' potential for reflecting model generalizability, which can provide guidance for ML engineering process. We discuss challenges and opportunities for capabilities' integration into ML engineering.