 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes AI-Assisted Coding Deliver? A Difference-in-Differences Study of Cursor's Impact on Software Projects
Nov 13, 2025Large language models (LLMs) have demonstrated the promise to revolutionize the field of software engineering. Among other things, LLM agents are rapidly gaining momentum in their application to software development, with practitioners claiming a multifold productivity increase after adoption. Yet, empirical evidence is lacking around these claims. In this paper, we estimate the causal effect of adopting a widely popular LLM agent assistant, namely Cursor, on development velocity and software quality. The estimation is enabled by a state-of-the-art difference-in-differences design comparing Cursor-adopting GitHub projects with a matched control group of similar GitHub projects that do not use Cursor. We find that the adoption of Cursor leads to a significant, large, but transient increase in project-level development velocity, along with a significant and persistent increase in static analysis warnings and code complexity. Further panel generalized method of moments estimation reveals that the increase in static analysis warnings and code complexity acts as a major factor causing long-term velocity slowdown. Our study carries implications for software engineering practitioners, LLM agent assistant designers, and researchers.
Speed at the Cost of Quality? The Impact of LLM Agent Assistance on Software Development
Nov 06, 2025Large language models (LLMs) have demonstrated the promise to revolutionize the field of software engineering. Among other things, LLM agents are rapidly gaining momentum in their application to software development, with practitioners claiming a multifold productivity increase after adoption. Yet, empirical evidence is lacking around these claims. In this paper, we estimate the causal effect of adopting a widely popular LLM agent assistant, namely Cursor, on development velocity and software quality. The estimation is enabled by a state-of-the-art difference-in-differences design comparing Cursor-adopting GitHub projects with a matched control group of similar GitHub projects that do not use Cursor. We find that the adoption of Cursor leads to a significant, large, but transient increase in project-level development velocity, along with a significant and persistent increase in static analysis warnings and code complexity. Further panel generalized method of moments estimation reveals that the increase in static analysis warnings and code complexity acts as a major factor causing long-term velocity slowdown. Our study carries implications for software engineering practitioners, LLM agent assistant designers, and researchers.
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
May 19, 2025Building LLM-powered software requires developers to communicate their requirements through natural language, but developer prompts are frequently underspecified, failing to fully capture many user-important requirements. In this paper, we present an in-depth analysis of prompt underspecification, showing that while LLMs can often (41.1%) guess unspecified requirements by default, such behavior is less robust: Underspecified prompts are 2x more likely to regress over model or prompt changes, sometimes with accuracy drops by more than 20%. We then demonstrate that simply adding more requirements to a prompt does not reliably improve performance, due to LLMs' limited instruction-following capabilities and competing constraints, and standard prompt optimizers do not offer much help. To address this, we introduce novel requirements-aware prompt optimization mechanisms that can improve performance by 4.8% on average over baselines that naively specify everything in the prompt. Beyond prompt optimization, we envision that effectively managing prompt underspecification requires a broader process, including proactive requirements discovery, evaluation, and monitoring.
From Hazard Identification to Controller Design: Proactive and LLM-Supported Safety Engineering for ML-Powered Systems
Feb 11, 2025



Machine learning (ML) components are increasingly integrated into software products, yet their complexity and inherent uncertainty often lead to unintended and hazardous consequences, both for individuals and society at large. Despite these risks, practitioners seldom adopt proactive approaches to anticipate and mitigate hazards before they occur. Traditional safety engineering approaches, such as Failure Mode and Effects Analysis (FMEA) and System Theoretic Process Analysis (STPA), offer systematic frameworks for early risk identification but are rarely adopted. This position paper advocates for integrating hazard analysis into the development of any ML-powered software product and calls for greater support to make this process accessible to developers. By using large language models (LLMs) to partially automate a modified STPA process with human oversight at critical steps, we expect to address two key challenges: the heavy dependency on highly experienced safety engineering experts, and the time-consuming, labor-intensive nature of traditional hazard analysis, which often impedes its integration into real-world development workflows. We illustrate our approach with a running example, demonstrating that many seemingly unanticipated issues can, in fact, be anticipated.
FairSense: Long-Term Fairness Analysis of ML-Enabled Systems
Jan 03, 2025

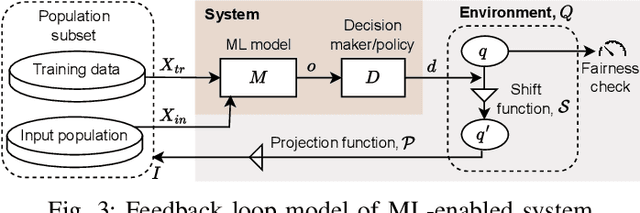
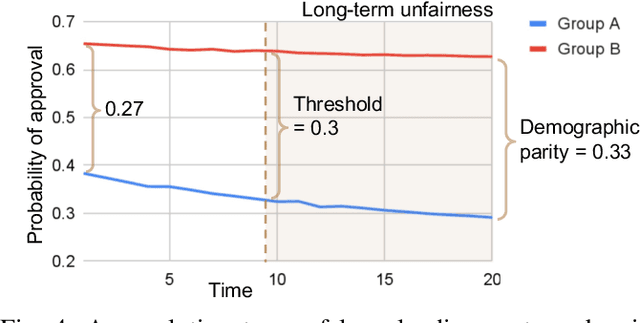
Algorithmic fairness of machine learning (ML) models has raised significant concern in the recent years. Many testing, verification, and bias mitigation techniques have been proposed to identify and reduce fairness issues in ML models. The existing methods are model-centric and designed to detect fairness issues under static settings. However, many ML-enabled systems operate in a dynamic environment where the predictive decisions made by the system impact the environment, which in turn affects future decision-making. Such a self-reinforcing feedback loop can cause fairness violations in the long term, even if the immediate outcomes are fair. In this paper, we propose a simulation-based framework called FairSense to detect and analyze long-term unfairness in ML-enabled systems. Given a fairness requirement, FairSense performs Monte-Carlo simulation to enumerate evolution traces for each system configuration. Then, FairSense performs sensitivity analysis on the space of possible configurations to understand the impact of design options and environmental factors on the long-term fairness of the system. We demonstrate FairSense's potential utility through three real-world case studies: Loan lending, opioids risk scoring, and predictive policing.
Orbit: A Framework for Designing and Evaluating Multi-objective Rankers
Nov 07, 2024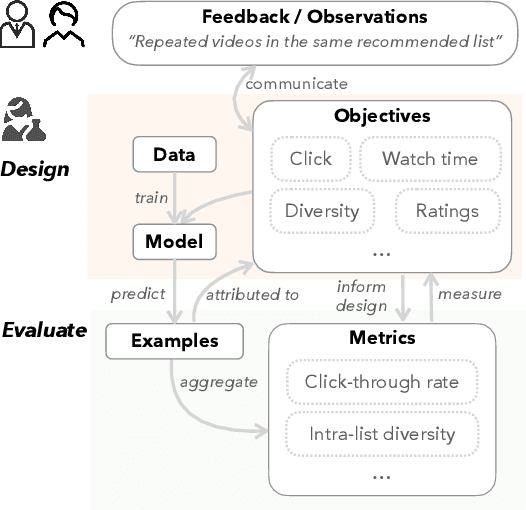
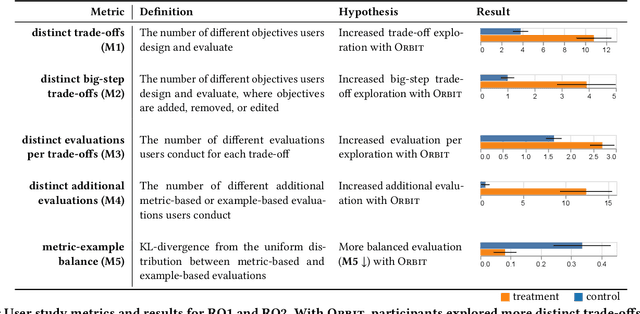
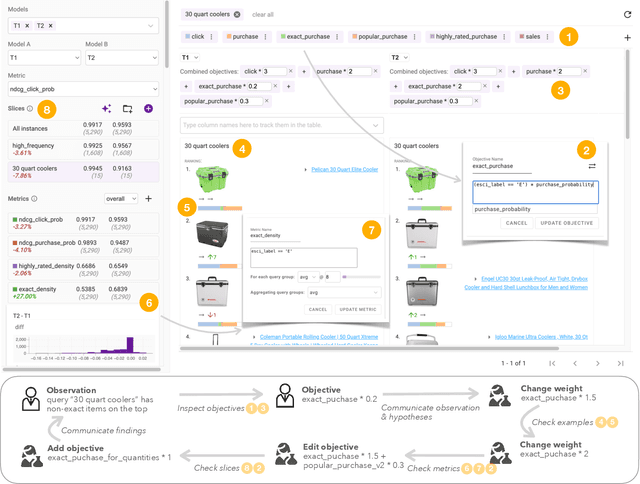

Machine learning in production needs to balance multiple objectives: This is particularly evident in ranking or recommendation models, where conflicting objectives such as user engagement, satisfaction, diversity, and novelty must be considered at the same time. However, designing multi-objective rankers is inherently a dynamic wicked problem -- there is no single optimal solution, and the needs evolve over time. Effective design requires collaboration between cross-functional teams and careful analysis of a wide range of information. In this work, we introduce Orbit, a conceptual framework for Objective-centric Ranker Building and Iteration. The framework places objectives at the center of the design process, to serve as boundary objects for communication and guide practitioners for design and evaluation. We implement Orbit as an interactive system, which enables stakeholders to interact with objective spaces directly and supports real-time exploration and evaluation of design trade-offs. We evaluate Orbit through a user study involving twelve industry practitioners, showing that it supports efficient design space exploration, leads to more informed decision-making, and enhances awareness of the inherent trade-offs of multiple objectives. Orbit (1) opens up new opportunities of an objective-centric design process for any multi-objective ML models, as well as (2) sheds light on future designs that push practitioners to go beyond a narrow metric-centric or example-centric mindset.
Beyond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products
Oct 15, 2024
Large Language Models (LLMs) are increasingly embedded into software products across diverse industries, enhancing user experiences, but at the same time introducing numerous challenges for developers. Unique characteristics of LLMs force developers, who are accustomed to traditional software development and evaluation, out of their comfort zones as the LLM components shatter standard assumptions about software systems. This study explores the emerging solutions that software developers are adopting to navigate the encountered challenges. Leveraging a mixed-method research, including 26 interviews and a survey with 332 responses, the study identifies 19 emerging solutions regarding quality assurance that practitioners across several product teams at Microsoft are exploring. The findings provide valuable insights that can guide the development and evaluation of LLM-based products more broadly in the face of these challenges.
What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing
Sep 14, 2024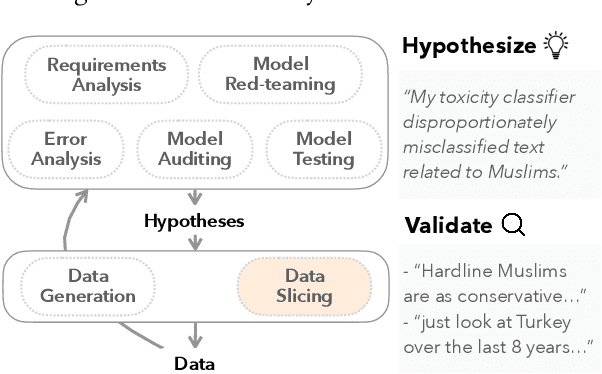
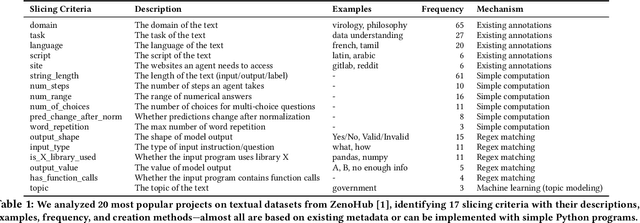

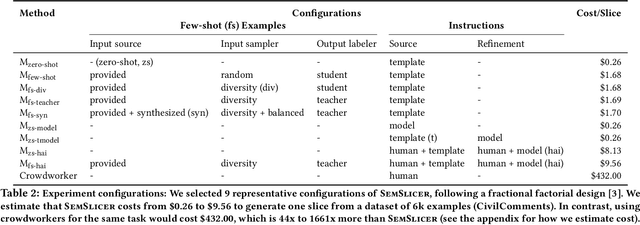
Machine learning models make mistakes, yet sometimes it is difficult to identify the systematic problems behind the mistakes. Practitioners engage in various activities, including error analysis, testing, auditing, and red-teaming, to form hypotheses of what can go (or has gone) wrong with their models. To validate these hypotheses, practitioners employ data slicing to identify relevant examples. However, traditional data slicing is limited by available features and programmatic slicing functions. In this work, we propose SemSlicer, a framework that supports semantic data slicing, which identifies a semantically coherent slice, without the need for existing features. SemSlicer uses Large Language Models to annotate datasets and generate slices from any user-defined slicing criteria. We show that SemSlicer generates accurate slices with low cost, allows flexible trade-offs between different design dimensions, reliably identifies under-performing data slices, and helps practitioners identify useful data slices that reflect systematic problems.
(Why) Is My Prompt Getting Worse? Rethinking Regression Testing for Evolving LLM APIs
Nov 18, 2023Large Language Models (LLMs) are increasingly integrated into software applications. Downstream application developers often access LLMs through APIs provided as a service. However, LLM APIs are often updated silently and scheduled to be deprecated, forcing users to continuously adapt to evolving models. This can cause performance regression and affect prompt design choices, as evidenced by our case study on toxicity detection. Based on our case study, we emphasize the need for and re-examine the concept of regression testing for evolving LLM APIs. We argue that regression testing LLMs requires fundamental changes to traditional testing approaches, due to different correctness notions, prompting brittleness, and non-determinism in LLM APIs.
Beyond Testers' Biases: Guiding Model Testing with Knowledge Bases using LLMs
Oct 14, 2023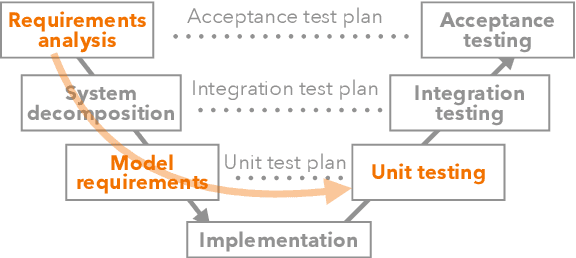
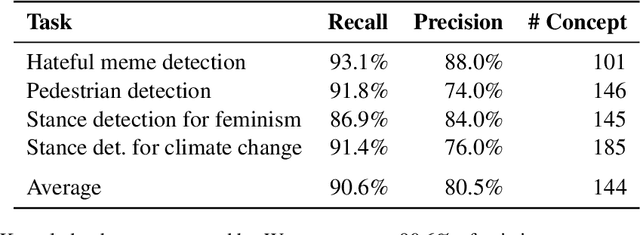

Current model testing work has mostly focused on creating test cases. Identifying what to test is a step that is largely ignored and poorly supported. We propose Weaver, an interactive tool that supports requirements elicitation for guiding model testing. Weaver uses large language models to generate knowledge bases and recommends concepts from them interactively, allowing testers to elicit requirements for further testing. Weaver provides rich external knowledge to testers and encourages testers to systematically explore diverse concepts beyond their own biases. In a user study, we show that both NLP experts and non-experts identified more, as well as more diverse concepts worth testing when using Weaver. Collectively, they found more than 200 failing test cases for stance detection with zero-shot ChatGPT. Our case studies further show that Weaver can help practitioners test models in real-world settings, where developers define more nuanced application scenarios (e.g., code understanding and transcript summarization) using LLMs.