 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletion $ eq$ Collaboration: Scaling Collaborative Effort with Agents
Oct 30, 2025Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent's utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
The Ramon Llull's Thinking Machine for Automated Ideation
Aug 28, 2025This paper revisits Ramon Llull's Ars combinatoria - a medieval framework for generating knowledge through symbolic recombination - as a conceptual foundation for building a modern Llull's thinking machine for research ideation. Our approach defines three compositional axes: Theme (e.g., efficiency, adaptivity), Domain (e.g., question answering, machine translation), and Method (e.g., adversarial training, linear attention). These elements represent high-level abstractions common in scientific work - motivations, problem settings, and technical approaches - and serve as building blocks for LLM-driven exploration. We mine elements from human experts or conference papers and show that prompting LLMs with curated combinations produces research ideas that are diverse, relevant, and grounded in current literature. This modern thinking machine offers a lightweight, interpretable tool for augmenting scientific creativity and suggests a path toward collaborative ideation between humans and AI.
Checklists Are Better Than Reward Models For Aligning Language Models
Jul 24, 2025



Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this -- typically using fixed criteria such as "helpfulness" and "harmfulness". In our work, we instead propose using flexible, instruction-specific criteria as a means of broadening the impact that reinforcement learning can have in eliciting instruction following. We propose "Reinforcement Learning from Checklist Feedback" (RLCF). From instructions, we extract checklists and evaluate how well responses satisfy each item - using both AI judges and specialized verifier programs - then combine these scores to compute rewards for RL. We compare RLCF with other alignment methods applied to a strong instruction following model (Qwen2.5-7B-Instruct) on five widely-studied benchmarks -- RLCF is the only method to improve performance on every benchmark, including a 4-point boost in hard satisfaction rate on FollowBench, a 6-point increase on InFoBench, and a 3-point rise in win rate on Arena-Hard. These results establish checklist feedback as a key tool for improving language models' support of queries that express a multitude of needs.
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
May 19, 2025Building LLM-powered software requires developers to communicate their requirements through natural language, but developer prompts are frequently underspecified, failing to fully capture many user-important requirements. In this paper, we present an in-depth analysis of prompt underspecification, showing that while LLMs can often (41.1%) guess unspecified requirements by default, such behavior is less robust: Underspecified prompts are 2x more likely to regress over model or prompt changes, sometimes with accuracy drops by more than 20%. We then demonstrate that simply adding more requirements to a prompt does not reliably improve performance, due to LLMs' limited instruction-following capabilities and competing constraints, and standard prompt optimizers do not offer much help. To address this, we introduce novel requirements-aware prompt optimization mechanisms that can improve performance by 4.8% on average over baselines that naively specify everything in the prompt. Beyond prompt optimization, we envision that effectively managing prompt underspecification requires a broader process, including proactive requirements discovery, evaluation, and monitoring.
Orbit: A Framework for Designing and Evaluating Multi-objective Rankers
Nov 07, 2024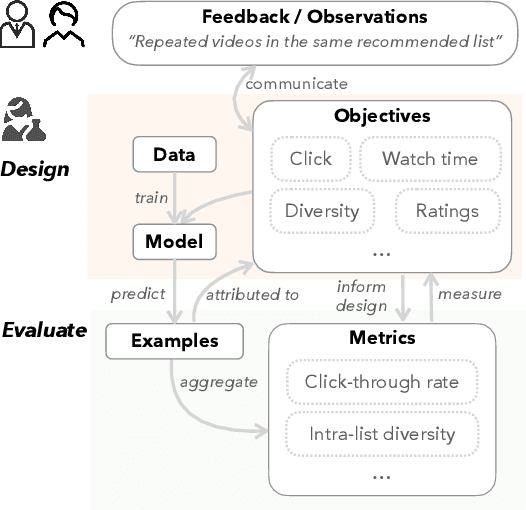
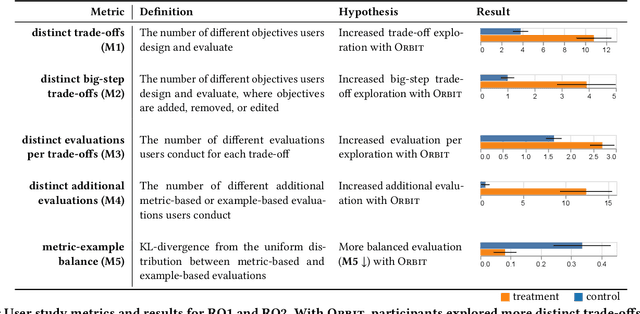
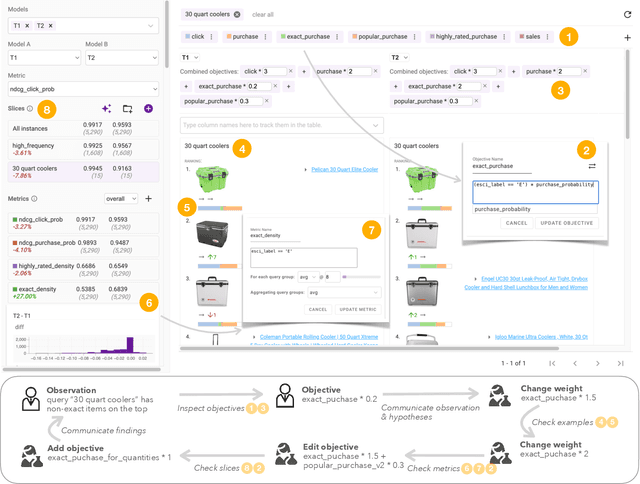

Machine learning in production needs to balance multiple objectives: This is particularly evident in ranking or recommendation models, where conflicting objectives such as user engagement, satisfaction, diversity, and novelty must be considered at the same time. However, designing multi-objective rankers is inherently a dynamic wicked problem -- there is no single optimal solution, and the needs evolve over time. Effective design requires collaboration between cross-functional teams and careful analysis of a wide range of information. In this work, we introduce Orbit, a conceptual framework for Objective-centric Ranker Building and Iteration. The framework places objectives at the center of the design process, to serve as boundary objects for communication and guide practitioners for design and evaluation. We implement Orbit as an interactive system, which enables stakeholders to interact with objective spaces directly and supports real-time exploration and evaluation of design trade-offs. We evaluate Orbit through a user study involving twelve industry practitioners, showing that it supports efficient design space exploration, leads to more informed decision-making, and enhances awareness of the inherent trade-offs of multiple objectives. Orbit (1) opens up new opportunities of an objective-centric design process for any multi-objective ML models, as well as (2) sheds light on future designs that push practitioners to go beyond a narrow metric-centric or example-centric mindset.
HiMemFormer: Hierarchical Memory-Aware Transformer for Multi-Agent Action Anticipation
Nov 03, 2024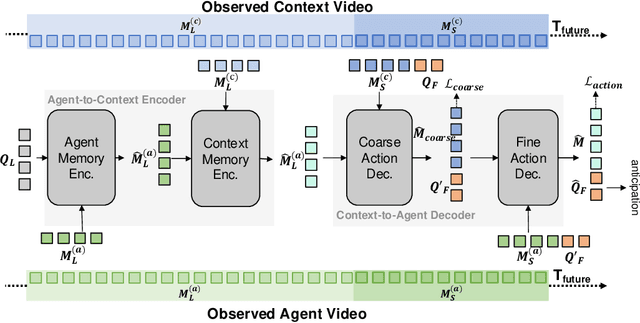
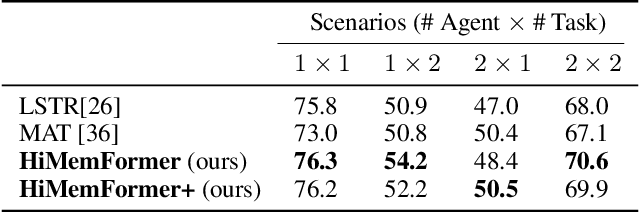

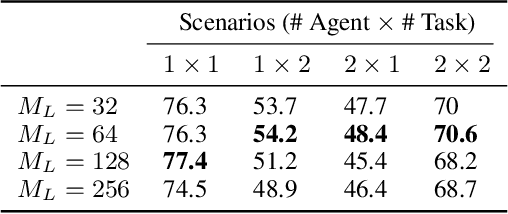
Understanding and predicting human actions has been a long-standing challenge and is a crucial measure of perception in robotics AI. While significant progress has been made in anticipating the future actions of individual agents, prior work has largely overlooked a key aspect of real-world human activity -- interactions. To address this gap in human-like forecasting within multi-agent environments, we present the Hierarchical Memory-Aware Transformer (HiMemFormer), a transformer-based model for online multi-agent action anticipation. HiMemFormer integrates and distributes global memory that captures joint historical information across all agents through a transformer framework, with a hierarchical local memory decoder that interprets agent-specific features based on these global representations using a coarse-to-fine strategy. In contrast to previous approaches, HiMemFormer uniquely hierarchically applies the global context with agent-specific preferences to avoid noisy or redundant information in multi-agent action anticipation. Extensive experiments on various multi-agent scenarios demonstrate the significant performance of HiMemFormer, compared with other state-of-the-art methods.
What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing
Sep 14, 2024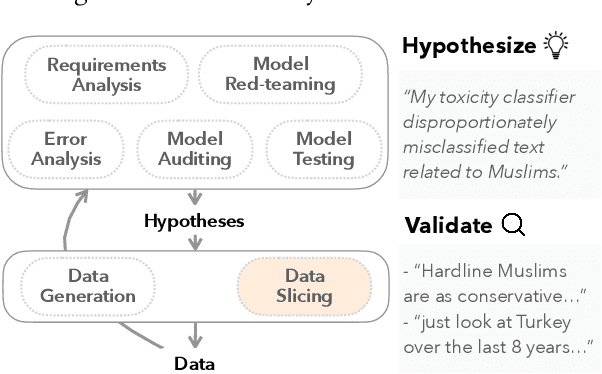
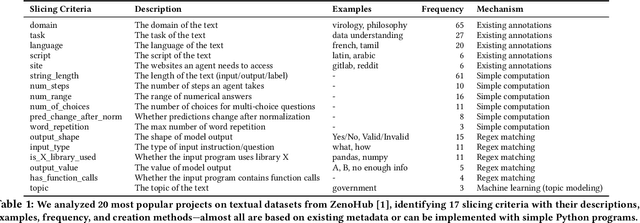

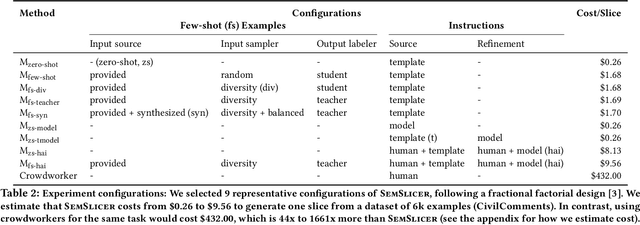
Machine learning models make mistakes, yet sometimes it is difficult to identify the systematic problems behind the mistakes. Practitioners engage in various activities, including error analysis, testing, auditing, and red-teaming, to form hypotheses of what can go (or has gone) wrong with their models. To validate these hypotheses, practitioners employ data slicing to identify relevant examples. However, traditional data slicing is limited by available features and programmatic slicing functions. In this work, we propose SemSlicer, a framework that supports semantic data slicing, which identifies a semantically coherent slice, without the need for existing features. SemSlicer uses Large Language Models to annotate datasets and generate slices from any user-defined slicing criteria. We show that SemSlicer generates accurate slices with low cost, allows flexible trade-offs between different design dimensions, reliably identifies under-performing data slices, and helps practitioners identify useful data slices that reflect systematic problems.
What You Say = What You Want? Teaching Humans to Articulate Requirements for LLMs
Sep 13, 2024



Prompting ChatGPT to achieve complex goals (e.g., creating a customer support chatbot) often demands meticulous prompt engineering, including aspects like fluent writing and chain-of-thought techniques. While emerging prompt optimizers can automatically refine many of these aspects, we argue that clearly conveying customized requirements (e.g., how to handle diverse inputs) remains a human-centric challenge. In this work, we introduce Requirement-Oriented Prompt Engineering (ROPE), a paradigm that focuses human attention on generating clear, complete requirements during prompting. We implement ROPE through an assessment and training suite that provides deliberate practice with LLM-generated feedback. In a study with 30 novices, we show that requirement-focused training doubles novices' prompting performance, significantly outperforming conventional prompt engineering training and prompt optimization. We also demonstrate that high-quality LLM outputs are directly tied to the quality of input requirements. Our work paves the way for more effective task delegation in human-LLM collaborative prompting.
SELF-GUIDE: Better Task-Specific Instruction Following via Self-Synthetic Finetuning
Jul 16, 2024



Large language models (LLMs) hold the promise of solving diverse tasks when provided with appropriate natural language prompts. However, prompting often leads models to make predictions with lower accuracy compared to finetuning a model with ample training data. On the other hand, while finetuning LLMs on task-specific data generally improves their performance, abundant annotated datasets are not available for all tasks. Previous work has explored generating task-specific data from state-of-the-art LLMs and using this data to finetune smaller models, but this approach requires access to a language model other than the one being trained, which introduces cost, scalability challenges, and legal hurdles associated with continuously relying on more powerful LLMs. In response to these, we propose SELF-GUIDE, a multi-stage mechanism in which we synthesize task-specific input-output pairs from the student LLM, then use these input-output pairs to finetune the student LLM itself. In our empirical evaluation of the Natural Instructions V2 benchmark, we find that SELF-GUIDE improves the performance of LLM by a substantial margin. Specifically, we report an absolute improvement of approximately 15% for classification tasks and 18% for generation tasks in the benchmark's metrics. This sheds light on the promise of self-synthesized data guiding LLMs towards becoming task-specific experts without any external learning signals.
Synthetic Multimodal Question Generation
Jul 02, 2024



Multimodal Retrieval Augmented Generation (MMRAG) is a powerful approach to question-answering over multimodal documents. A key challenge with evaluating MMRAG is the paucity of high-quality datasets matching the question styles and modalities of interest. In light of this, we propose SMMQG, a synthetic data generation framework. SMMQG leverages interplay between a retriever, large language model (LLM) and large multimodal model (LMM) to generate question and answer pairs directly from multimodal documents, with the questions conforming to specified styles and modalities. We use SMMQG to generate an MMRAG dataset of 1024 questions over Wikipedia documents and evaluate state-of-the-art models using it, revealing insights into model performance that are attainable only through style- and modality-specific evaluation data. Next, we measure the quality of data produced by SMMQG via a human study. We find that the quality of our synthetic data is on par with the quality of the crowdsourced benchmark MMQA and that downstream evaluation results using both datasets strongly concur.