 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ramon Llull's Thinking Machine for Automated Ideation
Aug 28, 2025This paper revisits Ramon Llull's Ars combinatoria - a medieval framework for generating knowledge through symbolic recombination - as a conceptual foundation for building a modern Llull's thinking machine for research ideation. Our approach defines three compositional axes: Theme (e.g., efficiency, adaptivity), Domain (e.g., question answering, machine translation), and Method (e.g., adversarial training, linear attention). These elements represent high-level abstractions common in scientific work - motivations, problem settings, and technical approaches - and serve as building blocks for LLM-driven exploration. We mine elements from human experts or conference papers and show that prompting LLMs with curated combinations produces research ideas that are diverse, relevant, and grounded in current literature. This modern thinking machine offers a lightweight, interpretable tool for augmenting scientific creativity and suggests a path toward collaborative ideation between humans and AI.
Strategic Planning and Rationalizing on Trees Make LLMs Better Debaters
May 20, 2025Winning competitive debates requires sophisticated reasoning and argument skills. There are unique challenges in the competitive debate: (1) The time constraints force debaters to make strategic choices about which points to pursue rather than covering all possible arguments; (2) The persuasiveness of the debate relies on the back-and-forth interaction between arguments, which a single final game status cannot evaluate. To address these challenges, we propose TreeDebater, a novel debate framework that excels in competitive debate. We introduce two tree structures: the Rehearsal Tree and Debate Flow Tree. The Rehearsal Tree anticipates the attack and defenses to evaluate the strength of the claim, while the Debate Flow Tree tracks the debate status to identify the active actions. TreeDebater allocates its time budget among candidate actions and uses the speech time controller and feedback from the simulated audience to revise its statement. The human evaluation on both the stage-level and the debate-level comparison shows that our TreeDebater outperforms the state-of-the-art multi-agent debate system. Further investigation shows that TreeDebater shows better strategies in limiting time to important debate actions, aligning with the strategies of human debate experts.
Improving Large Language Model Planning with Action Sequence Similarity
May 02, 2025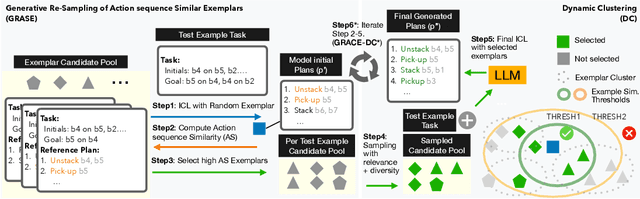

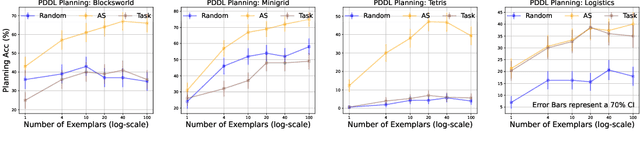

Planning is essential for artificial intelligence systems to look ahead and proactively determine a course of actions to reach objectives in the virtual and real world. Recent work on large language models (LLMs) sheds light on their planning capability in various tasks. However, it remains unclear what signals in the context influence the model performance. In this work, we explore how to improve the model planning capability through in-context learning (ICL), specifically, what signals can help select the exemplars. Through extensive experiments, we observe that commonly used problem similarity may result in false positives with drastically different plans, which can mislead the model. In response, we propose to sample and filter exemplars leveraging plan side action sequence similarity (AS). We propose GRASE-DC: a two-stage pipeline that first re-samples high AS exemplars and then curates the selected exemplars with dynamic clustering on AS to achieve a balance of relevance and diversity. Our experimental result confirms that GRASE-DC achieves significant performance improvement on various planning tasks (up to ~11-40 point absolute accuracy improvement with 27.3% fewer exemplars needed on average). With GRASE-DC* + VAL, where we iteratively apply GRASE-DC with a validator, we are able to even boost the performance by 18.9% more. Extensive analysis validates the consistent performance improvement of GRASE-DC with various backbone LLMs and on both classical planning and natural language planning benchmarks. GRASE-DC can further boost the planning accuracy by ~24 absolute points on harder problems using simpler problems as exemplars over a random baseline. This demonstrates its ability to generalize to out-of-distribution problems.
* 25 pages, 11 figures
HiMemFormer: Hierarchical Memory-Aware Transformer for Multi-Agent Action Anticipation
Nov 03, 2024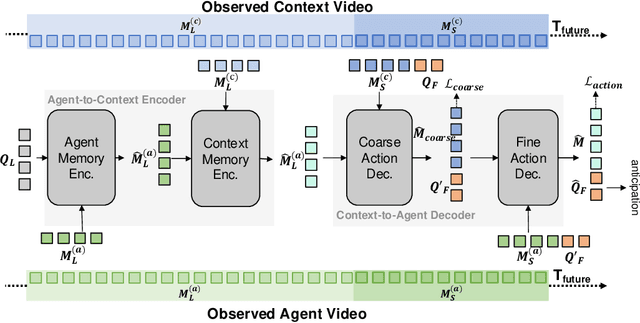
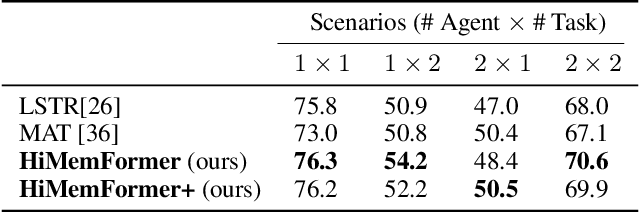

Understanding and predicting human actions has been a long-standing challenge and is a crucial measure of perception in robotics AI. While significant progress has been made in anticipating the future actions of individual agents, prior work has largely overlooked a key aspect of real-world human activity -- interactions. To address this gap in human-like forecasting within multi-agent environments, we present the Hierarchical Memory-Aware Transformer (HiMemFormer), a transformer-based model for online multi-agent action anticipation. HiMemFormer integrates and distributes global memory that captures joint historical information across all agents through a transformer framework, with a hierarchical local memory decoder that interprets agent-specific features based on these global representations using a coarse-to-fine strategy. In contrast to previous approaches, HiMemFormer uniquely hierarchically applies the global context with agent-specific preferences to avoid noisy or redundant information in multi-agent action anticipation. Extensive experiments on various multi-agent scenarios demonstrate the significant performance of HiMemFormer, compared with other state-of-the-art methods.
$\textit{GeoHard}$: Towards Measuring Class-wise Hardness through Modelling Class Semantics
Jul 17, 2024



Recent advances in measuring hardness-wise properties of data guide language models in sample selection within low-resource scenarios. However, class-specific properties are overlooked for task setup and learning. How will these properties influence model learning and is it generalizable across datasets? To answer this question, this work formally initiates the concept of $\textit{class-wise hardness}$. Experiments across eight natural language understanding (NLU) datasets demonstrate a consistent hardness distribution across learning paradigms, models, and human judgment. Subsequent experiments unveil a notable challenge in measuring such class-wise hardness with instance-level metrics in previous works. To address this, we propose $\textit{GeoHard}$ for class-wise hardness measurement by modeling class geometry in the semantic embedding space. $\textit{GeoHard}$ surpasses instance-level metrics by over 59 percent on $\textit{Pearson}$'s correlation on measuring class-wise hardness. Our analysis theoretically and empirically underscores the generality of $\textit{GeoHard}$ as a fresh perspective on data diagnosis. Additionally, we showcase how understanding class-wise hardness can practically aid in improving task learning.
$\texttt{MixGR}$: Enhancing Retriever Generalization for Scientific Domain through Complementary Granularity
Jul 15, 2024



Recent studies show the growing significance of document retrieval in the generation of LLMs, i.e., RAG, within the scientific domain by bridging their knowledge gap. However, dense retrievers often struggle with domain-specific retrieval and complex query-document relationships, particularly when query segments correspond to various parts of a document. To alleviate such prevalent challenges, this paper introduces $\texttt{MixGR}$, which improves dense retrievers' awareness of query-document matching across various levels of granularity in queries and documents using a zero-shot approach. $\texttt{MixGR}$ fuses various metrics based on these granularities to a united score that reflects a comprehensive query-document similarity. Our experiments demonstrate that $\texttt{MixGR}$ outperforms previous document retrieval by 24.7% and 9.8% on nDCG@5 with unsupervised and supervised retrievers, respectively, averaged on queries containing multiple subqueries from five scientific retrieval datasets. Moreover, the efficacy of two downstream scientific question-answering tasks highlights the advantage of $\texttt{MixGR}$to boost the application of LLMs in the scientific domain.
Beyond Relevance: Evaluate and Improve Retrievers on Perspective Awareness
May 04, 2024



The task of Information Retrieval (IR) requires a system to identify relevant documents based on users' information needs. In real-world scenarios, retrievers are expected to not only rely on the semantic relevance between the documents and the queries but also recognize the nuanced intents or perspectives behind a user query. For example, when asked to verify a claim, a retrieval system is expected to identify evidence from both supporting vs. contradicting perspectives, for the downstream system to make a fair judgment call. In this work, we study whether retrievers can recognize and respond to different perspectives of the queries -- beyond finding relevant documents for a claim, can retrievers distinguish supporting vs. opposing documents? We reform and extend six existing tasks to create a benchmark for retrieval, where we have diverse perspectives described in free-form text, besides root, neutral queries. We show that current retrievers covered in our experiments have limited awareness of subtly different perspectives in queries and can also be biased toward certain perspectives. Motivated by the observation, we further explore the potential to leverage geometric features of retriever representation space to improve the perspective awareness of retrievers in a zero-shot manner. We demonstrate the efficiency and effectiveness of our projection-based methods on the same set of tasks. Further analysis also shows how perspective awareness improves performance on various downstream tasks, with 4.2% higher accuracy on AmbigQA and 29.9% more correlation with designated viewpoints on essay writing, compared to non-perspective-aware baselines.
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Feb 27, 2024For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known "facts" that are relevant to the input prompt from the LLM. And then it asks the model to "reflect" over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.
Dense X Retrieval: What Retrieval Granularity Should We Use?
Dec 12, 2023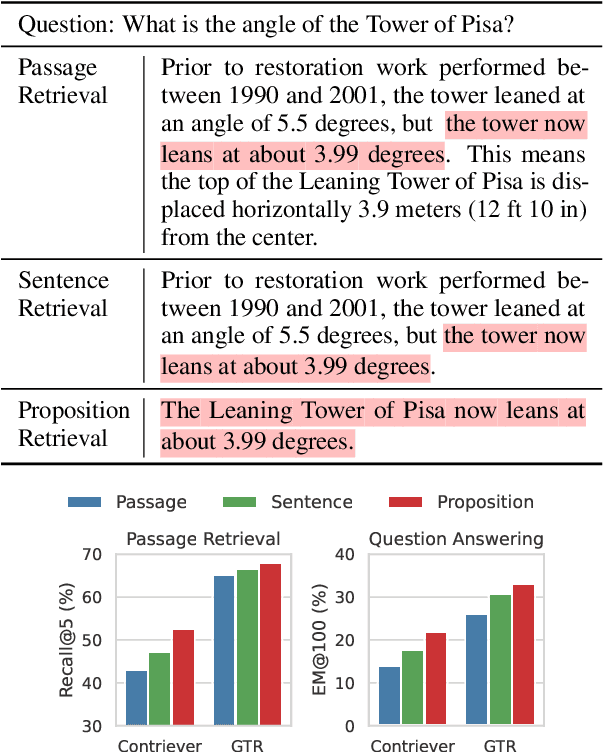
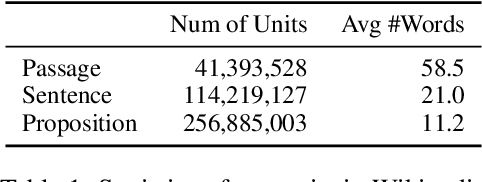
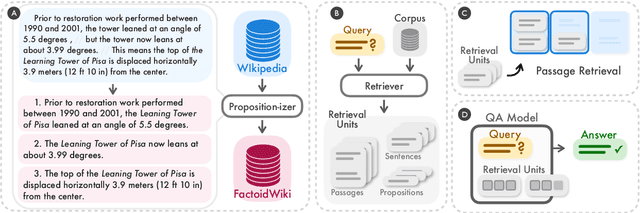
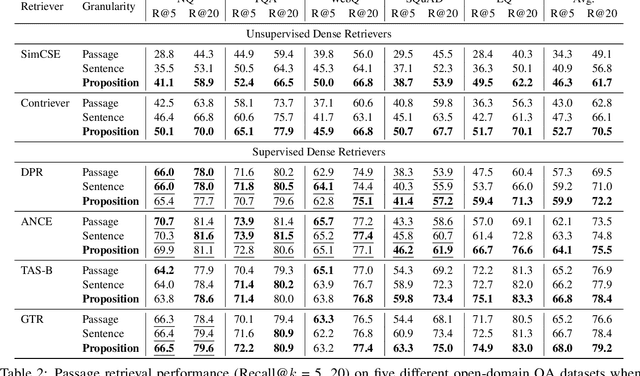
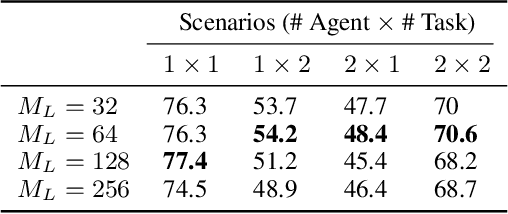
Dense retrieval has become a prominent method to obtain relevant context or world knowledge in open-domain NLP tasks. When we use a learned dense retriever on a retrieval corpus at inference time, an often-overlooked design choice is the retrieval unit in which the corpus is indexed, e.g. document, passage, or sentence. We discover that the retrieval unit choice significantly impacts the performance of both retrieval and downstream tasks. Distinct from the typical approach of using passages or sentences, we introduce a novel retrieval unit, proposition, for dense retrieval. Propositions are defined as atomic expressions within text, each encapsulating a distinct factoid and presented in a concise, self-contained natural language format. We conduct an empirical comparison of different retrieval granularity. Our results reveal that proposition-based retrieval significantly outperforms traditional passage or sentence-based methods in dense retrieval. Moreover, retrieval by proposition also enhances the performance of downstream QA tasks, since the retrieved texts are more condensed with question-relevant information, reducing the need for lengthy input tokens and minimizing the inclusion of extraneous, irrelevant information.
"Merge Conflicts!" Exploring the Impacts of External Distractors to Parametric Knowledge Graphs
Sep 15, 2023



Large language models (LLMs) acquire extensive knowledge during pre-training, known as their parametric knowledge. However, in order to remain up-to-date and align with human instructions, LLMs inevitably require external knowledge during their interactions with users. This raises a crucial question: How will LLMs respond when external knowledge interferes with their parametric knowledge? To investigate this question, we propose a framework that systematically elicits LLM parametric knowledge and introduces external knowledge. Specifically, we uncover the impacts by constructing a parametric knowledge graph to reveal the different knowledge structures of LLMs, and introduce external knowledge through distractors of varying degrees, methods, positions, and formats. Our experiments on both black-box and open-source models demonstrate that LLMs tend to produce responses that deviate from their parametric knowledge, particularly when they encounter direct conflicts or confounding changes of information within detailed contexts. We also find that while LLMs are sensitive to the veracity of external knowledge, they can still be distracted by unrelated information. These findings highlight the risk of hallucination when integrating external knowledge, even indirectly, during interactions with current LLMs. All the data and results are publicly available.