 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Human Behavior Simulation via Verbal Feedback
May 19, 2026Humans learn social norms and behaviors from verbal feedback (e.g., a parent saying "that was rude" or a friend explaining "here's why that hurt"). Yet, learning from feedback for LLMs has largely focused on domains like code and math, where RL rewards are directly verifiable and condensed into scalar values. As LLMs are increasingly used to simulate human behavior, e.g., standing in for users, patients, students, and other personas, there is a pressing need to make them more human-like, which requires embracing a fundamentally different kind of signal: feedback that is verbal, subjective, and multi-faceted. We present DITTO, a model trained by treating verbal feedback as a first-class signal in reinforcement learning. After each rollout, DITTO receives verbal feedback and generates a feedback-conditioned improved rollout; both outputs are jointly optimized with GRPO, distilling verbal guidance into the base policy without requiring feedback at test time. We also introduce SOUL (Simulation gym Of hUman-Like behavior), a unified benchmark and training data suite spanning 10 tasks across six categories: Theory of Mind, character role play, social skill, learner simulation, user simulation, and persona simulation. DITTO achieves an average 36% improvement over the base model and exceeds GPT-5.4 on 6 of 10 SOUL benchmarks, demonstrating that RL with verbal feedback is a promising direction for training LLMs to simulate human behavior.
Experiential Reinforcement Learning
Feb 15, 2026Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.
One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
LogiCoL: Logically-Informed Contrastive Learning for Set-based Dense Retrieval
May 26, 2025While significant progress has been made with dual- and bi-encoder dense retrievers, they often struggle on queries with logical connectives, a use case that is often overlooked yet important in downstream applications. Current dense retrievers struggle with such queries, such that the retrieved results do not respect the logical constraints implied in the queries. To address this challenge, we introduce LogiCoL, a logically-informed contrastive learning objective for dense retrievers. LogiCoL builds upon in-batch supervised contrastive learning, and learns dense retrievers to respect the subset and mutually-exclusive set relation between query results via two sets of soft constraints expressed via t-norm in the learning objective. We evaluate the effectiveness of LogiCoL on the task of entity retrieval, where the model is expected to retrieve a set of entities in Wikipedia that satisfy the implicit logical constraints in the query. We show that models trained with LogiCoL yield improvement both in terms of retrieval performance and logical consistency in the results. We provide detailed analysis and insights to uncover why queries with logical connectives are challenging for dense retrievers and why LogiCoL is most effective.
Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale
Apr 19, 2025Large Language Models (LLMs) have emerged as personalized assistants for users across a wide range of tasks -- from offering writing support to delivering tailored recommendations or consultations. Over time, the interaction history between a user and an LLM can provide extensive information about an individual's traits and preferences. However, open questions remain on how well LLMs today can effectively leverage such history to (1) internalize the user's inherent traits and preferences, (2) track how the user profiling and preferences evolve over time, and (3) generate personalized responses accordingly in new scenarios. In this work, we introduce the PERSONAMEM benchmark. PERSONAMEM features curated user profiles with over 180 simulated user-LLM interaction histories, each containing up to 60 sessions of multi-turn conversations across 15 real-world tasks that require personalization. Given an in-situ user query, i.e. query issued by the user from the first-person perspective, we evaluate LLM chatbots' ability to identify the most suitable response according to the current state of the user's profile. We observe that current LLMs still struggle to recognize the dynamic evolution in users' profiles over time through direct prompting approaches. As a consequence, LLMs often fail to deliver responses that align with users' current situations and preferences, with frontier models such as GPT-4.1, o4-mini, GPT-4.5, o1, or Gemini-2.0 achieving only around 50% overall accuracy, suggesting room for improvement. We hope that PERSONAMEM, along with the user profile and conversation simulation pipeline, can facilitate future research in the development of truly user-aware chatbots. Code and data are available at github.com/bowen-upenn/PersonaMem.
Talking Point based Ideological Discourse Analysis in News Events
Apr 10, 2025Analyzing ideological discourse even in the age of LLMs remains a challenge, as these models often struggle to capture the key elements that shape real-world narratives. Specifically, LLMs fail to focus on characteristic elements driving dominant discourses and lack the ability to integrate contextual information required for understanding abstract ideological views. To address these limitations, we propose a framework motivated by the theory of ideological discourse analysis to analyze news articles related to real-world events. Our framework represents the news articles using a relational structure - talking points, which captures the interaction between entities, their roles, and media frames along with a topic of discussion. It then constructs a vocabulary of repeating themes - prominent talking points, that are used to generate ideology-specific viewpoints (or partisan perspectives). We evaluate our framework's ability to generate these perspectives through automated tasks - ideology and partisan classification tasks, supplemented by human validation. Additionally, we demonstrate straightforward applicability of our framework in creating event snapshots, a visual way of interpreting event discourse. We release resulting dataset and model to the community to support further research.
On Reference (In-)Determinacy in Natural Language Inference
Feb 09, 2025



We revisit the reference determinacy (RD) assumption in the task of natural language inference (NLI), i.e., the premise and hypothesis are assumed to refer to the same context when human raters annotate a label. While RD is a practical assumption for constructing a new NLI dataset, we observe that current NLI models, which are typically trained solely on hypothesis-premise pairs created with the RD assumption, fail in downstream applications such as fact verification, where the input premise and hypothesis may refer to different contexts. To highlight the impact of this phenomenon in real-world use cases, we introduce RefNLI, a diagnostic benchmark for identifying reference ambiguity in NLI examples. In RefNLI, the premise is retrieved from a knowledge source (i.e., Wikipedia) and does not necessarily refer to the same context as the hypothesis. With RefNLI, we demonstrate that finetuned NLI models and few-shot prompted LLMs both fail to recognize context mismatch, leading to over 80% false contradiction and over 50% entailment predictions. We discover that the existence of reference ambiguity in NLI examples can in part explain the inherent human disagreements in NLI and provide insight into how the RD assumption impacts the NLI dataset creation process.
$\texttt{MixGR}$: Enhancing Retriever Generalization for Scientific Domain through Complementary Granularity
Jul 15, 2024



Recent studies show the growing significance of document retrieval in the generation of LLMs, i.e., RAG, within the scientific domain by bridging their knowledge gap. However, dense retrievers often struggle with domain-specific retrieval and complex query-document relationships, particularly when query segments correspond to various parts of a document. To alleviate such prevalent challenges, this paper introduces $\texttt{MixGR}$, which improves dense retrievers' awareness of query-document matching across various levels of granularity in queries and documents using a zero-shot approach. $\texttt{MixGR}$ fuses various metrics based on these granularities to a united score that reflects a comprehensive query-document similarity. Our experiments demonstrate that $\texttt{MixGR}$ outperforms previous document retrieval by 24.7% and 9.8% on nDCG@5 with unsupervised and supervised retrievers, respectively, averaged on queries containing multiple subqueries from five scientific retrieval datasets. Moreover, the efficacy of two downstream scientific question-answering tasks highlights the advantage of $\texttt{MixGR}$to boost the application of LLMs in the scientific domain.
Beyond Relevance: Evaluate and Improve Retrievers on Perspective Awareness
May 04, 2024



The task of Information Retrieval (IR) requires a system to identify relevant documents based on users' information needs. In real-world scenarios, retrievers are expected to not only rely on the semantic relevance between the documents and the queries but also recognize the nuanced intents or perspectives behind a user query. For example, when asked to verify a claim, a retrieval system is expected to identify evidence from both supporting vs. contradicting perspectives, for the downstream system to make a fair judgment call. In this work, we study whether retrievers can recognize and respond to different perspectives of the queries -- beyond finding relevant documents for a claim, can retrievers distinguish supporting vs. opposing documents? We reform and extend six existing tasks to create a benchmark for retrieval, where we have diverse perspectives described in free-form text, besides root, neutral queries. We show that current retrievers covered in our experiments have limited awareness of subtly different perspectives in queries and can also be biased toward certain perspectives. Motivated by the observation, we further explore the potential to leverage geometric features of retriever representation space to improve the perspective awareness of retrievers in a zero-shot manner. We demonstrate the efficiency and effectiveness of our projection-based methods on the same set of tasks. Further analysis also shows how perspective awareness improves performance on various downstream tasks, with 4.2% higher accuracy on AmbigQA and 29.9% more correlation with designated viewpoints on essay writing, compared to non-perspective-aware baselines.
Minimal Evidence Group Identification for Claim Verification
Apr 24, 2024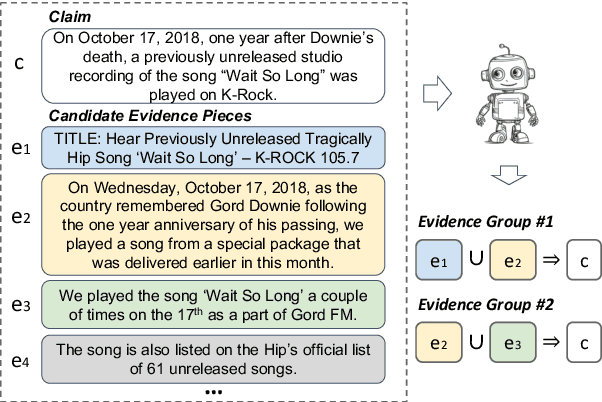
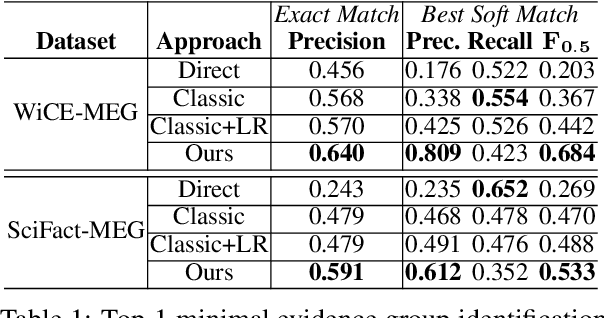
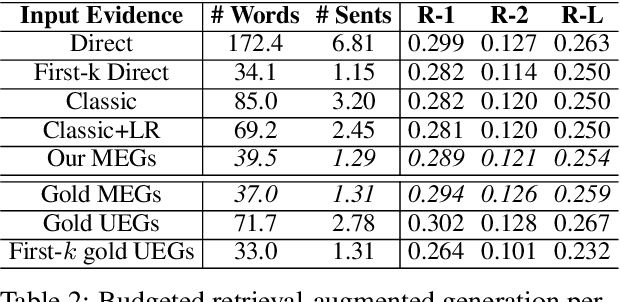

Claim verification in real-world settings (e.g. against a large collection of candidate evidences retrieved from the web) typically requires identifying and aggregating a complete set of evidence pieces that collectively provide full support to the claim. The problem becomes particularly challenging when there exists distinct sets of evidence that could be used to verify the claim from different perspectives. In this paper, we formally define and study the problem of identifying such minimal evidence groups (MEGs) for claim verification. We show that MEG identification can be reduced from Set Cover problem, based on entailment inference of whether a given evidence group provides full/partial support to a claim. Our proposed approach achieves 18.4% and 34.8% absolute improvements on the WiCE and SciFact datasets over LLM prompting. Finally, we demonstrate the benefits of MEGs in downstream applications such as claim generation.