 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
LongReason: A Synthetic Long-Context Reasoning Benchmark via Context Expansion
Jan 25, 2025



Large language models (LLMs) have demonstrated remarkable progress in understanding long-context inputs. However, benchmarks for evaluating the long-context reasoning abilities of LLMs fall behind the pace. Existing benchmarks often focus on a narrow range of tasks or those that do not demand complex reasoning. To address this gap and enable a more comprehensive evaluation of the long-context reasoning capabilities of current LLMs, we propose a new synthetic benchmark, LongReason, which is constructed by synthesizing long-context reasoning questions from a varied set of short-context reasoning questions through context expansion. LongReason consists of 794 multiple-choice reasoning questions with diverse reasoning patterns across three task categories: reading comprehension, logical inference, and mathematical word problems. We evaluate 21 LLMs on LongReason, revealing that most models experience significant performance drops as context length increases. Our further analysis shows that even state-of-the-art LLMs still have significant room for improvement in providing robust reasoning across different tasks. We will open-source LongReason to support the comprehensive evaluation of LLMs' long-context reasoning capabilities.
It Takes Two: On the Seamlessness between Reward and Policy Model in RLHF
Jun 12, 2024Reinforcement Learning from Human Feedback (RLHF) involves training policy models (PMs) and reward models (RMs) to align language models with human preferences. Instead of focusing solely on PMs and RMs independently, we propose to examine their interactions during fine-tuning, introducing the concept of seamlessness. Our study starts with observing the saturation phenomenon, where continual improvements in RM and PM do not translate into RLHF progress. Our analysis shows that RMs fail to assign proper scores to PM responses, resulting in a 35% mismatch rate with human preferences, highlighting a significant discrepancy between PM and RM. To measure seamlessness between PM and RM without human effort, we propose an automatic metric, SEAM. SEAM quantifies the discrepancies between PM and RM judgments induced by data samples. We validate the effectiveness of SEAM in data selection and model augmentation. Our experiments demonstrate that (1) using SEAM-filtered data for RL training improves RLHF performance by 4.5%, and (2) SEAM-guided model augmentation results in a 4% performance improvement over standard augmentation methods.
DiffNorm: Self-Supervised Normalization for Non-autoregressive Speech-to-speech Translation
May 22, 2024



Non-autoregressive Transformers (NATs) are recently applied in direct speech-to-speech translation systems, which convert speech across different languages without intermediate text data. Although NATs generate high-quality outputs and offer faster inference than autoregressive models, they tend to produce incoherent and repetitive results due to complex data distribution (e.g., acoustic and linguistic variations in speech). In this work, we introduce DiffNorm, a diffusion-based normalization strategy that simplifies data distributions for training NAT models. After training with a self-supervised noise estimation objective, DiffNorm constructs normalized target data by denoising synthetically corrupted speech features. Additionally, we propose to regularize NATs with classifier-free guidance, improving model robustness and translation quality by randomly dropping out source information during training. Our strategies result in a notable improvement of about +7 ASR-BLEU for English-Spanish (En-Es) and +2 ASR-BLEU for English-French (En-Fr) translations on the CVSS benchmark, while attaining over 14x speedup for En-Es and 5x speedup for En-Fr translations compared to autoregressive baselines.
AnaloBench: Benchmarking the Identification of Abstract and Long-context Analogies
Feb 19, 2024Humans regularly engage in analogical thinking, relating personal experiences to current situations ($X$ is analogous to $Y$ because of $Z$). Analogical thinking allows humans to solve problems in creative ways, grasp difficult concepts, and articulate ideas more effectively. Can language models (LMs) do the same? To answer this question, we propose ANALOBENCH, a benchmark to determine analogical reasoning ability in LMs. Our benchmarking approach focuses on aspects of this ability that are common among humans: (i) recalling related experiences from a large amount of information, and (ii) applying analogical reasoning to complex and lengthy scenarios. We test a broad collection of proprietary models (e.g., GPT family, Claude V2) and open source models such as LLaMA2. As in prior results, scaling up LMs results in some performance boosts. Surprisingly, scale offers minimal gains when, (i) analogies involve lengthy scenarios, or (ii) recalling relevant scenarios from a large pool of information, a process analogous to finding a needle in a haystack. We hope these observations encourage further research in this field.
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation
Feb 02, 2024



Moderate-sized large language models (LLMs) -- those with 7B or 13B parameters -- exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation models, like ALMA, does not match the performance of state-of-the-art conventional encoder-decoder translation models or larger-scale LLMs such as GPT-4. In this study, we bridge this performance gap. We first assess the shortcomings of supervised fine-tuning for LLMs in the MT task, emphasizing the quality issues present in the reference data, despite being human-generated. Then, in contrast to SFT which mimics reference translations, we introduce Contrastive Preference Optimization (CPO), a novel approach that trains models to avoid generating adequate but not perfect translations. Applying CPO to ALMA models with only 22K parallel sentences and 12M parameters yields significant improvements. The resulting model, called ALMA-R, can match or exceed the performance of the WMT competition winners and GPT-4 on WMT'21, WMT'22 and WMT'23 test datasets.
The Language Barrier: Dissecting Safety Challenges of LLMs in Multilingual Contexts
Jan 23, 2024



As the influence of large language models (LLMs) spans across global communities, their safety challenges in multilingual settings become paramount for alignment research. This paper examines the variations in safety challenges faced by LLMs across different languages and discusses approaches to alleviating such concerns. By comparing how state-of-the-art LLMs respond to the same set of malicious prompts written in higher- vs. lower-resource languages, we observe that (1) LLMs tend to generate unsafe responses much more often when a malicious prompt is written in a lower-resource language, and (2) LLMs tend to generate more irrelevant responses to malicious prompts in lower-resource languages. To understand where the discrepancy can be attributed, we study the effect of instruction tuning with reinforcement learning from human feedback (RLHF) or supervised finetuning (SFT) on the HH-RLHF dataset. Surprisingly, while training with high-resource languages improves model alignment, training in lower-resource languages yields minimal improvement. This suggests that the bottleneck of cross-lingual alignment is rooted in the pretraining stage. Our findings highlight the challenges in cross-lingual LLM safety, and we hope they inform future research in this direction.
Narrowing the Gap between Zero- and Few-shot Machine Translation by Matching Styles
Nov 04, 2023



Large language models trained primarily in a monolingual setting have demonstrated their ability to generalize to machine translation using zero- and few-shot examples with in-context learning. However, even though zero-shot translations are relatively good, there remains a discernible gap comparing their performance with the few-shot setting. In this paper, we investigate the factors contributing to this gap and find that this gap can largely be closed (for about 70%) by matching the writing styles of the target corpus. Additionally, we explore potential approaches to enhance zero-shot baselines without the need for parallel demonstration examples, providing valuable insights into how these methods contribute to improving translation metrics.
Do pretrained Transformers Really Learn In-context by Gradient Descent?
Oct 12, 2023
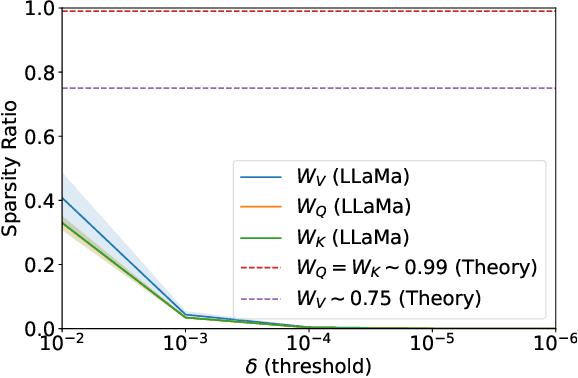


Is In-Context Learning (ICL) implicitly equivalent to Gradient Descent (GD)? Several recent works draw analogies between the dynamics of GD and the emergent behavior of ICL in large language models. However, these works make assumptions far from the realistic natural language setting in which language models are trained. Such discrepancies between theory and practice, therefore, necessitate further investigation to validate their applicability. We start by highlighting the weaknesses in prior works that construct Transformer weights to simulate gradient descent. Their experiments with training Transformers on ICL objective, inconsistencies in the order sensitivity of ICL and GD, sparsity of the constructed weights, and sensitivity to parameter changes are some examples of a mismatch from the real-world setting. Furthermore, we probe and compare the ICL vs. GD hypothesis in a natural setting. We conduct comprehensive empirical analyses on language models pretrained on natural data (LLaMa-7B). Our comparisons on various performance metrics highlight the inconsistent behavior of ICL and GD as a function of various factors such as datasets, models, and number of demonstrations. We observe that ICL and GD adapt the output distribution of language models differently. These results indicate that the equivalence between ICL and GD is an open hypothesis, requires nuanced considerations and calls for further studies.
SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation
Oct 06, 2023Existing watermarking algorithms are vulnerable to paraphrase attacks because of their token-level design. To address this issue, we propose SemStamp, a robust sentence-level semantic watermarking algorithm based on locality-sensitive hashing (LSH), which partitions the semantic space of sentences. The algorithm encodes and LSH-hashes a candidate sentence generated by an LLM, and conducts sentence-level rejection sampling until the sampled sentence falls in watermarked partitions in the semantic embedding space. A margin-based constraint is used to enhance its robustness. To show the advantages of our algorithm, we propose a "bigram" paraphrase attack using the paraphrase that has the fewest bigram overlaps with the original sentence. This attack is shown to be effective against the existing token-level watermarking method. Experimental results show that our novel semantic watermark algorithm is not only more robust than the previous state-of-the-art method on both common and bigram paraphrase attacks, but also is better at preserving the quality of generation.