 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Normalization-Free Transformers
Dec 11, 2025Although normalization layers have long been viewed as indispensable components of deep learning architectures, the recent introduction of Dynamic Tanh (DyT) has demonstrated that alternatives are possible. The point-wise function DyT constrains extreme values for stable convergence and reaches normalization-level performance; this work seeks further for function designs that can surpass it. We first study how the intrinsic properties of point-wise functions influence training and performance. Building on these findings, we conduct a large-scale search for a more effective function design. Through this exploration, we introduce $\mathrm{Derf}(x) = \mathrm{erf}(αx + s)$, where $\mathrm{erf}(x)$ is the rescaled Gaussian cumulative distribution function, and identify it as the most performant design. Derf outperforms LayerNorm, RMSNorm, and DyT across a wide range of domains, including vision (image recognition and generation), speech representation, and DNA sequence modeling. Our findings suggest that the performance gains of Derf largely stem from its improved generalization rather than stronger fitting capacity. Its simplicity and stronger performance make Derf a practical choice for normalization-free Transformer architectures.
GenEx: Generating an Explorable World
Dec 12, 2024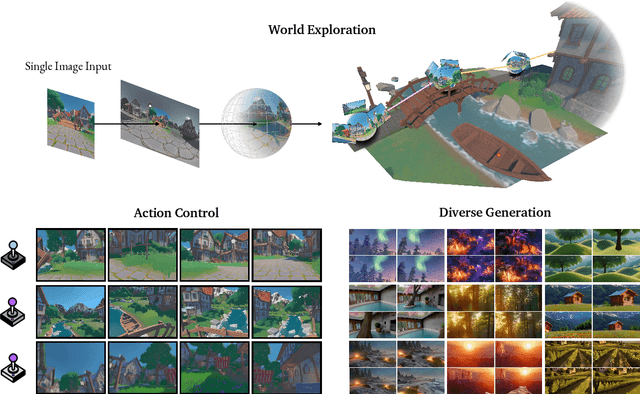
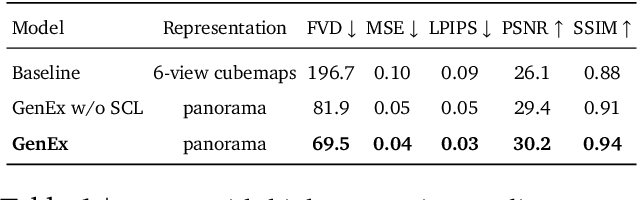

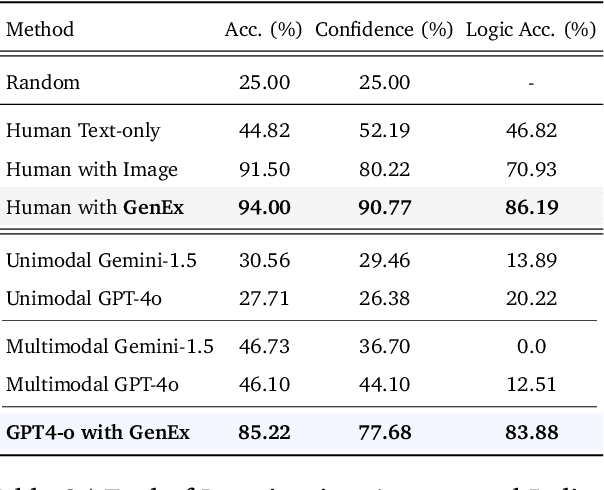
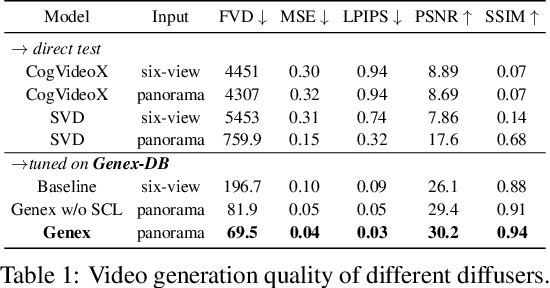
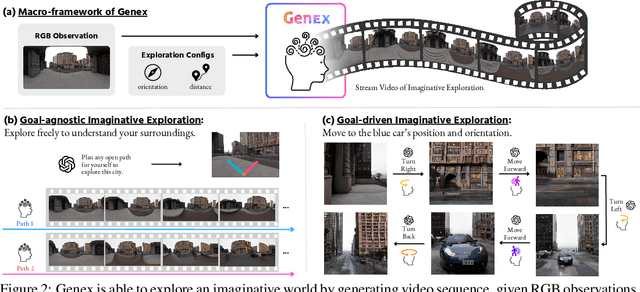
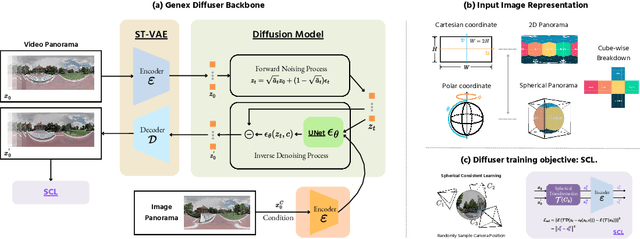
Understanding, navigating, and exploring the 3D physical real world has long been a central challenge in the development of artificial intelligence. In this work, we take a step toward this goal by introducing GenEx, a system capable of planning complex embodied world exploration, guided by its generative imagination that forms priors (expectations) about the surrounding environments. GenEx generates an entire 3D-consistent imaginative environment from as little as a single RGB image, bringing it to life through panoramic video streams. Leveraging scalable 3D world data curated from Unreal Engine, our generative model is rounded in the physical world. It captures a continuous 360-degree environment with little effort, offering a boundless landscape for AI agents to explore and interact with. GenEx achieves high-quality world generation, robust loop consistency over long trajectories, and demonstrates strong 3D capabilities such as consistency and active 3D mapping. Powered by generative imagination of the world, GPT-assisted agents are equipped to perform complex embodied tasks, including both goal-agnostic exploration and goal-driven navigation. These agents utilize predictive expectation regarding unseen parts of the physical world to refine their beliefs, simulate different outcomes based on potential decisions, and make more informed choices. In summary, we demonstrate that GenEx provides a transformative platform for advancing embodied AI in imaginative spaces and brings potential for extending these capabilities to real-world exploration.
Generative World Explorer
Nov 19, 2024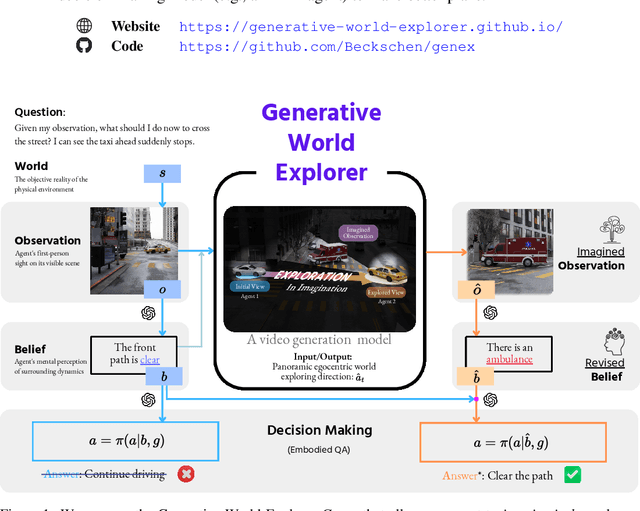
Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update their beliefs about the world state. In contrast, humans can $\textit{imagine}$ unseen parts of the world through a mental exploration and $\textit{revise}$ their beliefs with imagined observations. Such updated beliefs can allow them to make more informed decisions, without necessitating the physical exploration of the world at all times. To achieve this human-like ability, we introduce the $\textit{Generative World Explorer (Genex)}$, an egocentric world exploration framework that allows an agent to mentally explore a large-scale 3D world (e.g., urban scenes) and acquire imagined observations to update its belief. This updated belief will then help the agent to make a more informed decision at the current step. To train $\textit{Genex}$, we create a synthetic urban scene dataset, Genex-DB. Our experimental results demonstrate that (1) $\textit{Genex}$ can generate high-quality and consistent observations during long-horizon exploration of a large virtual physical world and (2) the beliefs updated with the generated observations can inform an existing decision-making model (e.g., an LLM agent) to make better plans.
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Jun 20, 2024Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a "know but don't tell" phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
Every Language Counts: Learn and Unlearn in Multilingual LLMs
Jun 19, 2024



This paper investigates the propagation of harmful information in multilingual large language models (LLMs) and evaluates the efficacy of various unlearning methods. We demonstrate that fake information, regardless of the language it is in, once introduced into these models through training data, can spread across different languages, compromising the integrity and reliability of the generated content. Our findings reveal that standard unlearning techniques, which typically focus on English data, are insufficient in mitigating the spread of harmful content in multilingual contexts and could inadvertently reinforce harmful content across languages. We show that only by addressing harmful responses in both English and the original language of the harmful data can we effectively eliminate generations for all languages. This underscores the critical need for comprehensive unlearning strategies that consider the multilingual nature of modern LLMs to enhance their safety and reliability across diverse linguistic landscapes.
It Takes Two: On the Seamlessness between Reward and Policy Model in RLHF
Jun 12, 2024Reinforcement Learning from Human Feedback (RLHF) involves training policy models (PMs) and reward models (RMs) to align language models with human preferences. Instead of focusing solely on PMs and RMs independently, we propose to examine their interactions during fine-tuning, introducing the concept of seamlessness. Our study starts with observing the saturation phenomenon, where continual improvements in RM and PM do not translate into RLHF progress. Our analysis shows that RMs fail to assign proper scores to PM responses, resulting in a 35% mismatch rate with human preferences, highlighting a significant discrepancy between PM and RM. To measure seamlessness between PM and RM without human effort, we propose an automatic metric, SEAM. SEAM quantifies the discrepancies between PM and RM judgments induced by data samples. We validate the effectiveness of SEAM in data selection and model augmentation. Our experiments demonstrate that (1) using SEAM-filtered data for RL training improves RLHF performance by 4.5%, and (2) SEAM-guided model augmentation results in a 4% performance improvement over standard augmentation methods.