 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Visual Attributes Influence Web Agents? A Comprehensive Evaluation of User Interface Design Factors
Jan 29, 2026Web agents have demonstrated strong performance on a wide range of web-based tasks. However, existing research on the effect of environmental variation has mostly focused on robustness to adversarial attacks, with less attention to agents' preferences in benign scenarios. Although early studies have examined how textual attributes influence agent behavior, a systematic understanding of how visual attributes shape agent decision-making remains limited. To address this, we introduce VAF, a controlled evaluation pipeline for quantifying how webpage Visual Attribute Factors influence web-agent decision-making. Specifically, VAF consists of three stages: (i) variant generation, which ensures the variants share identical semantics as the original item while only differ in visual attributes; (ii) browsing interaction, where agents navigate the page via scrolling and clicking the interested item, mirroring how human users browse online; (iii) validating through both click action and reasoning from agents, which we use the Target Click Rate and Target Mention Rate to jointly evaluate the effect of visual attributes. By quantitatively measuring the decision-making difference between the original and variant, we identify which visual attributes influence agents' behavior most. Extensive experiments, across 8 variant families (48 variants total), 5 real-world websites (including shopping, travel, and news browsing), and 4 representative web agents, show that background color contrast, item size, position, and card clarity have a strong influence on agents' actions, whereas font styling, text color, and item image clarity exhibit minor effects.
Hierarchical Bayesian Model for Gene Deconvolution and Functional Analysis in Human Endometrium Across the Menstrual Cycle
Oct 31, 2025Bulk tissue RNA sequencing of heterogeneous samples provides averaged gene expression profiles, obscuring cell type-specific dynamics. To address this, we present a probabilistic hierarchical Bayesian model that deconvolves bulk RNA-seq data into constituent cell-type expression profiles and proportions, leveraging a high-resolution single-cell reference. We apply our model to human endometrial tissue across the menstrual cycle, a context characterized by dramatic hormone-driven cellular composition changes. Our extended framework provides a principled inference of cell type proportions and cell-specific gene expression changes across cycle phases. We demonstrate the model's structure, priors, and inference strategy in detail, and we validate its performance with simulations and comparisons to existing methods. The results reveal dynamic shifts in epithelial, stromal, and immune cell fractions between menstrual phases, and identify cell-type-specific differential gene expression associated with endometrial function (e.g., decidualization markers in stromal cells during the secretory phase). We further conduct robustness tests and show that our Bayesian approach is resilient to reference mismatches and noise. Finally, we discuss the biological significance of our findings, potential clinical implications for fertility and endometrial disorders, and future directions, including integration of spatial transcriptomics.
Integrating Ontologies with Large Language Models for Enhanced Control Systems in Chemical Engineering
Oct 30, 2025This work presents an ontology-integrated large language model (LLM) framework for chemical engineering that unites structured domain knowledge with generative reasoning. The proposed pipeline aligns model training and inference with the COPE ontology through a sequence of data acquisition, semantic preprocessing, information extraction, and ontology mapping steps, producing templated question-answer pairs that guide fine-tuning. A control-focused decoding stage and citation gate enforce syntactic and factual grounding by constraining outputs to ontology-linked terms, while evaluation metrics quantify both linguistic quality and ontological accuracy. Feedback and future extensions, including semantic retrieval and iterative validation, further enhance the system's interpretability and reliability. This integration of symbolic structure and neural generation provides a transparent, auditable approach for applying LLMs to process control, safety analysis, and other critical engineering contexts.
POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025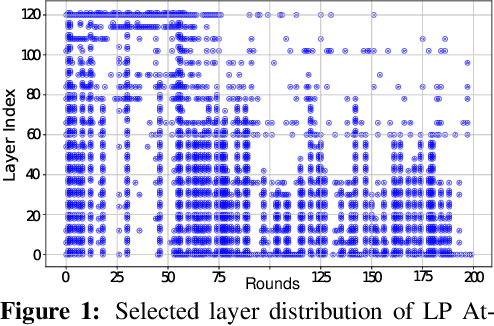



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Jun 20, 2024Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a "know but don't tell" phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
Points2Polygons: Context-Based Segmentation from Weak Labels Using Adversarial Networks
Jun 05, 2021
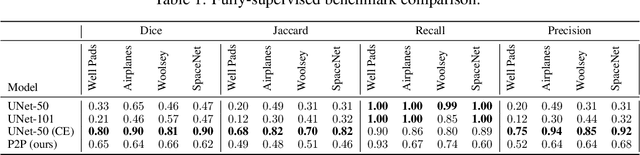
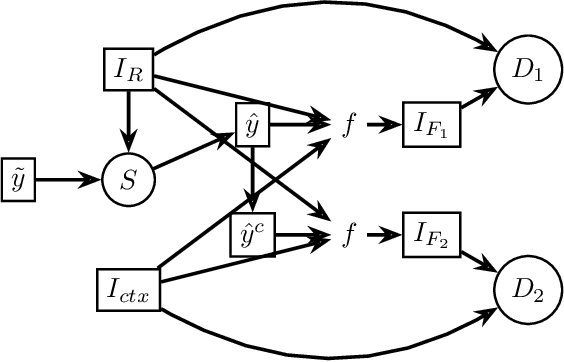
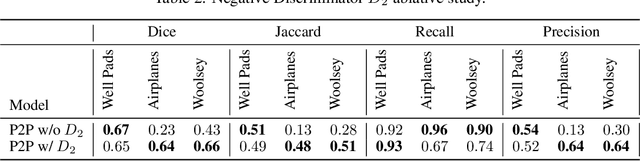
In applied image segmentation tasks, the ability to provide numerous and precise labels for training is paramount to the accuracy of the model at inference time. However, this overhead is often neglected, and recently proposed segmentation architectures rely heavily on the availability and fidelity of ground truth labels to achieve state-of-the-art accuracies. Failure to acknowledge the difficulty in creating adequate ground truths can lead to an over-reliance on pre-trained models or a lack of adoption in real-world applications. We introduce Points2Polygons (P2P), a model which makes use of contextual metric learning techniques that directly addresses this problem. Points2Polygons performs well against existing fully-supervised segmentation baselines with limited training data, despite using lightweight segmentation models (U-Net with a ResNet18 backbone) and having access to only weak labels in the form of object centroids and no pre-training. We demonstrate this on several different small but non-trivial datasets. We show that metric learning using contextual data provides key insights for self-supervised tasks in general, and allow segmentation models to easily generalize across traditionally label-intensive domains in computer vision.