 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generalization in Evolutionary Feature Construction for Symbolic Regression through Vicinal Jensen Gap Minimization
Feb 02, 2026Genetic programming-based feature construction has achieved significant success in recent years as an automated machine learning technique to enhance learning performance. However, overfitting remains a challenge that limits its broader applicability. To improve generalization, we prove that vicinal risk, estimated through noise perturbation or mixup-based data augmentation, is bounded by the sum of empirical risk and a regularization term-either finite difference or the vicinal Jensen gap. Leveraging this decomposition, we propose an evolutionary feature construction framework that jointly optimizes empirical risk and the vicinal Jensen gap to control overfitting. Since datasets may vary in noise levels, we develop a noise estimation strategy to dynamically adjust regularization strength. Furthermore, to mitigate manifold intrusion-where data augmentation may generate unrealistic samples that fall outside the data manifold-we propose a manifold intrusion detection mechanism. Experimental results on 58 datasets demonstrate the effectiveness of Jensen gap minimization compared to other complexity measures. Comparisons with 15 machine learning algorithms further indicate that genetic programming with the proposed overfitting control strategy achieves superior performance.
Towards Gold-Standard Depth Estimation for Tree Branches in UAV Forestry: Benchmarking Deep Stereo Matching Methods
Jan 27, 2026Autonomous UAV forestry operations require robust depth estimation with strong cross-domain generalization, yet existing evaluations focus on urban and indoor scenarios, leaving a critical gap for vegetation-dense environments. We present the first systematic zero-shot evaluation of eight stereo methods spanning iterative refinement, foundation model, diffusion-based, and 3D CNN paradigms. All methods use officially released pretrained weights (trained on Scene Flow) and are evaluated on four standard benchmarks (ETH3D, KITTI 2012/2015, Middlebury) plus a novel 5,313-pair Canterbury Tree Branches dataset ($1920 \times 1080$). Results reveal scene-dependent patterns: foundation models excel on structured scenes (BridgeDepth: 0.23 px on ETH3D; DEFOM: 4.65 px on Middlebury), while iterative methods show variable cross-benchmark performance (IGEV++: 0.36 px on ETH3D but 6.77 px on Middlebury; IGEV: 0.33 px on ETH3D but 4.99 px on Middlebury). Qualitative evaluation on the Tree Branches dataset establishes DEFOM as the gold-standard baseline for vegetation depth estimation, with superior cross-domain consistency (consistently ranking 1st-2nd across benchmarks, average rank 1.75). DEFOM predictions will serve as pseudo-ground-truth for future benchmarking.
Evo-TFS: Evolutionary Time-Frequency Domain-Based Synthetic Minority Oversampling Approach to Imbalanced Time Series Classification
Jan 03, 2026Time series classification is a fundamental machine learning task with broad real-world applications. Although many deep learning methods have proven effective in learning time-series data for classification, they were originally developed under the assumption of balanced data distributions. Once data distribution is uneven, these methods tend to ignore the minority class that is typically of higher practical significance. Oversampling methods have been designed to address this by generating minority-class samples, but their reliance on linear interpolation often hampers the preservation of temporal dynamics and the generation of diverse samples. Therefore, in this paper, we propose Evo-TFS, a novel evolutionary oversampling method that integrates both time- and frequency-domain characteristics. In Evo-TFS, strongly typed genetic programming is employed to evolve diverse, high-quality time series, guided by a fitness function that incorporates both time-domain and frequency-domain characteristics. Experiments conducted on imbalanced time series datasets demonstrate that Evo-TFS outperforms existing oversampling methods, significantly enhancing the performance of time-domain and frequency-domain classifiers.
Solver-Independent Automated Problem Formulation via LLMs for High-Cost Simulation-Driven Design
Dec 21, 2025In the high-cost simulation-driven design domain, translating ambiguous design requirements into a mathematical optimization formulation is a bottleneck for optimizing product performance. This process is time-consuming and heavily reliant on expert knowledge. While large language models (LLMs) offer potential for automating this task, existing approaches either suffer from poor formalization that fails to accurately align with the design intent or rely on solver feedback for data filtering, which is unavailable due to the high simulation costs. To address this challenge, we propose APF, a framework for solver-independent, automated problem formulation via LLMs designed to automatically convert engineers' natural language requirements into executable optimization models. The core of this framework is an innovative pipeline for automatically generating high-quality data, which overcomes the difficulty of constructing suitable fine-tuning datasets in the absence of high-cost solver feedback with the help of data generation and test instance annotation. The generated high-quality dataset is used to perform supervised fine-tuning on LLMs, significantly enhancing their ability to generate accurate and executable optimization problem formulations. Experimental results on antenna design demonstrate that APF significantly outperforms the existing methods in both the accuracy of requirement formalization and the quality of resulting radiation efficiency curves in meeting the design goals.
Symbolically Regressing Fish Biomass Spectral Data: A Linear Genetic Programming Method with Tunable Primitives
May 28, 2025Machine learning techniques play an important role in analyzing spectral data. The spectral data of fish biomass is useful in fish production, as it carries many important chemistry properties of fish meat. However, it is challenging for existing machine learning techniques to comprehensively discover hidden patterns from fish biomass spectral data since the spectral data often have a lot of noises while the training data are quite limited. To better analyze fish biomass spectral data, this paper models it as a symbolic regression problem and solves it by a linear genetic programming method with newly proposed tunable primitives. In the symbolic regression problem, linear genetic programming automatically synthesizes regression models based on the given primitives and training data. The tunable primitives further improve the approximation ability of the regression models by tuning their inherent coefficients. Our empirical results over ten fish biomass targets show that the proposed method improves the overall performance of fish biomass composition prediction. The synthesized regression models are compact and have good interpretability, which allow us to highlight useful features over the spectrum. Our further investigation also verifies the good generality of the proposed method across various spectral data treatments and other symbolic regression problems.
LLM-Meta-SR: Learning to Evolve Selection Operators for Symbolic Regression
May 24, 2025Large language models (LLMs) have revolutionized algorithm development, yet their application in symbolic regression, where algorithms automatically discover symbolic expressions from data, remains constrained and is typically designed manually by human experts. In this paper, we propose a learning-to-evolve framework that enables LLMs to automatically design selection operators for evolutionary symbolic regression algorithms. We first identify two key limitations in existing LLM-based algorithm evolution techniques: code bloat and a lack of semantic guidance. Bloat results in unnecessarily complex components, and the absence of semantic awareness can lead to ineffective exchange of useful code components, both of which can reduce the interpretability of the designed algorithm or hinder evolutionary learning progress. To address these issues, we enhance the LLM-based evolution framework for meta symbolic regression with two key innovations: bloat control and a complementary, semantics-aware selection operator. Additionally, we embed domain knowledge into the prompt, enabling the LLM to generate more effective and contextually relevant selection operators. Our experimental results on symbolic regression benchmarks show that LLMs can devise selection operators that outperform nine expert-designed baselines, achieving state-of-the-art performance. This demonstrates that LLMs can exceed expert-level algorithm design for symbolic regression.
Automated Detection of Salvin's Albatrosses: Improving Deep Learning Tools for Aerial Wildlife Surveys
May 15, 2025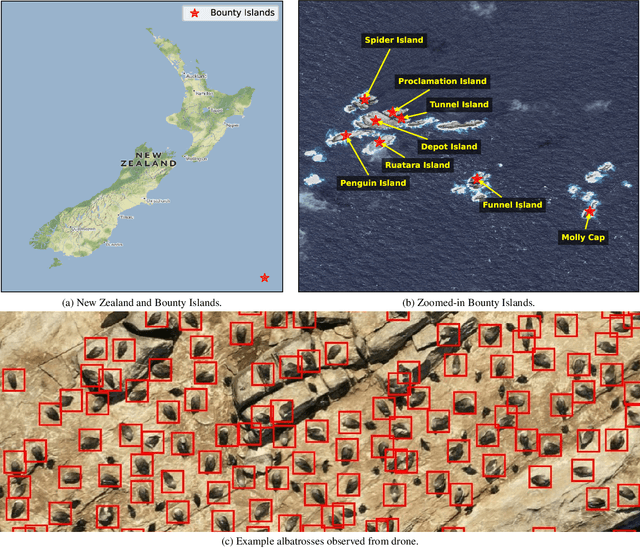


Recent advancements in deep learning and aerial imaging have transformed wildlife monitoring, enabling researchers to survey wildlife populations at unprecedented scales. Unmanned Aerial Vehicles (UAVs) provide a cost-effective means of capturing high-resolution imagery, particularly for monitoring densely populated seabird colonies. In this study, we assess the performance of a general-purpose avian detection model, BirdDetector, in estimating the breeding population of Salvin's albatross (Thalassarche salvini) on the Bounty Islands, New Zealand. Using drone-derived imagery, we evaluate the model's effectiveness in both zero-shot and fine-tuned settings, incorporating enhanced inference techniques and stronger augmentation methods. Our findings indicate that while applying the model in a zero-shot setting offers a strong baseline, fine-tuning with annotations from the target domain and stronger image augmentation leads to marked improvements in detection accuracy. These results highlight the potential of leveraging pre-trained deep-learning models for species-specific monitoring in remote and challenging environments.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Federated Unlearning Model Recovery in Data with Skewed Label Distributions
Dec 18, 2024

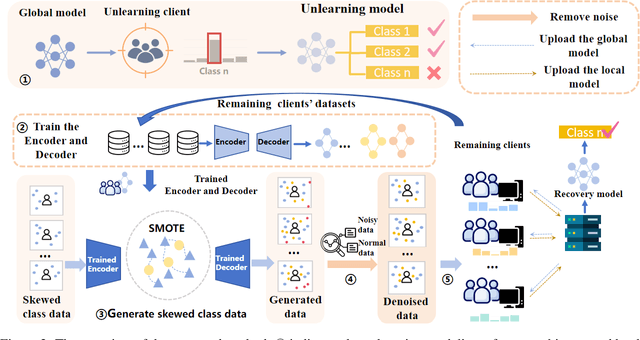

In federated learning, federated unlearning is a technique that provides clients with a rollback mechanism that allows them to withdraw their data contribution without training from scratch. However, existing research has not considered scenarios with skewed label distributions. Unfortunately, the unlearning of a client with skewed data usually results in biased models and makes it difficult to deliver high-quality service, complicating the recovery process. This paper proposes a recovery method of federated unlearning with skewed label distributions. Specifically, we first adopt a strategy that incorporates oversampling with deep learning to supplement the skewed class data for clients to perform recovery training, therefore enhancing the completeness of their local datasets. Afterward, a density-based denoising method is applied to remove noise from the generated data, further improving the quality of the remaining clients' datasets. Finally, all the remaining clients leverage the enhanced local datasets and engage in iterative training to effectively restore the performance of the unlearning model. Extensive evaluations on commonly used federated learning datasets with varying degrees of skewness show that our method outperforms baseline methods in restoring the performance of the unlearning model, particularly regarding accuracy on the skewed class.
EvoSampling: A Granular Ball-based Evolutionary Hybrid Sampling with Knowledge Transfer for Imbalanced Learning
Dec 12, 2024



Class imbalance would lead to biased classifiers that favor the majority class and disadvantage the minority class. Unfortunately, from a practical perspective, the minority class is of importance in many real-life applications. Hybrid sampling methods address this by oversampling the minority class to increase the number of its instances, followed by undersampling to remove low-quality instances. However, most existing sampling methods face difficulties in generating diverse high-quality instances and often fail to remove noise or low-quality instances on a larger scale effectively. This paper therefore proposes an evolutionary multi-granularity hybrid sampling method, called EvoSampling. During the oversampling process, genetic programming (GP) is used with multi-task learning to effectively and efficiently generate diverse high-quality instances. During the undersampling process, we develop a granular ball-based undersampling method that removes noise in a multi-granular fashion, thereby enhancing data quality. Experiments on 20 imbalanced datasets demonstrate that EvoSampling effectively enhances the performance of various classification algorithms by providing better datasets than existing sampling methods. Besides, ablation studies further indicate that allowing knowledge transfer accelerates the GP's evolutionary learning process.