 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Generative Multi-Task Representation Learning Approach for Predicting Postoperative Complications in Cardiac Surgery Patients
Dec 02, 2024


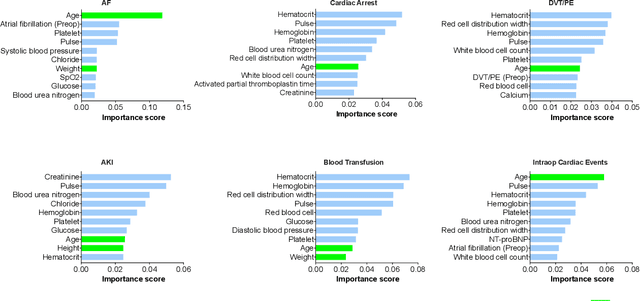
Early detection of surgical complications allows for timely therapy and proactive risk mitigation. Machine learning (ML) can be leveraged to identify and predict patient risks for postoperative complications. We developed and validated the effectiveness of predicting postoperative complications using a novel surgical Variational Autoencoder (surgVAE) that uncovers intrinsic patterns via cross-task and cross-cohort presentation learning. This retrospective cohort study used data from the electronic health records of adult surgical patients over four years (2018 - 2021). Six key postoperative complications for cardiac surgery were assessed: acute kidney injury, atrial fibrillation, cardiac arrest, deep vein thrombosis or pulmonary embolism, blood transfusion, and other intraoperative cardiac events. We compared prediction performances of surgVAE against widely-used ML models and advanced representation learning and generative models under 5-fold cross-validation. 89,246 surgeries (49% male, median (IQR) age: 57 (45-69)) were included, with 6,502 in the targeted cardiac surgery cohort (61% male, median (IQR) age: 60 (53-70)). surgVAE demonstrated superior performance over existing ML solutions across all postoperative complications of cardiac surgery patients, achieving macro-averaged AUPRC of 0.409 and macro-averaged AUROC of 0.831, which were 3.4% and 3.7% higher, respectively, than the best alternative method (by AUPRC scores). Model interpretation using Integrated Gradients highlighted key risk factors based on preoperative variable importance. surgVAE showed excellent discriminatory performance for predicting postoperative complications and addressing the challenges of data complexity, small cohort sizes, and low-frequency positive events. surgVAE enables data-driven predictions of patient risks and prognosis while enhancing the interpretability of patient risk profiles.
Multimodal hierarchical multi-task deep learning framework for jointly predicting and explaining Alzheimer disease progression
Apr 04, 2024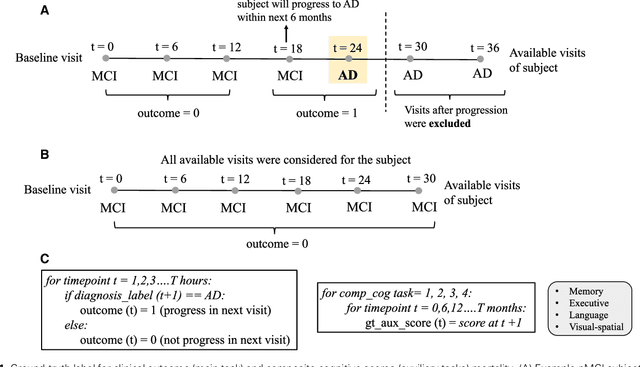
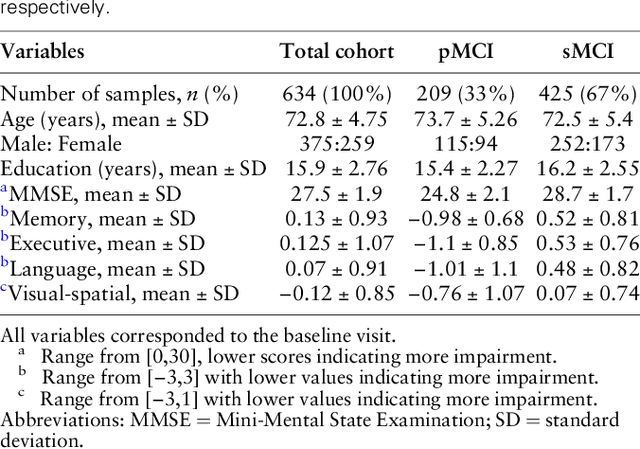
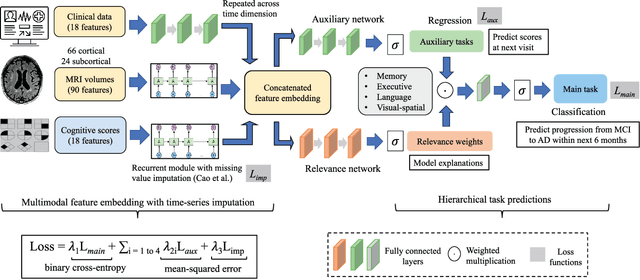
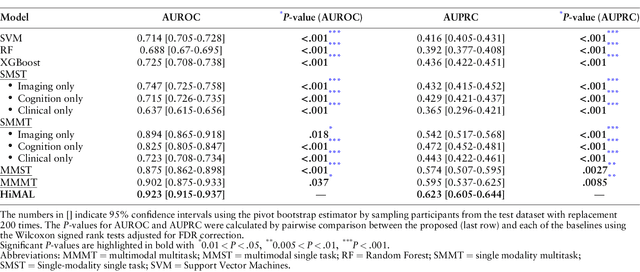
Early identification of Mild Cognitive Impairment (MCI) subjects who will eventually progress to Alzheimer Disease (AD) is challenging. Existing deep learning models are mostly single-modality single-task models predicting risk of disease progression at a fixed timepoint. We proposed a multimodal hierarchical multi-task learning approach which can monitor the risk of disease progression at each timepoint of the visit trajectory. Longitudinal visit data from multiple modalities (MRI, cognition, and clinical data) were collected from MCI individuals of the Alzheimer Disease Neuroimaging Initiative (ADNI) dataset. Our hierarchical model predicted at every timepoint a set of neuropsychological composite cognitive function scores as auxiliary tasks and used the forecasted scores at every timepoint to predict the future risk of disease. Relevance weights for each composite function provided explanations about potential factors for disease progression. Our proposed model performed better than state-of-the-art baselines in predicting AD progression risk and the composite scores. Ablation study on the number of modalities demonstrated that imaging and cognition data contributed most towards the outcome. Model explanations at each timepoint can inform clinicians 6 months in advance the potential cognitive function decline that can lead to progression to AD in future. Our model monitored their risk of AD progression every 6 months throughout the visit trajectory of individuals. The hierarchical learning of auxiliary tasks allowed better optimization and allowed longitudinal explanations for the outcome. Our framework is flexible with the number of input modalities and the selection of auxiliary tasks and hence can be generalized to other clinical problems too.
Prescribing Large Language Models for Perioperative Care: What's The Right Dose for Pre-trained Models?
Feb 28, 2024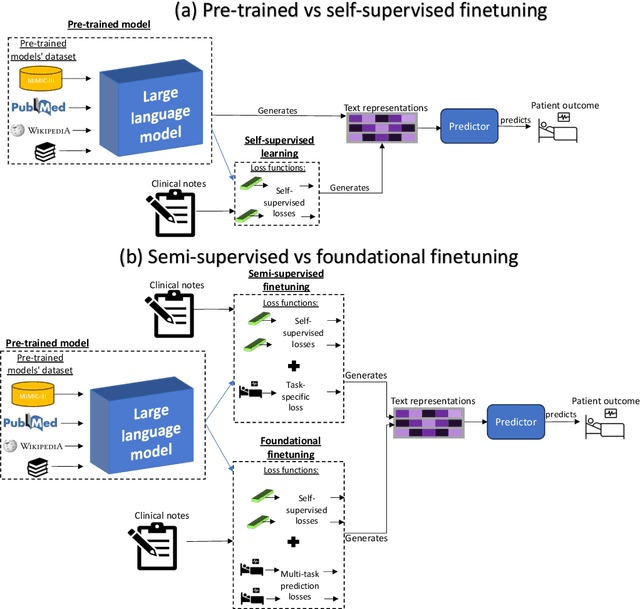



Postoperative risk predictions can inform effective perioperative care management and planning. We aimed to assess whether clinical large language models (LLMs) can predict postoperative risks using clinical texts with various training strategies. The main cohort involved 84,875 records from Barnes Jewish Hospital (BJH) system between 2018 and 2021. Methods were replicated on Beth Israel Deaconess's MIMIC dataset. Both studies had mean duration of follow-up based on the length of postoperative ICU stay less than 7 days. For the BJH dataset, outcomes included 30-day mortality, pulmonary embolism (PE) and pneumonia. Three domain adaptation and finetuning strategies were implemented for BioGPT, ClinicalBERT and BioClinicalBERT: self-supervised objectives; incorporating labels with semi-supervised fine-tuning; and foundational modelling through multi-task learning. Model performance was compared using the area under the receiver operating characteristic curve (AUROC) and the area under the precision recall curve (AUPRC) for classification tasks, and mean squared error (MSE) and R2 for regression tasks. Pre-trained LLMs outperformed traditional word embeddings, with absolute maximal gains of 38.3% for AUROC and 14% for AUPRC. Adapting models further improved performance: (1) self-supervised finetuning by 3.2% for AUROC and 1.5% for AUPRC; (2) semi-supervised finetuning by 1.8% for AUROC and 2% for AUPRC, compared to self-supervised finetuning; (3) foundational modelling by 3.6% for AUROC and 2.6% for AUPRC, compared to self-supervised finetuning. Pre-trained clinical LLMs offer opportunities for postoperative risk predictions in unforeseen data, with peaks in foundational models indicating the potential of task-agnostic learning towards the generalizability of LLMs in perioperative care.
Autoregressive Language Models For Estimating the Entropy of Epic EHR Audit Logs
Nov 26, 2023



EHR audit logs are a highly granular stream of events that capture clinician activities, and is a significant area of interest for research in characterizing clinician workflow on the electronic health record (EHR). Existing techniques to measure the complexity of workflow through EHR audit logs (audit logs) involve time- or frequency-based cross-sectional aggregations that are unable to capture the full complexity of a EHR session. We briefly evaluate the usage of transformer-based tabular language model (tabular LM) in measuring the entropy or disorderedness of action sequences within workflow and release the evaluated models publicly.
Utilizing Semantic Textual Similarity for Clinical Survey Data Feature Selection
Aug 19, 2023
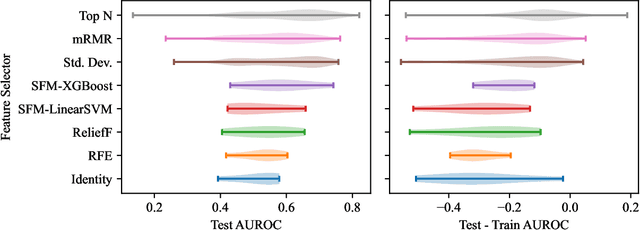
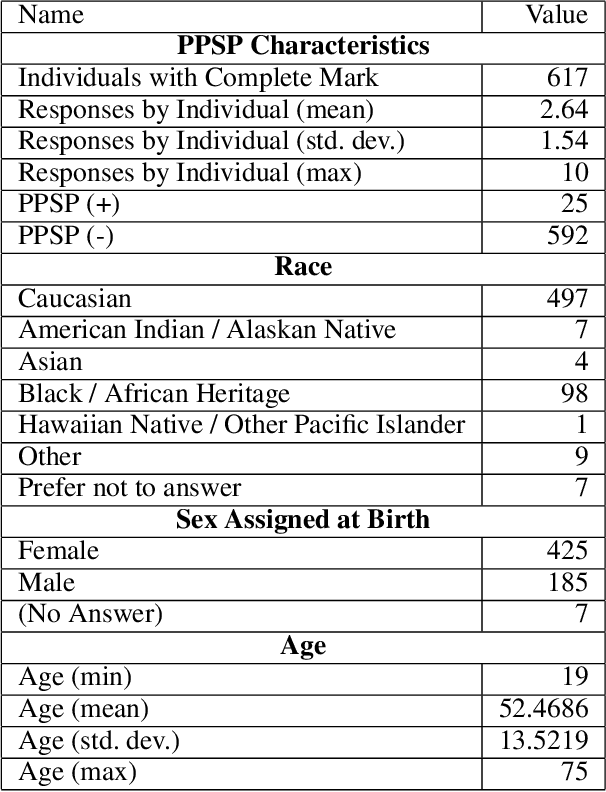
Survey data can contain a high number of features while having a comparatively low quantity of examples. Machine learning models that attempt to predict outcomes from survey data under these conditions can overfit and result in poor generalizability. One remedy to this issue is feature selection, which attempts to select an optimal subset of features to learn upon. A relatively unexplored source of information in the feature selection process is the usage of textual names of features, which may be semantically indicative of which features are relevant to a target outcome. The relationships between feature names and target names can be evaluated using language models (LMs) to produce semantic textual similarity (STS) scores, which can then be used to select features. We examine the performance using STS to select features directly and in the minimal-redundancy-maximal-relevance (mRMR) algorithm. The performance of STS as a feature selection metric is evaluated against preliminary survey data collected as a part of a clinical study on persistent post-surgical pain (PPSP). The results suggest that features selected with STS can result in higher performance models compared to traditional feature selection algorithms.
HiPAL: A Deep Framework for Physician Burnout Prediction Using Activity Logs in Electronic Health Records
May 24, 2022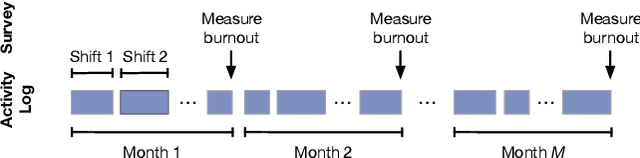
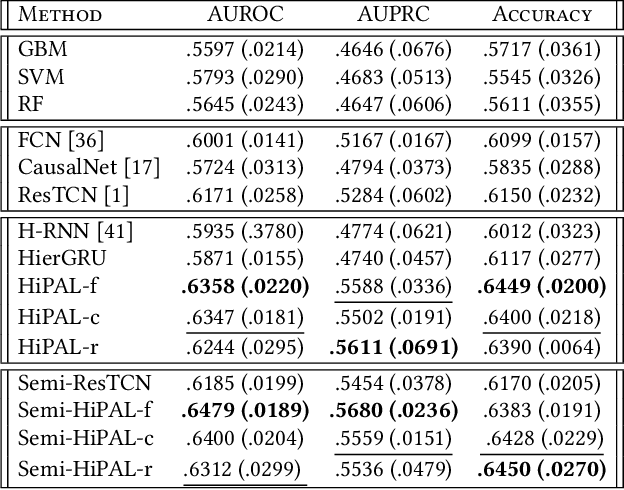

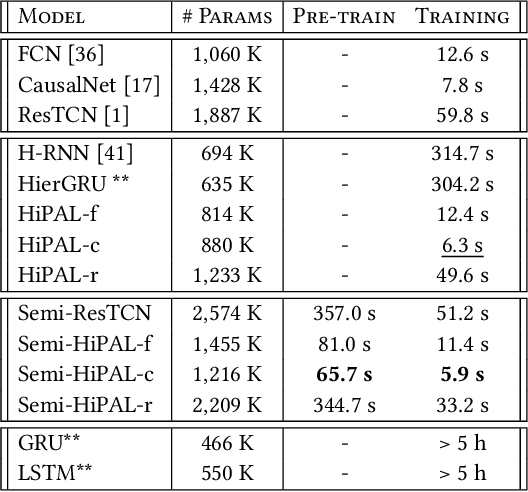
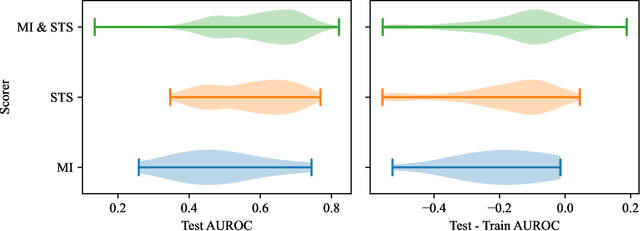
Burnout is a significant public health concern affecting nearly half of the healthcare workforce. This paper presents the first end-to-end deep learning framework for predicting physician burnout based on clinician activity logs, digital traces of their work activities, available in any electronic health record (EHR) system. In contrast to prior approaches that exclusively relied on surveys for burnout measurement, our framework directly learns deep workload representations from large-scale clinician activity logs to predict burnout. We propose the Hierarchical burnout Prediction based on Activity Logs (HiPAL), featuring a pre-trained time-dependent activity embedding mechanism tailored for activity logs and a hierarchical predictive model, which mirrors the natural hierarchical structure of clinician activity logs and captures physician's evolving workload patterns at both short-term and long-term levels. To utilize the large amount of unlabeled activity logs, we propose a semi-supervised framework that learns to transfer knowledge extracted from unlabeled clinician activities to the HiPAL-based prediction model. The experiment on over 15 million clinician activity logs collected from the EHR at a large academic medical center demonstrates the advantages of our proposed framework in predictive performance of physician burnout and training efficiency over state of the art approaches.
Predicting Intraoperative Hypoxemia with Joint Sequence Autoencoder Networks
May 19, 2021
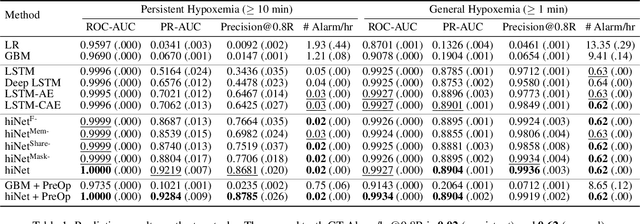
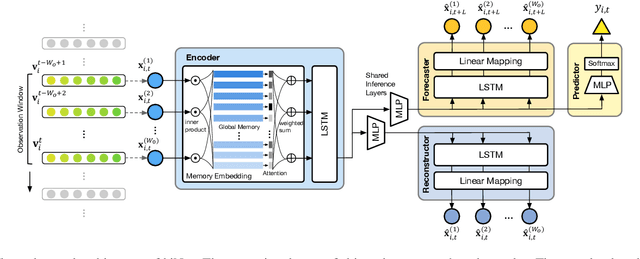
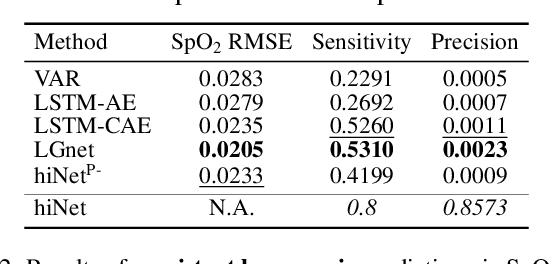
We present an end-to-end model using streaming physiological time series to accurately predict near-term risk for hypoxemia, a rare, but life-threatening condition known to cause serious patient harm during surgery. Our proposed model makes inference on both hypoxemia outcomes and future input sequences, enabled by a joint sequence autoencoder that simultaneously optimizes a discriminative decoder for label prediction, and two auxiliary decoders trained for data reconstruction and forecast, which seamlessly learns future-indicative latent representation. All decoders share a memory-based encoder that helps capture the global dynamics of patient data. In a large surgical cohort of 73,536 surgeries at a major academic medical center, our model outperforms all baselines and gives a large performance gain over the state-of-the-art hypoxemia prediction system. With a high sensitivity cutoff at 80%, it presents 99.36% precision in predicting hypoxemia and 86.81% precision in predicting the much more severe and rare hypoxemic condition, persistent hypoxemia. With exceptionally low rate of false alarms, our proposed model is promising in improving clinical decision making and easing burden on the health system.