 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrescribing Large Language Models for Perioperative Care: What's The Right Dose for Pre-trained Models?
Paper and Code
Feb 28, 2024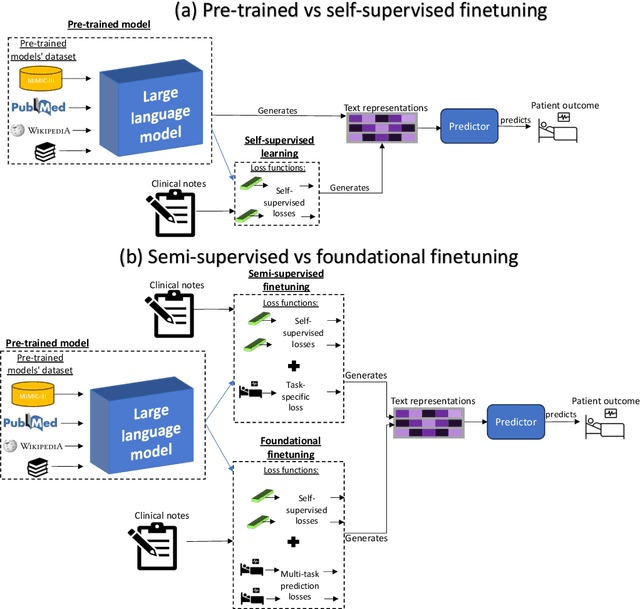



Postoperative risk predictions can inform effective perioperative care management and planning. We aimed to assess whether clinical large language models (LLMs) can predict postoperative risks using clinical texts with various training strategies. The main cohort involved 84,875 records from Barnes Jewish Hospital (BJH) system between 2018 and 2021. Methods were replicated on Beth Israel Deaconess's MIMIC dataset. Both studies had mean duration of follow-up based on the length of postoperative ICU stay less than 7 days. For the BJH dataset, outcomes included 30-day mortality, pulmonary embolism (PE) and pneumonia. Three domain adaptation and finetuning strategies were implemented for BioGPT, ClinicalBERT and BioClinicalBERT: self-supervised objectives; incorporating labels with semi-supervised fine-tuning; and foundational modelling through multi-task learning. Model performance was compared using the area under the receiver operating characteristic curve (AUROC) and the area under the precision recall curve (AUPRC) for classification tasks, and mean squared error (MSE) and R2 for regression tasks. Pre-trained LLMs outperformed traditional word embeddings, with absolute maximal gains of 38.3% for AUROC and 14% for AUPRC. Adapting models further improved performance: (1) self-supervised finetuning by 3.2% for AUROC and 1.5% for AUPRC; (2) semi-supervised finetuning by 1.8% for AUROC and 2% for AUPRC, compared to self-supervised finetuning; (3) foundational modelling by 3.6% for AUROC and 2.6% for AUPRC, compared to self-supervised finetuning. Pre-trained clinical LLMs offer opportunities for postoperative risk predictions in unforeseen data, with peaks in foundational models indicating the potential of task-agnostic learning towards the generalizability of LLMs in perioperative care.